
インターネットで検索すると、自動運転車の失敗を示す多くの動画が見つかり、しばしば笑顔や笑いを誘う。なぜ私たちはこれらの行動を面白いと感じるのだろうか。それは、人間のドライバーが同様の状況にどう対処するかと著しく対照的だからかもしれない。
私たちにとって些細に思える日常的な状況でも、自動運転車にとってはまだ大きな課題となっている。これは、自動運転車が人間の心の働き方とは根本的に異なる工学的手法を用いて設計されているためである。しかし、最近のAIの進歩により、新たな可能性が開かれた。
ChatGPTのようなチャットボットの背後にある技術など、言語能力を持つ新しいAIシステムが、自動運転車をより人間のドライバーのように推論し、行動させるための鍵となる可能性がある。
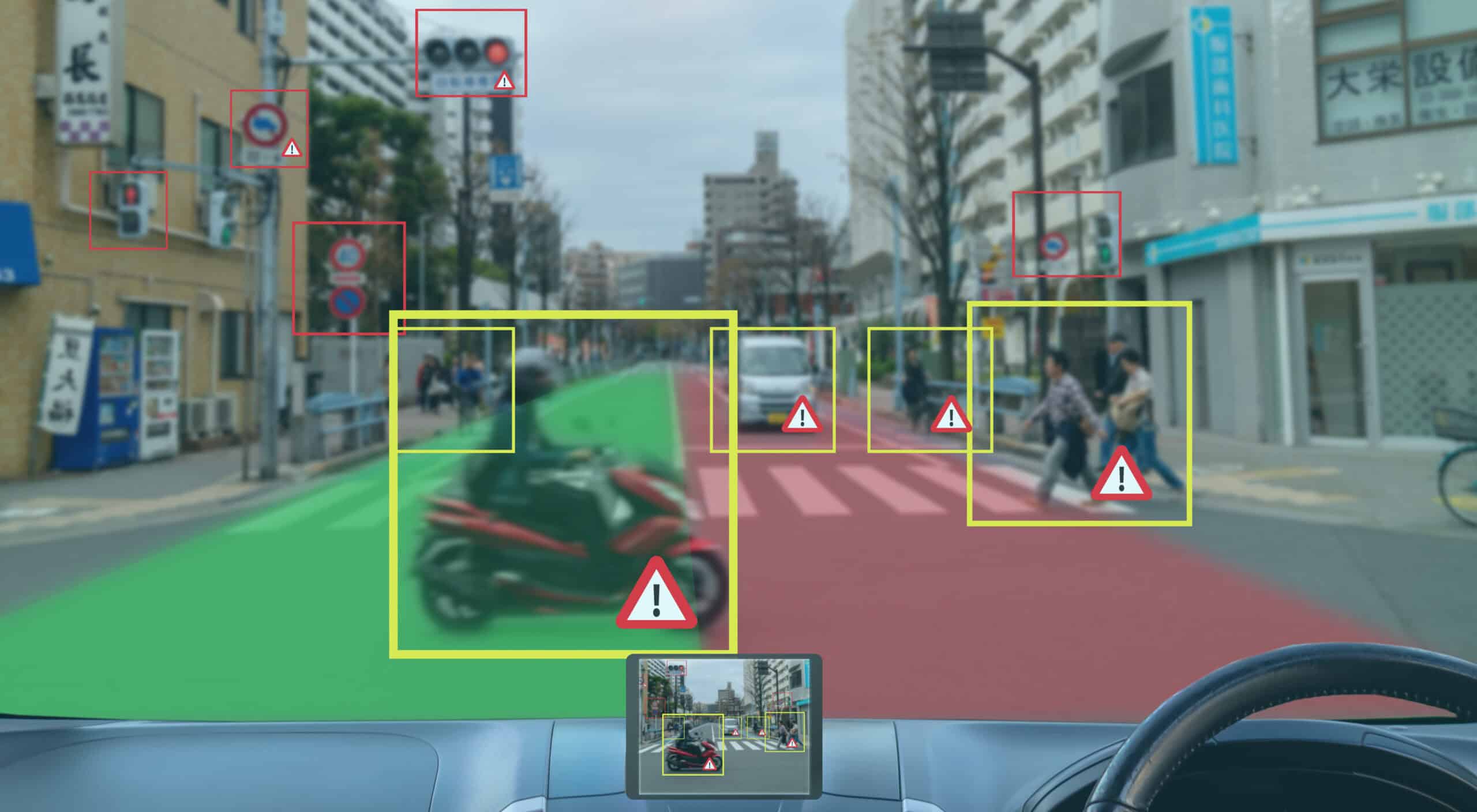
自動運転の研究は、2010年代後半にディープニューラルネットワーク(DNN)の出現により大きな勢いを得た。DNNは、人間の脳にインスピレーションを受けたデータ処理を行うAIの一形態である。これにより、交通シナリオの画像や動画を処理し、障害物などの「重要な要素」を識別することが可能になった。
これらの検出には、多くの場合、障害物のサイズ、向き、位置を決定するための3Dボックスの計算が含まれる。このプロセスは、例えば車両、歩行者、自転車利用者に適用され、クラスと空間的特性(自動運転車との相対的な距離や速度を含む)に基づいた世界の表現を作り出す。
これが、「感知-思考-行動」として知られる自動運転の最も広く採用されているエンジニアリングアプローチの基礎となっている。このアプローチでは、まずセンサーデータがDNNによって処理される。次に、そのセンサーデータを使用して障害物の軌道を予測する。最後に、車の次の行動を計画するシステムがある。
このアプローチはデバッグが容易であるなどの利点を提供するが、感知-思考-行動フレームワークには重大な制限がある。それは、人間の運転の背後にある脳のメカニズムとは根本的に異なるということだ。
脳からの教訓
脳の機能については未だ多くが不明であり、人間の脳から得られる直感を自動運転車に適用することは困難である。それにもかかわらず、神経科学、認知科学、心理学からインスピレーションを得て自動運転を改善しようとする様々な研究が行われている。
長年確立された理論によると、「感知」と「行動」は順序立てられたものではなく、密接に関連したプロセスである。人間は、環境に対して行動を起こす能力という観点から環境を認識している。
例えば、交差点で左折しようとするとき、ドライバーは環境の特定の部分や左折に関連する障害物に焦点を当てる。対照的に、感知-思考-行動アプローチは、現在の行動意図とは無関係に、シナリオ全体を処理する。
人間との他の重要な違いは、DNNが主に訓練されたデータに依存していることである。わずかに異常なシナリオのバリエーションに遭遇すると、失敗したり重要な情報を見逃したりする可能性がある。

このような珍しく、十分に表現されていないシナリオは「ロングテールケース」として知られており、大きな課題となっている。現在の回避策は、より大きな訓練データセットを作成することだが、実生活の状況の複雑さと変動性により、すべての可能性をカバーすることは不可能である。
結果として、感知-思考-行動のようなデータ駆動型アプローチは、未見の状況への一般化に苦労している。一方、人間は新しい状況への対処に優れている。
