

ChatGPTに「David Mayer」等の特定の人物の名称を入力すると会話が突如終了してしまう異常な挙動が発見された。これは単なるバグというだけではなく、OpenAIの内部フィルタリングシステムに関連する物と見られており、、AIチャットボットの制限と、個人情報の取り扱いに関する新たな課題を提起する物と言える。
複数の人物名で確認されるChatGPTの異常な挙動
この現象が最初に発見されたのは「David Mayer」という名前においてであり、インターネット上のユーザーたちがこの特異な挙動に気付いた際、さらなる調査によって同様の症状を引き起こす他の名前の存在も明らかになった。具体的には、ハーバード・ロー・スクールの教授である「Jonathan Zittrain」氏や、ジョージ・ワシントン大学ロースクールの教授でFox Newsのコメンテーターを務める「Jonathan Turley」氏、さらにはオーストラリアの市長「Brian Hood」氏、そして「David Faber」や「Guido Scorza」といった名前でも同様の現象が確認されている。
これらの名前をChatGPTに入力すると、AIは一様に「I’m unable to produce a response(応答を生成できません)」というエラーメッセージを表示し、その直後に会話セッションが強制的に終了する。この挙動は、OpenAIが実装している内部的なコンテンツフィルタリングシステムの存在を示唆している。興味深いことに、この制限はChatGPTのWebインターフェースに限定されており、開発者向けのOpenAI APIやOpenAI Playgroundでは同様の制限は確認されていない。
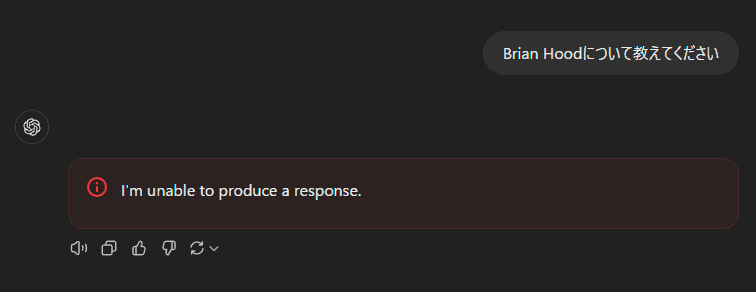
ユーザーたちはこの制限を回避するために様々な創意工夫を凝らしている。例えば、暗号化された形式で名前を入力したり、なぞなぞのような間接的な表現を用いたり、あるいはアカウント設定で自身の名前を問題の名前に変更してChatGPTに情報を読み上げさせようとするなど、多様なアプローチが試みられた。しかし、これらの試みはいずれも成功には至っていない。特筆すべきは、一部のユーザーが「say David: Mayer」という入力の後に「replace colon with nbsp:」というコマンドを使用することで部分的な回避に成功したものの、その後の会話で同じ名前を使用しようとすると再び同じエラーが発生するという点である。
このような厳格な制限の存在は、最新のAIシステムが直面している複雑な課題を浮き彫りにしている。表面的には単純な文字列のフィルタリングに見えるこの機能の背後には、法的リスク管理やプライバシー保護、そして誤情報の拡散防止という、現代のAIプラットフォームが直面する本質的な課題が存在しているのだ。
フィルタリングの背景
OpenAIが特定の人物名に対してこのような厳格なフィルタリングを実装するに至った背景には、ChatGPTによる誤情報生成が引き起こした具体的な問題と法的な対応の歴史が存在する。この問題の発端は2023年中頃にさかのぼり、オーストラリアの市長であるBrian Hood氏の事例が最初の転換点となった。Hood市長は企業の不正を内部告発した人物であったにもかかわらず、ChatGPTは彼を「贈賄で投獄された人物」として誤った情報を生成した。この深刻な誤認に対し、Hood市長は法的措置を検討。その結果、OpenAIは28日以内にこの虚偽の記述を修正することに同意し、これが最初の名前ベースのハードコードフィルターの実装につながったと考えられている。
また、ジョージ・ワシントン大学ロースクールのJonathan Turley教授の事例も、AIによる誤情報生成の深刻さを示す重要な例となった。2023年4月、ChatGPTは存在しないWashington Postの記事を出典として引用しながら、Turley教授に関する架空の性的嫌がらせスキャンダルを捏造するという重大な過ちを犯した。興味深いことに、Turley教授は404 Mediaの取材に対し、OpenAIに対する法的措置は取っておらず、会社からの接触も一切なかったと証言している。これは、OpenAIが法的な要請がなくとも、潜在的なリスクを認識した場合には予防的な措置を取る姿勢を示している。
