

中国の新興AIスタートアップDeepSeekが、人工知能の歴史に新たな一章を刻む革新的な言語モデル「DeepSeek-R1」を発表した。このモデルは、業界最高峰とされるOpenAIの「o1」と同等の性能を持ちながら、驚異的な低コスト化を実現。さらに、完全なオープンソースとして公開されることで、AI開発の民主化に向けた大きな一歩となる可能性を秘めている。
DeepSeek-R1で取り入れられた革新的技術
OpenAIの「GPT-4」やGoogleの「Gemini」、Anthropicの「Claude」のような一般的な大規模言語モデル(LLM)が単なる文章生成や質問応答を行うのに対し、OpenAIの「o1」や今回の「DeepSeek-R1」のような推論モデルは複雑な問題を段階的に解決する能力を持つ。数学の問題を解く際の思考過程や、プログラミングコードを書く際の論理展開など、人間のような思考プロセスを模倣することができる。
従来の言語モデルは、人間が作成した大量の訓練データを必要としていた。一方、DeepSeekは「DeepSeek-R1-Zero」という初期バージョンで、純粋な強化学習のみを用いた画期的なアプローチを採用。これは、まるでチェスの名手AlphaZeroが自己対戦を通じて進化したように、モデルが試行錯誤を繰り返しながら自律的に推論能力を獲得していく手法である。
「DeepSeek-R1」の驚異的な性能
数学・理論分野での卓越性
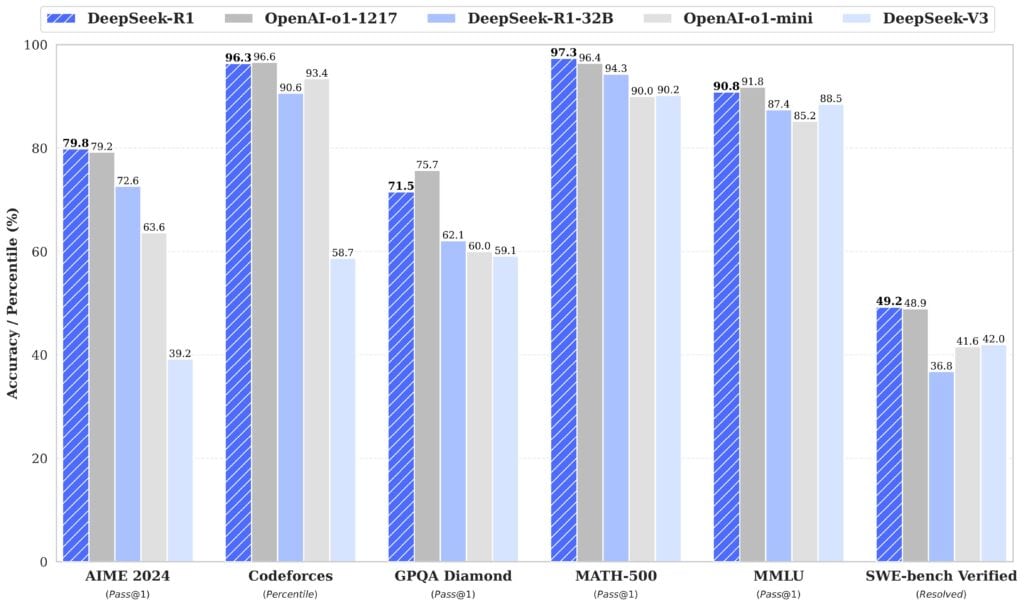
DeepSeek-R1は、高度な数学的推論能力を要する複数の権威あるテストで、既存のAIモデルを凌駕する成績を収めている。特に注目すべきは、アメリカ数学招待試験(AIME 2024)での79.8%という驚異的なスコアだ。この試験は、通常の高校数学の範囲を超えた、創造的な問題解決能力を要する難関コンテストとして知られている。DeepSeek-R1は、この試験でOpenAI o1の79.2%というスコアを上回っている。
さらに注目すべきは、MATH-500での97.3%という驚異的な正答率である。このベンチマークは、代数学、幾何学、統計学など、多岐にわたる数学分野の理解度を総合的に評価するテストとして知られている。OpenAI o1が記録した96.4%をも上回るこのスコアは、DeepSeek-R1が数学的概念の深い理解と、複雑な問題解決能力を備えていることを如実に示している。
プログラミング能力の実証
プログラミング能力の評価においても、DeepSeek-R1は卓越した成績を残している。世界的なプログラミングコンテストプラットフォームであるCodeforcesにおいて、2,029という極めて高いレーティングを獲得した。これは、プラットフォームに参加する世界中のプログラマーの上位3.7%に相当する成だ。このレーティングは、アルゴリズムの理解力、効率的なコード実装能力、そして複雑な問題に対する論理的思考力を総合的に評価した結果であり、実際のソフトウェア開発現場で求められる能力を十分に満たすレベルにあると言えるかもしれない。
特筆すべきは、このプラットフォームでの評価が、単なる事前に用意された問題の解決だけでなく、新しい問題に対する柔軟な対応力も測定している点である。これは、DeepSeek-R1が未知の課題に対しても効果的なアプローチを見出せる可能性を示す物と言える。
汎用知識の評価
汎用的な知識理解力を測定するMMUL(Massive Multitask Language Understanding)テストにおいても、DeepSeek-R1は90.8%という高スコアを達成した。このテストは、医学、法律、歴史、科学、経済学など、幅広い学問分野にわたる理解力を評価する総合的な指標として知られている。OpenAI o1の91.8%には僅かに及ばないものの、この成績は人工知能が専門家レベルの知識を獲得し、活用できることを実証している。
