

Microsoftは、「Phi-3」と名付けられた、新しい軽量言語モデルを発表した。このモデルは、OpenAIのGPT-4 Turboのような大規模言語モデル(LLM)よりもシンプルで軽量に動作するため、スマートフォンのようなデバイス上でローカルに実行する事も可能な上、ChatGPTの無料版で用いられているGPT-3.5と同等の性能を発揮するとの事だ。
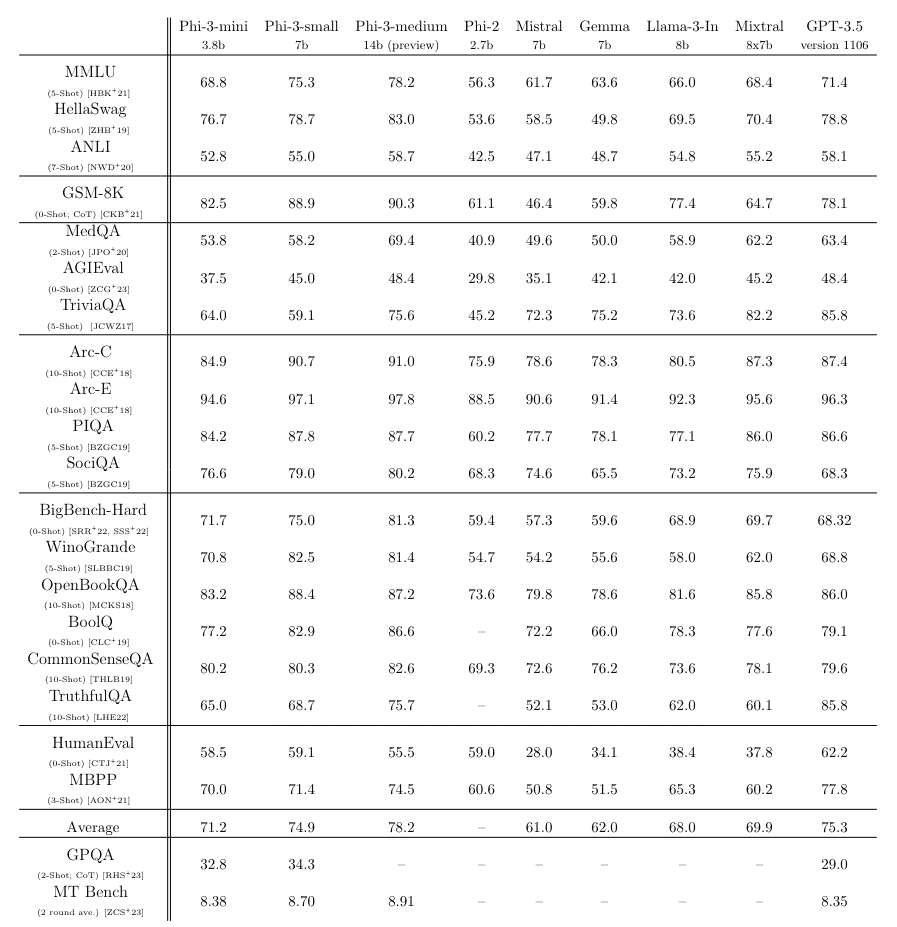
Phi-3と言う事で、この言語モデルは、2023年12月にMicrosoftが発表した前身のPhi-2の後継となるモデルだ。Phi-3は3兆3,000億個のトークンでトレーニングされた38億のパラメータサイズと言う事で、Phi-2が27億パラメーターだった事から増加が見られる。とは言え、このパラメータサイズは、GPT-3.5(一説では3,000億以上とも)等に比べると格段にコンパクトなものだ。にもかかわらず、MMLU言語理解ベンチマークで69%、MTベンチマークで8.38ポイントを達成している。
この小さなサイズのおかげで、Phi-3はわずか1.8GBのメモリーを搭載した標準的なスマートフォンでもローカルに実行することができ、4ビットに量子化され、A16チップを搭載したiPhone 14で毎秒12トークン以上を達成しているとのことだ。
高品質の学習データで学習データを最大限に活用
Microsoftによると、Phi-3のパフォーマンスの秘密は、“的を絞ったアプローチ”に基づくトレーニングデータセットにあるという。これは、「教育レベル」のフィルタリングが施されたWebデータと、LLMで生成された合成データで構成され、前身のPhi-2とPhi-1で使用されたトレーニング方法をベースにしている。
Microsoftは、この性能はトレーニングデータセットの最適化のみによって達成されたと強調している。これは、スポーツのスコアなどの情報でWebデータを「浪費」する代わりに、知識と推論スキルに焦点を当てることで、データセットをコンパクトなモデルの「最適データ」に近づけたとのことだ。
また、Phi-3は、Phi-1から学んだことの上に構築されていると、Microsoftは付け加えている。Phi-1がコーディングに重点を置き、Phi-2が推論に力を入れ始め、Phi-3ではその両面で優れているとMicrosoftは述べている。
事前学習の第一段階では、主にWebデータを使用し、モデルに一般的な知識と言語理解を身につけさせる。第二の学習段階では、高度にフィルタリングされた高品質なWebデータと、選択された合成データを組み合わせ、論理学やニッチなアプリケーションなどの特定分野におけるモデルの性能を最適化する。
Phiモデルによって、Microsoftは高品質でありながら、より効率的でコスト効率の高いAIモデルを実現することを目指している。特にMicrosoftは、WindowsやOffice製品、検索などのAIを拡張し、生成AIをビジネスモデルにするために、コスト効率の高いモデルを必要としている。
多くのベンチマークでPhi-3がLlama 3を上回る
