

IntelがGPUアーキテクチャ「Battlemage」を採用した新型グラフィックスカード「Arc B580」および「Arc B570」を発表した。前世代から大幅な性能向上を実現しつつ、競合のNVIDIA RTX 4060を上回る性能を249ドルという価格帯で提供する意欲的な製品となっている。
Intel Battlemage製品の概要と性能

Intel初のBattlemageアーキテクチャを採用したArc B580は、自社製造ではなくTSMCの5nmプロセスで製造される「BMG-G21」GPUを採用することで、前世代のAlchemistから大幅な進化を遂げている。

B580の中核となるXeコアは20基を搭載し、各コアには8基のベクターユニットと8基のXMXユニットが統合されている。グラフィックスクロックは2,670MHzという高い動作周波数を実現し、最大ブーストクロックは2,850MHzにまで到達する。これにより、単精度浮動小数点演算性能は14.6TFLOPSを達成している。

メモリ構成においても、競合製品との明確な差別化を図っている。12GBのGDDR6メモリを192bitのメモリバス幅で接続し、19Gbpsの高速なメモリクロックと組み合わせることで、456GB/sという広帯域なメモリ転送速度を実現した。この構成は、NVIDIA RTX 4060やAMD RX 7600が採用する8GBという容量を大きく上回り、高解像度テクスチャや大規模なゲームデータの処理において優位性を持つ。
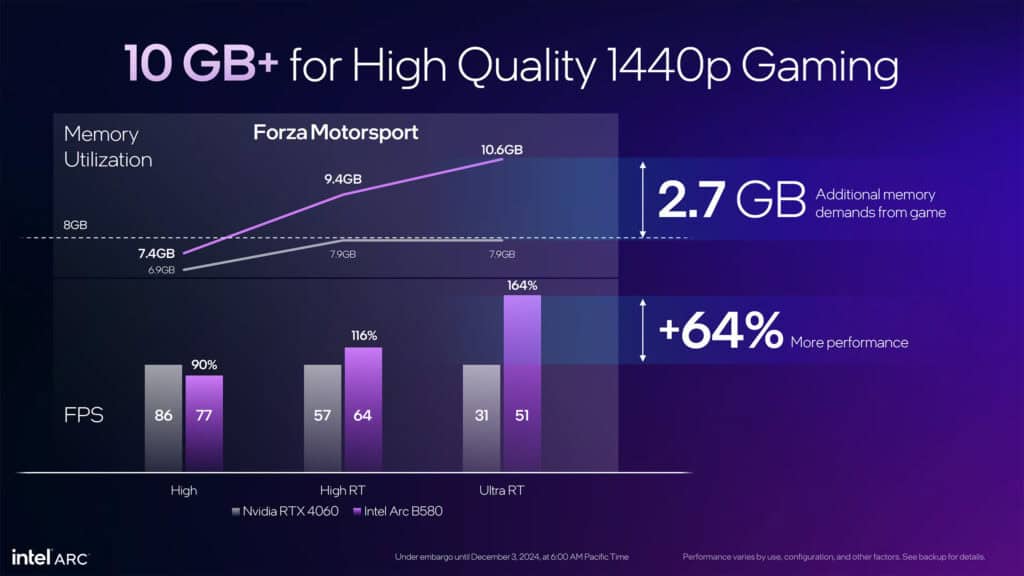
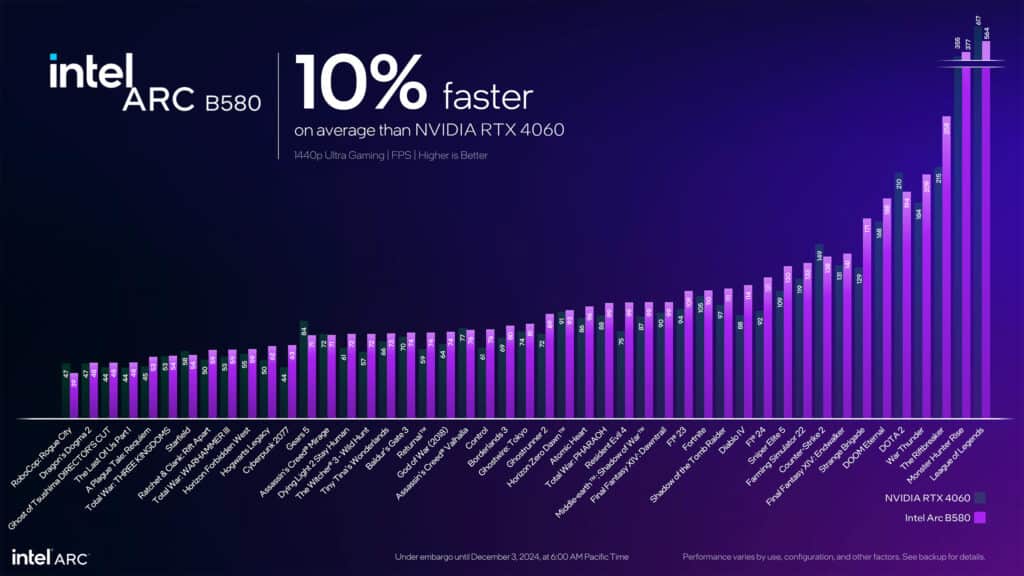