特に注目すべきは、このテストにおけるDeepSeek-R1の回答の質だ。単に正解を導き出すだけでなく、その過程で示される論理的な思考プロセスや、複数の観点からの分析能力は、人間の専門家に匹敵するレベルに達している。これは、モデルが表面的な情報の暗記ではなく、深い概念理解に基づいて回答を生成出来る可能性を示す物だ。
このように、DeepSeek-R1は数学的推論、プログラミング、そして幅広い分野の知識理解において、既存のAIモデルと同等以上の性能を示している。特に注目すべきは、これらの成果が純粋な強化学習によって達成されたという点であり、これは人工知能開発における新たなアプローチの有効性を実証する重要な成果といえる。
画期的な開発プロセスの詳細
フェーズ1:DeepSeek-R1-Zeroによる革新的アプローチ
DeepSeek-R1-Zeroの開発は、人工知能の学習アプローチに関する従来の常識を覆す革新的な試みから始まった。通常、言語モデルの開発では、人間が作成した大量の学習データを用いた教師あり学習が不可欠とされてきた。しかしDeepSeekの研究チームは、まったく異なるアプローチを選択した。
このモデルの開発では、チェスAIのAlphaZeroが示したような、純粋な強化学習による自己進化の手法が採用された。具体的には、Group Relative Policy Optimization(GRPO)と呼ばれる新しいアルゴリズムを活用し、モデルが自らの出力を評価・改善していく仕組みを構築した。この手法では、複数の回答候補を生成し、それらを相互に比較評価することで、より優れた解決策を見出していく。
特筆すべきは、学習過程で自然発生的に現れた「アハモーメント」と呼ばれる現象である。モデルは複雑な問題に直面した際、いったん立ち止まって思考を見直し、新しいアプローチを模索するという、人間の思考プロセスに酷似した振る舞いを自発的に獲得した。これは、強化学習による自己進化が、単なるパターン認識を超えた、真の意味での問題解決能力の獲得につながる可能性を示唆している。
フェーズ2:DeepSeek-R1の実用化への進化
DeepSeek-R1-Zeroが示した可能性を実用化するため、研究チームは次のステップとしてDeepSeek-R1の開発に着手した。この過程では、純粋な強化学習の利点を維持しながら、実用面での課題を解決することに主眼が置かれた。
最も重要な改良点は、モデルの出力の可読性と一貫性の向上である。DeepSeek-R1-Zeroが示した優れた推論能力は維持しつつ、人間にとって理解しやすい形で思考プロセスを表現する能力を付加した。これには、数千件の高品質な事例データを用いた微調整プロセスが採用された。ただしこれらのデータは、従来の教師あり学習で使用されるような大規模データセットとは異なり、あくまでモデルの出力形式を整える目的に限定して使用された。
さらに、マルチステージの訓練パイプラインを導入することで、モデルの総合的な能力向上を図った。このパイプラインでは、推論に特化した強化学習、拒否サンプリングによる品質向上、そして一般的なタスクへの適応という段階的なアプローチが採用された。特に注目すべきは、各段階でモデルの性能を詳細に評価し、必要に応じて前段階に戻って再調整を行う柔軟な開発手法を採用した点である。
このような段階的な改良プロセスの結果、DeepSeek-R1は高度な推論能力を維持しながら、実用的な面での完成度を大きく向上させることに成功した。例えば、プログラミングタスクにおいては、単に正しいコードを生成するだけでなく、その思考過程を分かりやすく説明し、さらに潜在的な問題点や改善案まで提示できるようになった。