70億のパラメータを持つphi-3-smallと140億のパラメータを持つphi-3-mediumは、どちらも4.8兆トークンで学習され、同クラスモデルに関するベンチマークではphi-3-miniと同様の性能を発揮する。
MMLUベンチマークでは75%と78%、MTベンチマークでは8.7ポイントと8.9ポイントを達成している。これは、Metaが最近リリースした700億パラメータのLlama 3のような、はるかに大きなモデルに遠く及ばない物の、ほとんどのケースで同クラスのモデルを上回っている(Phi 3 7b vs. Llama 3 8b)。
しかし、アプリケーションで認識される性能とベンチマーク結果は必ずしも一致しない。このモデルがオープンソースコミュニティにどの程度採用されるかは、まだ未知数だ。
Microsoftは、phi-3-miniの事実知識に対する能力が、TriviaQAベンチマークなどで大型モデルに比べて低いことを弱点として挙げている。これは、GPT-4や他のLLMのように、インターネット全体について学習したLLMとPhi-3のような小さなモデルでは、得られる答えの種類に大きな違いがあるからだ。しかし、こうした欠点は検索エンジンを統合することで補うことができるだろう。
また、現在のところ、言語はほとんど英語に限定されており、幻覚、偏りの増幅、不適切なコンテンツの生成など、ほとんどのLLMに内在する問題は、Phi-3にも見られる。
「これらの課題に完全に対処するには、大きな課題が残されている」と、研究者らは論文の中で述べている。
安全性に関しては、Microsoftは、アライメント・トレーニング、レッド・チーミング、自動テスト、独立したレビューなど、多段階のアプローチをとっているという。これにより、潜在的に有害な反応の数は大幅に減少したという。
Microsoft社によると、Phi 3は、オープンソースコミュニティがPhi 3から可能な限り恩恵を受けられるように、MetaのLlamaモデルと同様のブロック構造と同じトークナイザーを使用している。つまり、Llama 2モデル・ファミリー用に開発されたパッケージはすべて、Phi-3-miniに直接適合させることができる。
論文
参考文献
研究の要旨
phi-3-miniは3.3兆個のトークンで訓練された38億パラメータの言語モデルであり、学術的ベンチマークと内部テストの両方で測定された総合的な性能は、携帯電話上で展開できるほど小さいにもかかわらず、Mixtral 8x7BやGPT-3.5のようなモデルに匹敵します(例えば、phi-3-miniはMMLUで69%、MT-benchで8.38を達成しています)。この革新的なモデルは学習用データセットにあり、phi-2に使用されたものをスケールアップしたもので、大きくフィルタリングされたウェブデータと合成データから構成されています。モデルはまた、頑健性、安全性、チャット形式のためにさらに調整されています。我々はまた、phi-3-smallとphi-3-mediumと呼ばれる4.8Tトークンのために訓練された7Bと14Bのモデルで、いくつかの初期パラメータスケーリング結果を提供し、両方がphi-3-miniよりも有意に有能である(例えば、それぞれMMLUで75%と78%、MT-benchで8.7と8.9)。








コメント