性能面では、1440p解像度における47タイトルのゲームテストにおいて、RTX 4060と比較して平均10%高いフレームレートを記録している。特筆すべきは、ゲームによって-17%から+43%まで大きな性能差が見られる点だ。これは新アーキテクチャの特性とドライバの最適化状況を反映していると考えられる。
一方、より手頃な価格帯を狙うB570は、Xeコアを18基に削減し、メモリ構成も10GB/160bitへと縮小している。グラフィックスクロックも2,500MHzとやや抑えられているものの、380GB/sというメモリ帯域幅は依然として競合製品を上回る水準を維持している。
電力効率の面では、B580は190Wの消費電力で動作し、前世代のA750(225W)と比較して16%の省電力化を実現している。この改善は、TSMCの5nmプロセスへの移行と、アーキテクチャレベルでの最適化の成果と言える。実際のゲームプレイでは、平均して2,800MHz前後のブーストクロックを維持できることが確認されており、安定した高性能動作が期待できる。
なお、両モデルとも第三世代PCIe x8インターフェースを採用しているが、この帯域幅制限は実際のゲーミング性能にはほとんど影響しないとIntelは説明している。現行のゲームタイトルにおいては、PCIe 4.0 x8の帯域幅で十分なデータ転送が可能だと判断されたようだ。
アーキテクチャと技術革新
Battlemageアーキテクチャは、Intelのディスクリートグラフィックス開発における重要な転換点を示している。前世代Alchemistからの進化は単なる性能向上に留まらず、GPUアーキテクチャの根本的な再設計を含んでいる。