開発過程での技術的ブレークスルー
開発プロセス全体を通じて、いくつかの重要な技術的ブレークスルーが達成された。その一つが、言語の一貫性を保つための革新的な報酬システムの開発である。従来の言語モデルでは、複数の言語が混在する出力が頻繁に発生する問題があったが、DeepSeekの研究チームは出力の言語一貫性を評価する新しい指標を開発し、これを強化学習の報酬システムに組み込むことで、この問題を大幅に改善することに成功した。
また、計算効率を向上させるための新しいアルゴリズム開発も特筆に値する。従来の強化学習では、報酬の計算に多大な計算資源が必要とされていたが、グループベースの相対的な評価手法を導入することで、後述するように、計算コストを大幅に削減しながら、効果的な学習を実現することに成功した。この技術革新は、後の小規模モデルへの技術移転を可能にした重要な要素となっている。
コスト削減を可能にした技術
革新的なアルゴリズム設計
DeepSeek-R1の画期的なコスト削減の中核となっているのは、Group Relative Policy Optimization(GRPO)と呼ばれる革新的なアルゴリズムである。従来の強化学習では、各回答に対して個別に複雑な報酬モデルを計算する必要があり、これが計算コストを押し上げる主要因となっていた。GRPOでは、複数の回答を同時に生成し、それらを相対的に比較評価することで、計算効率を大幅に向上させている。この手法により、従来必要とされていた大規模な報酬モデルの構築・運用が不要となり、計算コストを劇的に削減することに成功した。
また、報酬システムの設計においても、大きな革新が図られた。従来のニューラル報酬モデルに代わり、明確なルールに基づくシンプルな報酬システムを採用した。このアプローチにより、「報酬ハッキング」と呼ばれる問題を回避しつつ、より効率的な学習プロセスを実現している。具体的には、数学的な解答の検証やプログラミングコードのテストといった、明確な基準に基づく評価を組み込むことで、複雑な報酬モデルを必要としない効率的な学習を可能にしている。
効率的なモデルアーキテクチャ
DeepSeek-R1は、Mixture of Experts(MoE)と呼ばれる先進的なアーキテクチャを採用している。このアーキテクチャでは、モデル全体を複数の「専門家」モジュールに分割し、入力に応じて最適なモジュールを選択的に活性化させる。全体で671Bという大規模なパラメータを持つモデルでありながら、実際の推論時に使用されるのは37B程度のパラメータのみという効率的な運用を実現している。
この選択的活性化の仕組みにより、必要な計算リソースを大幅に削減することが可能となった。従来の dense(密な)モデルでは、すべてのパラメータを常に使用する必要があったのに対し、MoEアーキテクチャでは必要な部分のみを活性化させることで、計算効率を飛躍的に向上させている。
分散処理システムの最適化
計算負荷の効率的な分散処理も、コスト削減に大きく貢献している。DeepSeekの研究チームは、複数のGPUにわたる計算負荷の最適な配分方法を開発し、ハードウェアリソースの利用効率を最大化することに成功した。特に、MoEアーキテクチャに特化した新しい負荷分散アルゴリズムの開発により、従来のモデルと比較して大幅な効率化を実現している。
この分散処理システムは、モデルの訓練時と推論時の両方で効果を発揮する。訓練時には、複数のGPUを効率的に協調させることで学習速度を向上させ、推論時には必要最小限のリソースで高速な応答を可能にしている。これにより、モデルの運用コストを大幅に削減しつつ、高いパフォーマンスを維持することが可能となった。
