

Googleは本日、同社の大規模言語モデル(LLM)の最新版である待望の「Gemini」を発表し、それと共に、今年初めに一般提供を開始したCloud TPU v5eのアップデート版である新しいCloud TPU v5pの存在も明らかにした。v5pポッドは合計8,960個のチップで構成され、1チップあたり最大4,800Gpbsという、Google史上最速のインターコネクトに支えられている。
Googleは、TPU v5pはFLOPSでTPU v4と比較して2倍、高帯域幅メモリで3倍向上していると主張している。半年前に発表したv5eはどうしたのかと思われるだろうが、以下のように多くの点で、v5eポッドはv4ポッドより少しダウングレードしていた。ポッドあたりのv5eチップはv4ポッドの4096個に対して256個しかなく、v5eチップあたりの16ビット浮動小数点演算性能はv4チップの275TFLOPsに対して197TFLOPsだった。新しいv5pでは、より高速なインターコネクトに支えられ、Googleは最大459TFLOPsの16ビット浮動小数点演算性能を達成したとしている。
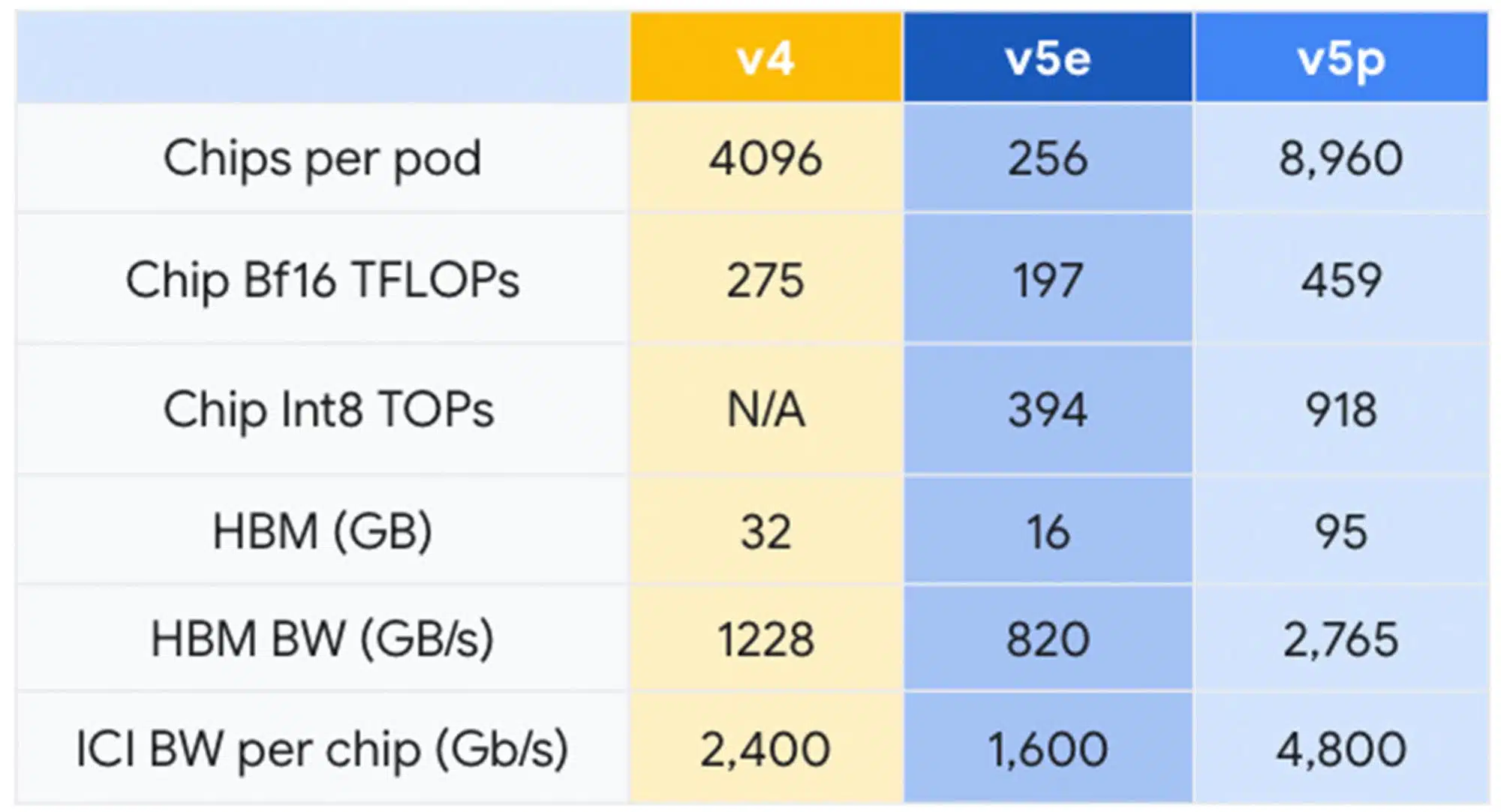
