

Googleが最新の画像生成AIモデル「Imagen 3」を米国ユーザーに向けて静かに一般公開した。Imagen 3は、テキストプロンプトから高品質な画像を生成する能力を持ち、Google自身が「他の最先端モデルよりも優れている」と評価している点で注目を集めている。
Imagen 3は慎重なアプローチを鮮明にし倫理的批判を免れている
Imagen 3は、Googleが2024年5月のGoogle I/Oで初めて発表し、同年6月に一部のVertex AIユーザーに限定公開していたモデルである。今回の一般公開により、米国内のユーザーは誰でもImageFXプラットフォームを通じてこの先進的な技術にアクセスできるようになった。ただし、試してみたところ筆者は日本在住だが、筆者のアカウントでも特に国籍や地域の設定を日本にしたままでも利用が可能だったため、実際のところ地域を限定しているのかどうかは不明だ。
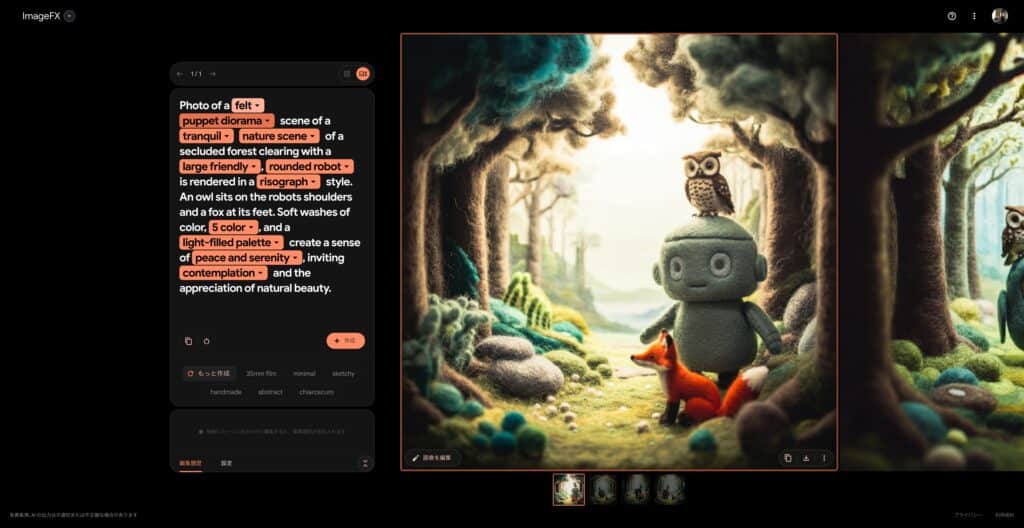
Googleの研究チームは、arxiv.orgで公開した論文[PDF]で「我々はImagen 3を紹介する。これはテキストプロンプトから高品質な画像を生成する潜在拡散モデルである。Imagen 3は、評価時点で他の最先端モデルよりも好まれている」と述べ、その優位性を強調している。
Imagen 3の特筆すべき特徴として、高品質な画像生成能力が挙げられる。特にテクスチャの再現性や文字認識能力が大幅に向上しており、ユーザーからも高い評価を得ている。Redditでは、「品質は非常に高く、素晴らしいテクスチャと文字認識能力を持っている」というコメントが見られた。
しかし、Googleの慎重なアプローチは賛否両論を呼んでいる。Imagen 3には厳格なコンテンツフィルタリングが実装されており、有害なコンテンツの生成を防ぐため、厳しい制限が設けられている。これに対し、一部のユーザーからは「検閲が厳しすぎる。サイボーグさえ作れない」という不満の声も上がっている。
Googleはこの厳格なアプローチについて、「データセットの広範なフィルタリングとデータラベリングを使用して、有害なコンテンツを最小限に抑え、有害な出力の可能性を低減した」と説明している。この姿勢は、AIの責任ある開発と利用を重視するGoogleの方針を反映したものと言える。
一方で、この慎重なアプローチは、Elon Musk氏率いるxAIが発表した「Grok-2」との鮮明な対比を生み出している。Grok-2は画像生成に関してほとんど制限を設けておらず、議論を呼ぶコンテンツの氾濫を引き起こしている。この対照的なアプローチは、AI開発における倫理と創造性のバランスをめぐる業界全体の議論を加速させている。
Imagen 3の性能に関して、Googleは他の主要な画像生成AIモデルとの比較を行っている。人間による評価と自動評価の両方において、Imagen 3はImagen 2、DALL-E 3、Midjourney v6、Stable Diffusion 3、Stable Diffusion XL 1.0を上回る性能を示したという。特に、テキスト記述と生成画像のマッチング、詳細なプロンプトの処理において優れた結果を出している。
しかし、Imagen 3にも課題はある。Google自身が認めるように、数値推論を必要とするタスク(例:正確な数の物体を生成する)や、空間推論や複雑な言語を含むプロンプトの処理には依然として課題が残されている。
Imagen 3の一般公開は、AIの発展と責任ある利用のバランスをどう取るかという業界全体の課題を浮き彫りにしている。今後、ユーザーの創造性を尊重しつつ、AI技術の誤用を防ぐという難しい課題に、GoogleをはじめとするAI開発企業がどのように取り組んでいくかが注目される。また、2024年の米国大統領選挙を控え、AIによる画像生成技術の影響力と責任についての議論は一層活発化すると予想される。
Sources
- arXiv: Imagen 3
- ImageFX
- VentureBeat: Google quietly opens Imagen 3 access to all U.S. users








コメント