最も注目すべき革新は実行ユニットの再構築だ。従来のSIMD32からSIMD16への移行により、並列処理の粒度が適正化された。これは一見すると後退のように見えるかもしれないが、実際には画期的な改善である。SIMD32では32個のデータを同時に処理する必要があり、十分なデータが揃わない場合に性能の無駄が生じていた。SIMD16への移行により、より効率的なワークロードの分配が可能となり、理論性能値以上の実効性能向上を実現している。
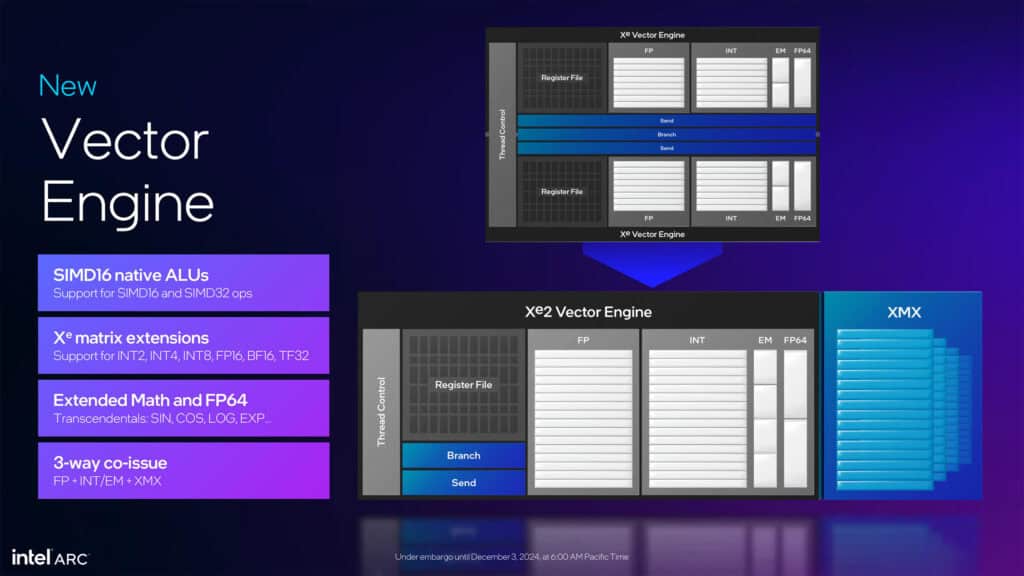
レイトレーシングユニットも大幅に強化された。各ユニットは3つのトラバーサルパイプラインを備え、1サイクルあたり18回のボックス交差計算と2回の三角形交差計算を実行できる。これは前世代と比較して、ボックス交差で50%、三角形交差で100%の性能向上を意味する。さらに、BVHキャッシュも16KBに倍増され、レイトレーシング処理の効率が大きく改善している。
キャッシュ階層の最適化も見逃せない。各Xeコアは256KBのL1/SLMキャッシュを共有し、これは前世代の192KBから33%の容量増加を実現している。L2キャッシュも最大18MBまで拡張され、メモリアクセスのレイテンシ削減に貢献している。この改善は特に高解像度テクスチャの処理や複雑なシェーダー演算において効果を発揮する。

新たな数値フォーマットのサポートも追加されており、INT2とTF32のネイティブ対応により、AIワークロードやディープラーニング処理の効率が向上。特にTF32は、FP32の動的レンジを維持しながら、より効率的なメモリ帯域の利用を可能にしている。
