

Googleのオープンソース大規模言語モデル「Gemma」ファミリーに、コード補完とより効率的な推論のための新しいモデルが追加された。Gemmaへのこれらの変更は、今年2月に初めてリリースされて以来の大きな拡張となる。
追加されたのは、「CodeGemma」と「RecurrentGemma」の2モデルだ。
コード補完とコード生成のための「CodeGemma」
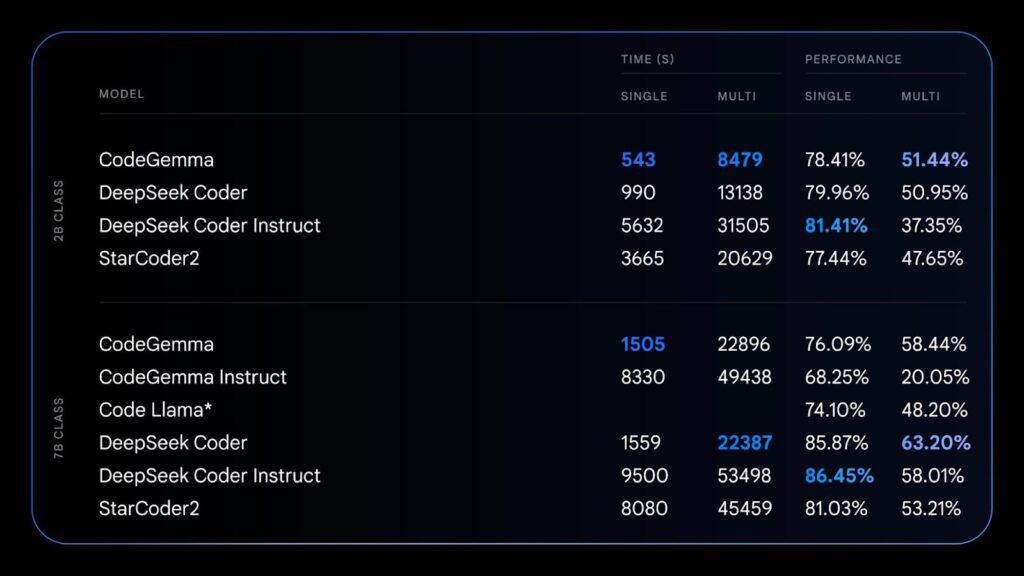
CodeGemmaは、プログラマーのコーディングを支援するためのモデルであり、パラメータサイズによって3つのバージョンが用意されている。
- コードを完成させ、新しいコードを生成するための、事前に訓練された70億パラメータモデル
- コードについてのチャットや指示に従うために最適化された70億のパラメータモデル
- ローカルデバイスでの高速なコード補完のための、事前に訓練された20億パラメータモデル
CodeGemmaは、Web文書、数学、コードから得られた5,000億トークンのデータでトレーニングされている。Python、JavaScript、Java、その他の一般的なプログラミング言語で、正しく意味のあるコードを書くことができる。Googleによると、CodeGemmaは開発者が反復的なコードを書くのを減らし、より難しいタスクに集中できるようにするためのものだという。
より効率的な推論を提供する「ReccurentGemma」
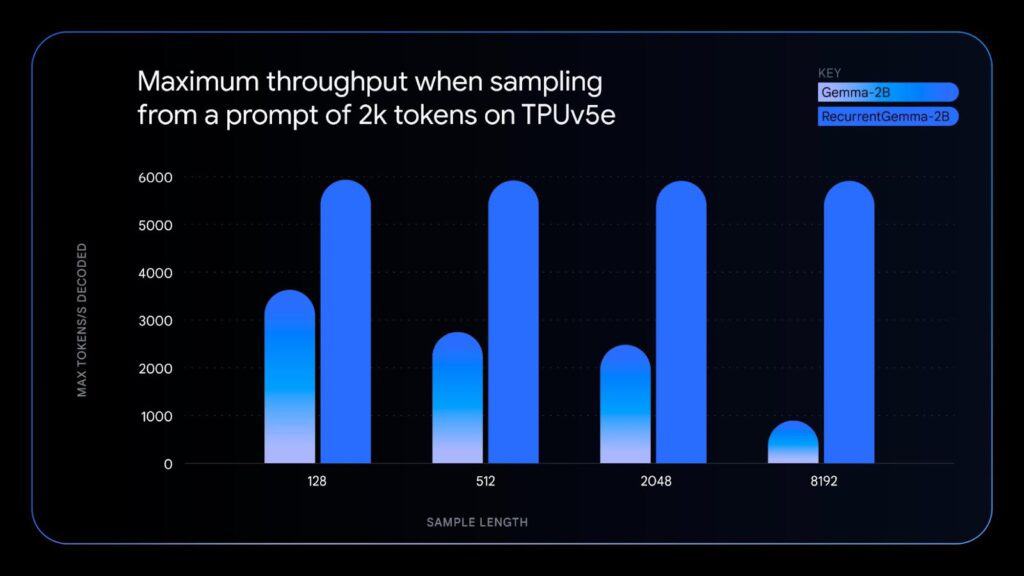
もう一つのRecurrentGemmaは、リカレントニューラルネットワークとローカルアテンションを使用し、よりメモリ効率を高めたモデルだ。これは20億パラメーターのGemmaモデルと同様の性能を持つが、以下のようないくつかの利点がある:
- シングルGPUやCPUのようなメモリが限られたデバイス上で、より長いテキストを生成するために、より少ないメモリを使用する。
- より大きなバッチサイズを使用し、1秒あたりより多くの単語を生成することで、より高速にテキストを処理できる。
- 非変換モデルでも十分な性能を発揮できることを示すことで、AI研究を前進させる。
これらに加え、Googleは、オリジナルのGemmaモデルをバージョン1.1に更新し、パフォーマンスの向上、バグの修正、より柔軟な利用条件の追加を行った。
新しいモデルは現在、Kaggle、NVIDIA NIM API、Hugging Face、Vertex AI Model Gardenで利用可能だ。これらは、JAX、PyTorch、Hugging Face Transformers、Gemma.cpp、Keras、NVIDIA NeMo、TensorRT-LLM、Optimum-NVIDIA、MediaPipeを含むツールで動作する。
Sources
- Google for Developers: Gemma Family Expands with Models Tailored for Developers and Researchers
- Kaggle:






コメント