Googleによると、TPU v5pはTPU v4に比べてFLOPsが2倍、ポッドあたりのFLOPSを考慮するとスケーラビリティが4倍向上している。 また、TPU v4に比べてLLMモデルを2.8倍、高密度モデルを1.9倍高速に学習でき、費用対効果も高いということだ(ただし、TPU v5eはより遅いが、1ドルあたりの相対性能はv5pより高い)。
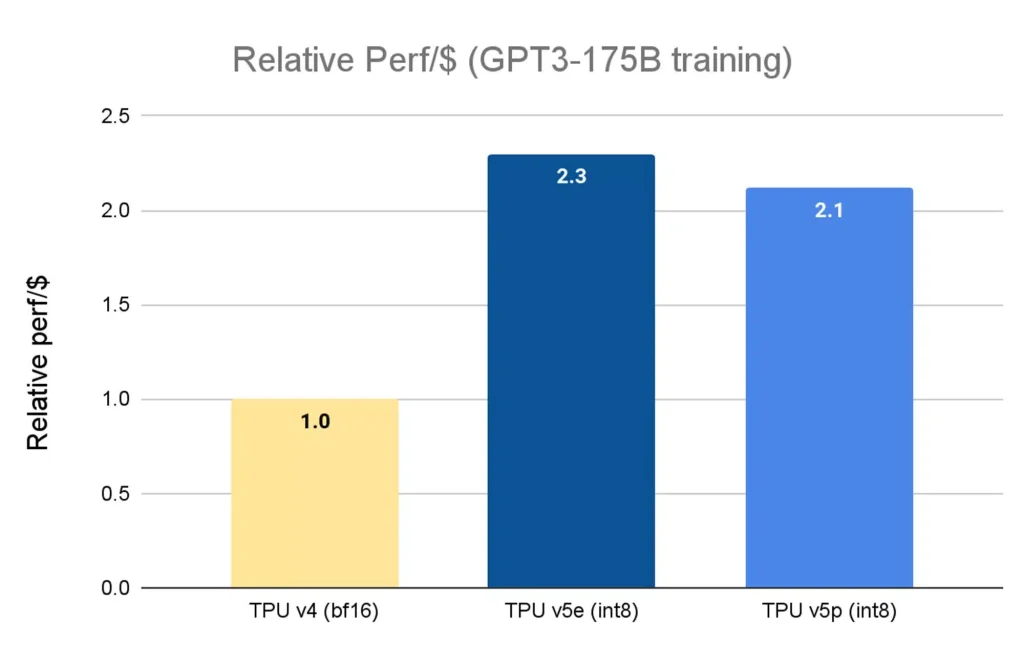
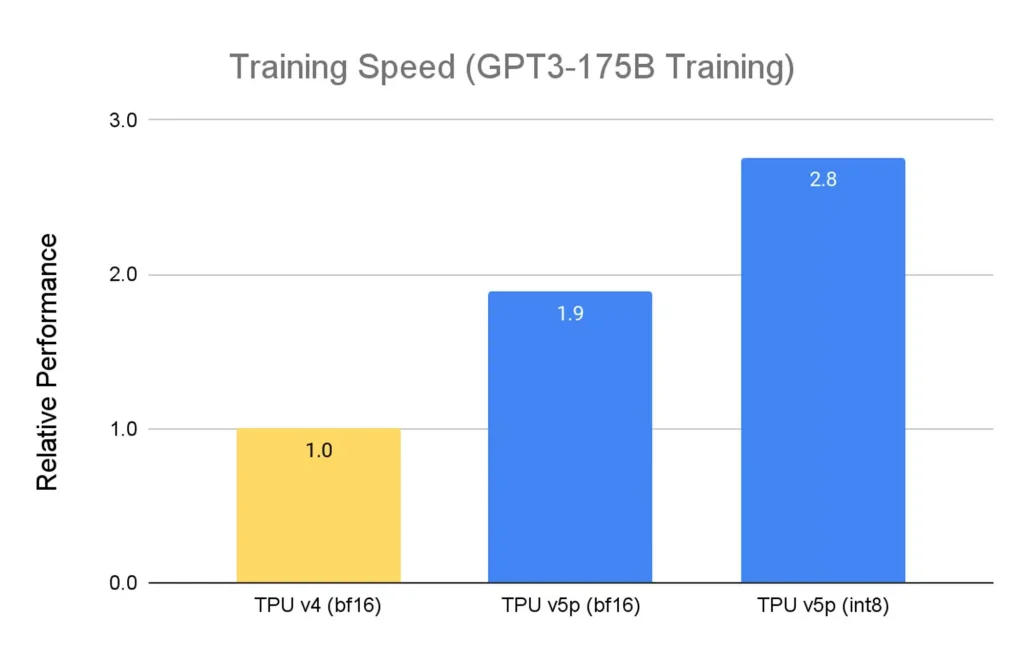
「初期段階での使用において、Google DeepMindとGoogle Researchは、TPU v5pチップを使用したLLMトレーニングのワークロードで、TPU v4世代のパフォーマンスと比較して2倍のスピードアップを確認しました。MLフレームワーク(JAX、PyTorch、TensorFlow)とオーケストレーション・ツールの強固なサポートにより、v5pでさらに効率的にスケールできるようになりました。また、第2世代のSparseCoresにより、エンベッディングを多用するワークロードのパフォーマンスが大幅に向上しました。TPUは、Geminiのような最先端のモデルで、我々の最大規模の研究とエンジニアリングの取り組みを可能にするために不可欠です」と、Google DeepMindとGoogle ResearchのチーフサイエンティストであるJeff Deanは述べている。
新しいTPU v5pはまだ一般に入手可能ではないので、開発者はGoogleアカウントマネージャーに連絡して、ウェイトリストに載る必要がある。
加えて、GoogleはGoogle Cloudの新しいAIハイパーコンピューターも発表した。これは、オープンなソフトウェア、パフォーマンスに最適化されたハードウェア、機械学習フレームワーク、柔軟な消費モデルを備えた統合システムを含むスーパーコンピューター アーキテクチャだ。この統合により、各パーツを個別に検討した場合と比較して、生産性と効率が向上するとしている。AIハイパーコンピューターのパフォーマンスに最適化されたハードウェアは、GoogleのJupiterデータセンター・ネットワーク技術を利用している。
一転して、GoogleはJAX、PyTorch、TensorFlowといった機械学習フレームワークの「広範なサポート」を備えたオープン・ソフトウェアを開発者に提供する。この発表は、MetaとIBMがオープンソース化を優先するAIアライアンスを立ち上げた(Googleは特に関与していない)ことを受けて行われた。AIハイパーコンピューターは、フレックス・スタート・モードとカレンダー・モードの2つのモデルも発表している。
Source









コメント