物理設計面では、BMG-G21は5つのレンダースライスを採用し、各スライスに4つのXeコアを統合している。この構成により、合計160のベクターおよびXMXエンジン、20のレイトレーシングユニットとテクスチャサンプラーを実現している。各ピクセルバックエンドは8つのレンダー出力を処理可能で、高解像度での描画性能を確保している。
電力効率の改善は、TSMCの5nmプロセスへの移行だけでなく、トランジスタレベルでの最適化によっても支えられている。BMG-G21は272平方ミリメートルのダイサイズに196億トランジスタを集積し、平方ミリメートルあたり72.1MTという高い密度を達成している。これは前世代の53.4MT/mm²から大幅な向上を示すものの、NVIDIAのAda LovelaceやAMDのRDNA 3と比較するとまだ改善の余地を残している。
AI処理性能とDeep Learning対応
IntelのBattlemageアーキテクチャは、AIワークロードに対する取り組みも一層強化している。B580に搭載されたXMXエンジンは、前世代から大幅な進化を遂げ、より効率的なAI処理を実現している。
新設計のXMXエンジンは、各Xeコアに8基搭載され、2048ビット幅の行列演算を可能にしている。これにより、FP16形式で117TFLOPS、INT8形式で233TOPSという演算性能を達成。特に大規模言語モデル(LLM)の処理において、RTX 4060と比較して40〜50%高い性能を発揮することをIntelは実証している。
この性能向上の背景には、新たに導入されたTF32(Tensor Float 32)フォーマットのネイティブサポートがある。TF32は、8ビットの指数部と10ビットの仮数部を持つ19ビットフォーマットを採用しており、FP32と同等の数値範囲を保持しながら、より効率的なメモリ帯域の利用を実現している。これは特に機械学習の訓練フェーズにおいて、精度と性能のバランスを最適化する上で重要な進展となる。