実際のコスト効果
これらの技術革新の結果、DeepSeek-R1は従来モデルと比較して驚異的なコスト削減を達成している。入力トークンあたりのコストは、OpenAI o1の$15/百万トークンに対して$0.55/百万トークンと、実に96.3%の削減を実現。出力トークンについても同様に、$60/百万トークンから$2.19/百万トークンへと大幅な削減を達成している。
この劇的なコスト削減は、単なる価格競争の結果ではなく、上述した技術革新の積み重ねによって実現された本質的な効率化の成果である。これにより、高度なAIモデルの実用化における最大の障壁の一つであったコスト問題に対する、現実的な解決策が示されたといえる。
さらに注目すべきは、これらのコスト削減技術が小規模モデルへの展開も可能である点だ。DeepSeekが公開した1.5Bから70Bまでの様々なサイズのモデルにおいても、同様の効率化技術が適用され、それぞれのスケールで最適な性能とコストのバランスを実現している。
小規模モデルへの技術移転
技術移転の革新的アプローチ
DeepSeekは、大規模モデルで実証された高度な推論能力を、より小規模なモデルへ効果的に移転する画期的な手法を開発した。この技術移転プロセスの核心は、DeepSeek-R1が生成した約80万件の高品質な訓練データを活用した蒸留(ディスティレーション)技術にある。特筆すべきは、この過程で単なる応答の模倣ではなく、推論プロセス自体を小規模モデルに継承することに成功した点である。
従来の技術移転では、大規模モデルの出力を単純に模倣させる手法が一般的だったが、DeepSeekの研究チームは推論の過程で生じる中間的な思考ステップまでを含めた包括的な学習データを生成。これにより、小規模モデルでありながら、複雑な推論タスクにも対応できる能力を獲得させることに成功している。
多様なモデルラインナップの特徴
DeepSeekは、異なる用途や計算環境に対応するため、1.5Bから70Bまでの幅広いパラメータ規模のモデルを開発した。最小規模の1.5Bモデルは、標準的なノートPCでも動作可能な軽量さを実現しながら、驚くべきことにGPT-4やClaude 3.5 Sonnetを特定の数学ベンチマークで上回る性能を示している。これは、効率的な知識移転の成果を如実に示す例といえる。
中規模モデルである7Bおよび14Bは、一般的なビジネス用途に最適な性能とリソース効率のバランスを実現。特に14Bモデルは、より大規模なQwQ-32B-Previewを複数のベンチマークで上回る性能を達成している。これらのモデルは、一般的なワークステーションやクラウドサービスでの運用を想定して最適化されている。
大規模モデルである32Bと70Bは、より高度な推論要求に対応するよう設計されている。特に32Bモデルは、OpenAIのo1-miniと同等以上の性能を示し、高度な数学的推論やプログラミングタスクにおいて卓越した能力を発揮する。これらのモデルは、企業の本格的なAI活用シーンを想定して開発された。
性能評価の詳細分析
小規模モデルの性能評価において特に注目すべきは、数学的推論能力の保持率の高さである。例えば、DeepSeek-R1-Distill-Qwen-7Bは、AIME 2024で55.5%という高スコアを達成。これは、パラメータ数が4倍以上あるQwQ-32B-Previewの性能を上回る結果である。
さらに、14Bモデルは数学的推論において特に優れた性能を示し、AIME 2024で69.7%、MATH-500で93.9%という驚異的なスコアを記録。これらの成績は、モデルサイズの制約を巧みに克服し、効率的な知識表現を実現していることを示している。