世界に関する一般的な知識のおかげで、私たちは「常識」を使って新しいシナリオを評価することができる。常識とは、実用的な知識、推論、そして人々が一般的にどのように行動するかについての直感的な理解の混合であり、生涯の経験から築かれたものである。
実際、人間にとって運転は別の形の社会的相互作用であり、道路利用者(他のドライバー、歩行者、自転車利用者)の行動を解釈する上で常識が重要である。この能力により、予期せぬ状況で適切な判断と決定を下すことができる。
常識のコピー
DNNに常識を複製することは、過去10年間大きな課題となっており、学者たちはアプローチの抜本的な変更を求めてきた。最近のAIの進歩により、ようやく解決策が提供されつつある。
大規模言語モデル(LLM)はChatGPTのようなチャットボットの背後にある技術であり、人間の言語を理解し生成する驚異的な能力を示している。その印象的な能力は、様々な分野にわたる膨大な情報で訓練されていることに由来しており、これにより私たちのものに近い形の常識を発達させることができた。
最近では、GPT-4oやGPT-4o-miniのようなマルチモーダルLLM(テキスト、視覚、ビデオでユーザーの要求に応答できる)が言語と視覚を組み合わせ、広範な世界知識と視覚入力について推論する能力を統合している。
これらのモデルは、目に見えない複雑なシナリオを理解し、自然言語で説明を提供し、適切な行動を推奨することができ、ロングテール問題に対する有望な解決策を提供している。
ロボティクスの分野では、言語と視覚の処理をロボットの行動と組み合わせた視覚-言語-行動モデル(VLAM)が登場しており、言語指示を通じてロボットアームを制御する印象的な初期結果を示している。
自動運転の分野では、初期の研究は、運転の解説や運動計画の決定の説明を提供するためにマルチモーダルモデルを使用することに焦点を当てている。例えば、モデルは「前方に自転車利用者がいて、減速し始めている」と示し、意思決定プロセスへの洞察を提供し、透明性を高める可能性がある。Wayve社は、言語駆動の自動運転車を商業レベルで適用する上で有望な初期結果を示している。
運転の未来
LLMはロングテールケースに対処できるが、新たな課題も提示している。その信頼性と安全性の評価は、感知-思考-行動のようなモジュラーアプローチよりも複雑である。統合されたLLMを含む自動運転車の各コンポーネントは検証される必要があり、これらのシステムに合わせた新しいテスト方法が必要となる。
さらに、マルチモーダルLLMは大規模で、コンピューターのリソースを大量に消費し、高いレイテンシ(コンピューターからの行動や通信の遅延)につながる。自動運転車はリアルタイムの操作が必要だが、現在のモデルは十分な速さで応答を生成することができない。LLMの実行には大量の処理能力とメモリも必要であり、これは車両の限られたハードウェア制約と衝突する。
現在、複数の研究努力が車両での使用に向けてLLMを最適化することに焦点を当てている。常識的な推論を備えた商用自動運転車が街路に登場するまでには、あと数年かかるだろう。
しかし、自動運転の未来は明るい。言語能力を備えたAIモデルにおいて、私たちは限界に近づきつつある感知-思考-行動パラダイムに対する確固たる代替案を持っている。
LLMは、より人間のように推論し行動できる車両を実現するための鍵として広く考えられている。この進歩は、毎年約119万人が交通事故で命を落としていることを考えると、極めて重要である。
交通事故は5〜29歳の子供や若者の主な死因となっている。人間のような推論能力を持つ自動運転車の開発は、これらの数字を大幅に減少させ、無数の命を救う可能性がある。






コメント