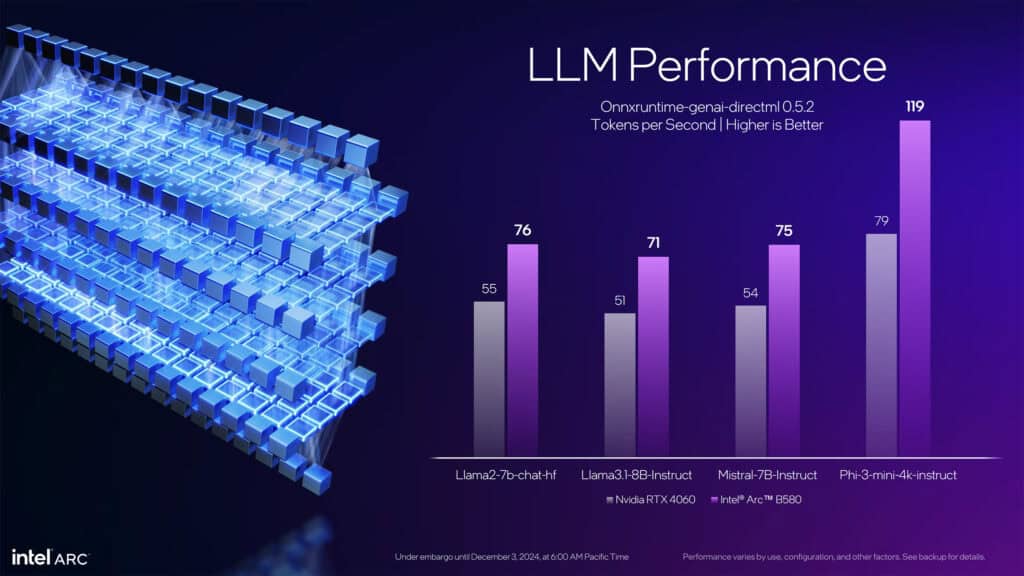
また、INT2フォーマットのネイティブサポートも新たに追加された。これは極めて小さな整数値を扱う際の処理効率を2倍に向上させ、量子化された軽量なニューラルネットワークの実行に特に有効である。INT8、INT4、FP16、BF16といった既存のフォーマットも引き続きサポートされており、多様なAIワークロードに対応できる柔軟性を備えている。
さらに、3-way命令コイシューの採用により、浮動小数点演算、整数演算、XMX演算を同時に実行できるようになった。これにより、AIモデルの推論処理において、より効率的なリソース利用が可能となっている。特にトランスフォーマーベースの言語モデルでは、異なる種類の演算を並列して処理できることで、著しい性能向上が期待できる。
ただし、NVIDIAのTensorコアやAMDのAI Acceleratorと比較すると、まだ最適化の余地は残されている。特に、確立されたAIフレームワークやライブラリとの統合においては、さらなる発展が期待される領域だ。とはいえ、予算を抑えたワークステーション向けのAI処理基盤として、B580は十分な価値を提供していると言えるだろう。
今後、AIアプリケーションの普及が進むにつれ、GPU選択においてAI処理性能の重要性は更に高まることが予想される。その意味で、IntelがBattlemageでAI処理能力の強化に注力したことは、市場動向を見据えた戦略的な判断と評価できる。
新機能とソフトウェア