実用化への展望
DeepSeek-R1のこれらの小規模モデルは、すべてMITライセンスの下でオープンソースとして公開されている。これにより、研究コミュニティや開発者が自由にモデルを検証、改良、再利用することが可能となった。特に注目すべきは、これらのモデルが単体で使用可能なだけでなく、特定のタスクに特化した追加学習(ファインチューニング)にも適していることである。
今後の展望として、これらの小規模モデルは特定の産業分野やタスクに特化したカスタマイズモデルの基盤として活用されることが期待される。また、計算リソースの制約が厳しいエッジデバイスでの展開など、新たな応用分野の開拓も視野に入れられている。
さらに、DeepSeekの研究チームは、これらのモデルに対する強化学習の適用も検討している。初期の実験結果では、強化学習による更なる性能向上の可能性が示唆されており、今後の研究開発による更なる進展が期待されている。
DeepSeek-R1の3つのアクセス方法
DeepSeek-R1へのアクセス方法は、大きく分けて3つの選択肢が存在する。それぞれに特徴があり、用途に応じて使い分けることが可能だ。
- Webインターフェース(無料)
- スマートフォンアプリ(無料)
- OpenAI互換API(従量課金制)
Web版での利用方法
DeepSeek公式サイトでは、ChatGPTライクなWebインターフェースを提供している。利用開始までの手順は以下の通りだ:
- 公式サイトで「Start Now」をクリック
- メールアドレスとパスワードで登録
- テキストボックスに質問や指示を入力
注目すべき機能として:
- PDFアップロード対応(競合のOpenAI o1より先行)
- 画像アップロード機能
- 「DeepThink」モード(R1モデル専用)
- 「Search」モード(Web検索統合)
特筆すべきは、R1モデルを利用する際の思考プロセスの可視化機能だ。AIが質問を分解し、段階的に思考を展開する様子をリアルタイムで確認できる。
モバイルアプリでの利用
iPhoneおよびAndroid向けに無料アプリを提供しており、以下の特徴がある:
- Web版と同等のインターフェース
- 「DeepThink」モードでR1モデルを利用可能
- 思考プロセスの可視化機能搭載
- Web検索統合機能による最新情報の要約生成
API経由での利用
より本格的な利用には、API経由のアクセスが適しているだろう。
実際の料金表は以下の通りだが、強豪を圧倒する低価格を実現している:
| モデル | 1M入力トークン (キャッシュ有) | 1M入力トークン (キャッシュ無) | 1M出力トークン |
|---|---|---|---|
| deepseek-chat | $0.014 | $0.14 | $0.28 |
| deepseek-reasoner | $0.14 | $0.55 | $2.19 |
DeepSeek-R1のAPIは以下の特徴がある:
- OpenAI APIとの完全な互換性
- モデル名は「deepseek-reasoner」
- 競合モデルと比較して大幅な低価格設定
- PayPalやクレジットカードでのチャージ対応
利用上の注意点
現状無料、格安で利用可能なDeepSeek-R1だが、以下の点には注意が必要だ:
- Web版・アプリ版共に利用回数に制限あり(具体的な制限数は非公表)
- PDFアップロード時は処理に時間を要する
- APIは従量課金制で、使用量に応じて残高が消化
Sources
- GitHub: deepseek-ai/DeepSeek-R1








コメント