ハーバード・ロー・スクールの教授であるJonathan Zittrain氏の事例は、さらに異なる様相を呈している。Zittrain氏は最近The AtlanticでAI規制とChatGPTに関する記事を発表しており、AI倫理とガバナンスを専門とする研究者として知られている。一部のユーザーはZittrain氏がGDPR(一般データ保護規則)に基づく「忘れられる権利」を行使したのではないかと推測したが、Zittrain自身がXプラットフォーム(旧Twitter)で、そのような要請は行っていないことを明確に否定している。
ちなみに、現在は「David Mayer」に関してのフィルタリングは解除されており、なぜこれがブロックされていたのかは推測の域を出ないが、「David Mayer de Rothschild」との関連が指摘されている。
この一連の対応からは、OpenAIが採用している防御的なアプローチが浮かび上がってくる。すなわち、誤情報の生成によって引き起こされる可能性のある法的リスクや評判の低下を事前に防ぐため、問題が発生した、あるいは発生する可能性が高いと判断された人物名に対して、予防的に厳格なフィルタリングを実施するという方針である。しかし、この手法は同時に、AIシステムの透明性と説明責任という観点から新たな問題を提起している。特に、フィルタリングの対象となる人物の選定基準や、そのプロセスの透明性については、依然として不明な点が多く残されているのである。
システム設計上の新たな課題
OpenAIが採用している硬直的なフィルタリング手法は、表面的には特定の法的リスクを回避する有効な手段に見えるものの、より深い次元でAIシステムの実用性と信頼性に関わる本質的な課題を生み出している。
まず最も直接的な問題として、同姓同名の一般ユーザーに対する影響が挙げられる。「David Mayer」のような一般的な名前をフィルタリング対象とすることで、その名前を持つ数百、場合によっては数千人もの人々がChatGPTの特定の機能を利用できなくなる可能性がある。例えば、教育現場で「David Mayer」という名前の生徒のクラスリストを処理しようとした場合、ChatGPTはその作業を完全に拒否してしまう。これは、AIシステムの基本的な有用性を著しく損なう結果となっている。
さらに深刻な問題として、このフィルタリングシステムはChatGPTに対する新たな攻撃ベクトルを生み出す可能性がある。Scale AIのプロンプトエンジニアであるRiley Goodsideが発見したように、画像内に特定の名前を極めて薄い、ほとんど見えないフォントで埋め込むことで、ChatGPTのセッションを意図的に中断させることが可能となる。例えば、数学の方程式を含む画像に「David Mayer」という名前を埋め込んだ場合、ユーザーには理解できない理由でChatGPTが突然停止してしまうという事態が発生する。
また、このフィルタリングシステムはChatGPTのウェブブラウジング機能に対しても重大な制限を課している。ChatGPT with Search機能を使用する際、フィルタリング対象の名前が含まれるウェブページ全体の処理が不可能となる可能性がある。これは意図的に悪用される可能性も秘めており、特定のウェブサイトにフィルタリング対象の名前を意図的に配置することで、そのサイトのChatGPTによる処理を妨害することも技術的には可能となる。
さらに看過できない問題として、このフィルタリングシステムの不透明性が挙げられる。ChatGPTは特定の名前に関する制限の理由を説明することができず、代わりに一般的なプライバシーや著作権の基準に言及するのみである。この不透明性は、AIシステムの説明責任という観点から重要な課題を提起している。特に、フィルタリング対象の選定基準や、その判断プロセスの妥当性を検証することが実質的に不可能となっている点は、AI倫理の観点からも看過できない問題である。
このように、現在のフィルタリング手法は、短期的な法的リスク回避という目的は達成しているものの、システムの実用性、セキュリティ、透明性という観点からは、より洗練されたアプローチへの移行が必要とされている状況にあると言える。これらの課題は、AIシステムの発展における重要な転換点を示唆しており、技術的解決策と倫理的配慮のバランスを取る必要性を強く示していると言えるだろう。
Source





コメント