

中国のテクノロジー大手Alibaba Groupの子会社であるAlibaba Cloudは、画期的な視覚言語AIモデル「Qwen2-VL」を発表した。このモデルは、画像や動画の高度な理解能力と多言語での対話能力を備えており、複数のベンチマークテストでOpenAIのGPT-4oやAnthropicのClaude 3.5 Sonnetを上回る性能を示しているという。
Qwen2-VLの概要と主な特徴
Qwen2-VLは、Alibabaが約1年かけて開発した新しいAIモデルファミリーである。このファミリーは、Qwen2-VL-72B、Qwen2-VL-7B、Qwen2-VL-2Bの3つのモデルで構成されている。最も強力なQwen2-VL-72Bモデルは公式APIを通じてアクセス可能であり、Qwen2-VL-7BとQwen2-VL-2BはApache 2.0ライセンスの下でオープンソースとして公開されている。
Qwen2-VLの最も注目すべき特徴は、その高度な視覚理解能力だ。Alibabaによると、このモデルは20分を超える長時間の動画を理解し、高品質な動画ベースの質疑応答を提供することができる。また、複雑な推論や意思決定をサポートしているため、幅広いAIアプリケーションに統合できる可能性がある。

さらに、Qwen2-VLは多言語対応に優れており、英語と中国語に加えて、ほとんどのヨーロッパ言語、日本語、韓国語、アラビア語、ベトナム語をサポートしている。この多言語能力により、グローバルな応用が期待される。
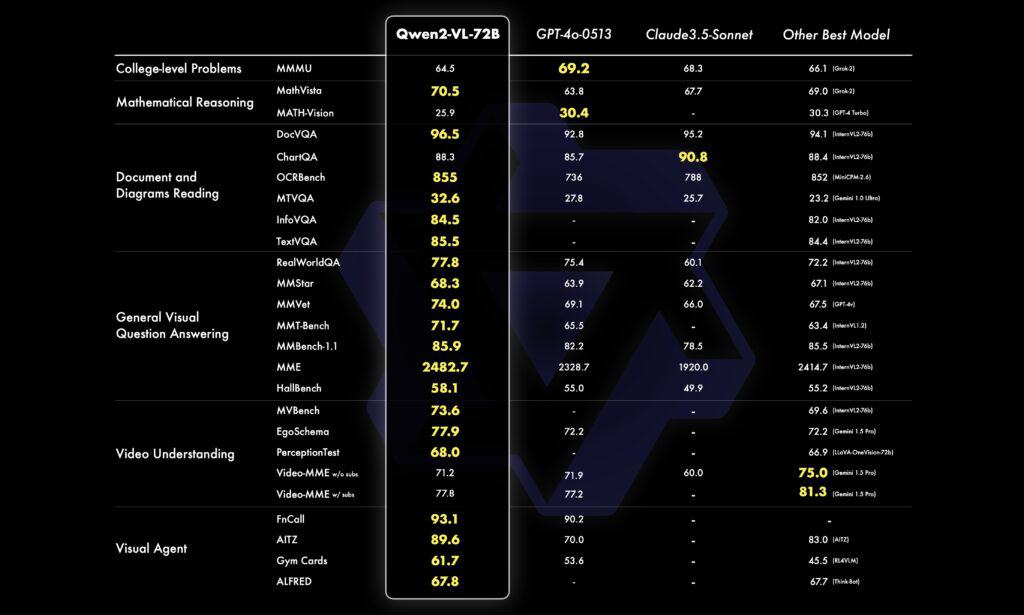
ベンチマークテストにおいて、Qwen2-VL-72BモデルはMathVista、DocVQA、RealWorldQA、MTVQAなど、複数の視覚理解ベンチマークで最先端の性能を達成した。特筆すべきは、このモデルがOpenAIのGPT-4o-0513やClaude 3.5 Sonnetを多くのベンチマークで上回ったことである。
Qwen2-VLの技術的詳細と今後の展望
Qwen2-VLの技術的な特徴として、Vision Transformer(ViT)モデルとQwen2言語モデルの組み合わせが挙げられる。約6億のパラメータを持つViTを使用することで、画像と動画の入力を同時に処理することが可能になっている。
また、Native Dynamic Resolution サポートの実装により、任意の数の画像解像度を扱うことができるようになった。さらに、Multimodal Rotary Position Embedding(M-ROPE)システムの追加により、テキスト、2D視覚、3D位置データを同時に理解することが可能になっている。
Qwen2-VL-7BモデルはDocVQAやMTVQAなどのドキュメント理解タスクで特に優れた性能を示している。最小のQwen2-VL-2Bモデルはスマートフォンへの展開を目指しており、画像、動画、多言語理解において強力な性能を発揮する。
これらのオープンソースモデルは、Hugging Face Transformers、vLLM、その他のサードパーティフレームワークと統合されており、研究者や開発者が容易に利用できる環境が整っている。
ただし、このモデルは、視覚的な推論のみを対象としているため、動画ファイルから音声を抽出することができないなど、限界があると同社は指摘している。 また、トレーニングは2023年6月時点のもので、複雑な指示やシナリオの完全な正確性を保証することはできない。しかしAlibabaは、このモデルのパフォーマンスと視覚的能力は、ほとんどの指標においてトップクラスのベンチマークを示し、OpenAIのフラッグシップモデルGPT-4oやAnthropic PBCのClaude 3.5-Sonnetなどのクローズドソースモデルをも凌ぐと述べている。
Qwenチームは今後の計画について、「より強力な視覚言語モデルの構築と、より多くのモダリティを統合したオムニモデルの実現に向けて努力する」と述べている。
Qwen2-VLファミリーの印象的な性能とオープンソースの可用性は、視覚言語モデルの分野における研究開発を大きく前進させる可能性がある。これにより、様々な領域で新しく革新的なAIアプリケーションが実現されることが期待される。
Source
- Alibaba Cloud: Qwen2-VL: To See the World More Clearly










コメント