アップスケーリング技術「XeSS」も第2世代へと進化し(これについては別の記事で詳しくご紹介する)、NVIDIA DLSS 3やAMD FSR 3に対抗するフレーム生成機能を搭載。XMXコアを活用した独自のオプティカルフロー技術により、すべてのArc GPUでフレーム生成が利用可能となっている。
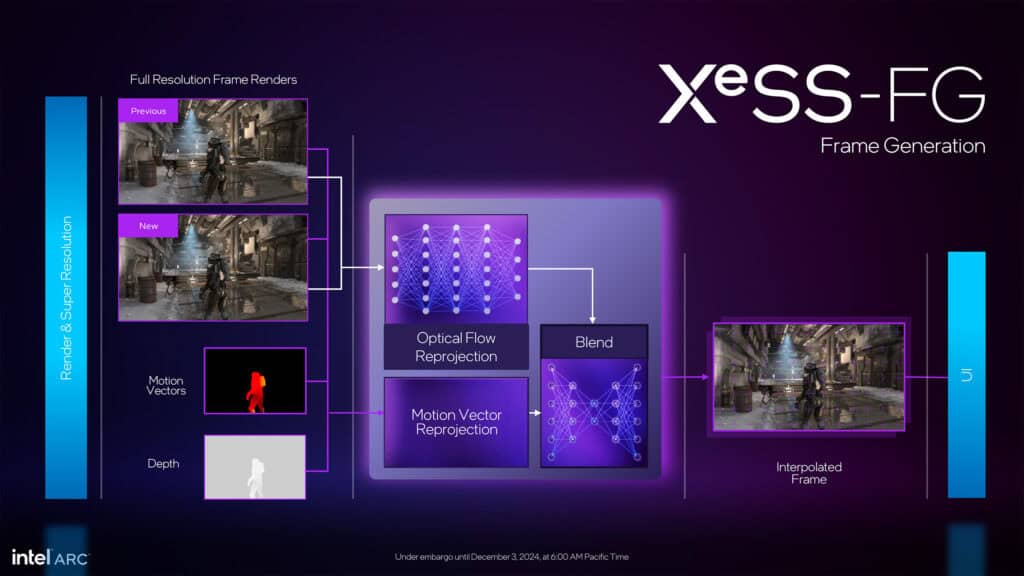
また、今回Intelは、Graphics Softwareユーティリティの大幅な刷新も発表した。この更新にはゲーマーやパワーユーザーが長年求めてきた機能の多数の実装が含まれる。
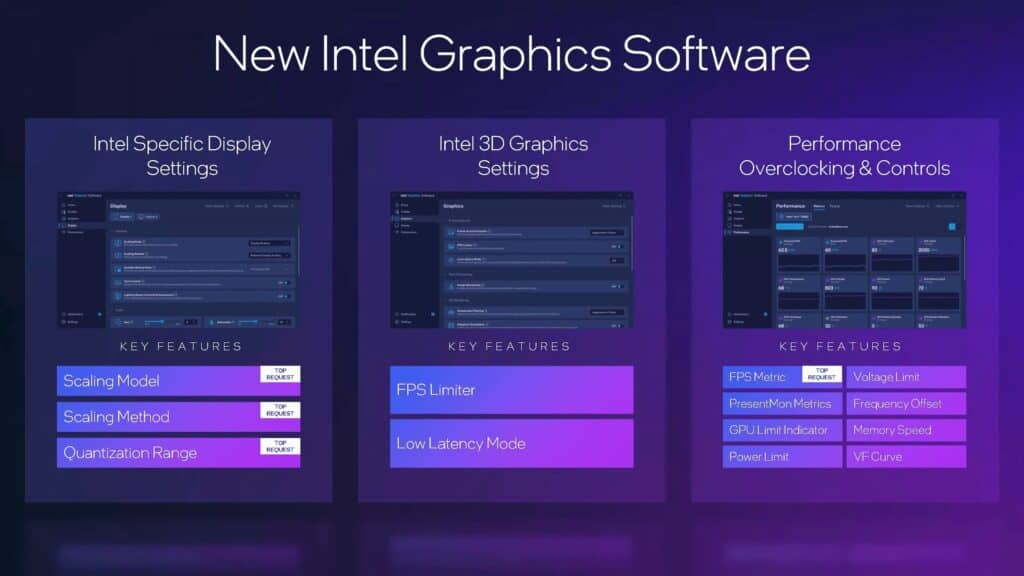
まず注目すべきは、オーバーレイ機能の強化だ。新しいドライバーでは、ゲームプレイ中にFPSメトリクスをリアルタイムで表示できるようになった。これによってゲーマーは、設定変更による性能への影響を即座に確認できるようになる。また、ディスプレイのスケーリング設定も追加され、より細かな画面出力の調整が可能となった。
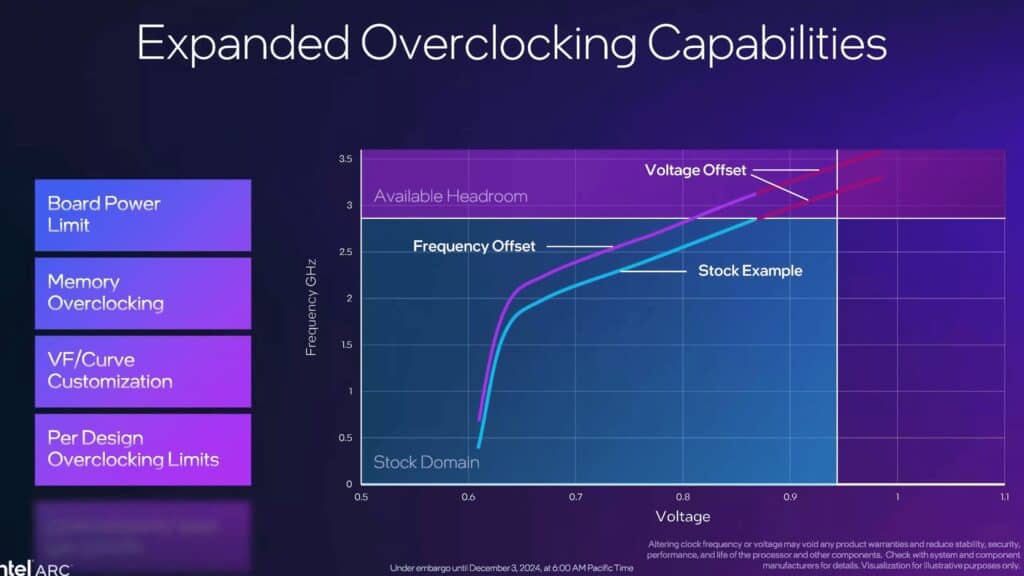
パワーユーザーにとって特に重要な追加機能が、拡張されたオーバークロック機能だろう。新しいユーティリティでは、ボード全体の電力制限の調整が可能となり、より積極的な性能調整を行えるようになった。さらに、電圧-周波数カーブの調整機能も実装され、細かな性能とパワー効率のバランス調整が可能となった。メモリー設定の調整機能と組み合わせることで、ユーザーは自身の用途に最適化されたパフォーマンスプロファイルを作成できる。
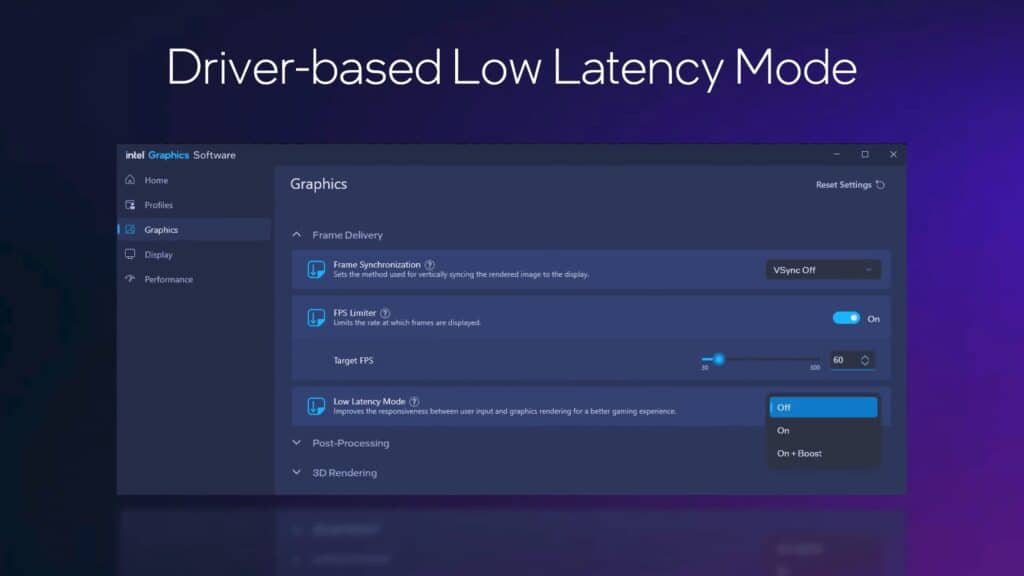
ドライバーレベルでの低遅延モードの実装も、重要な進化のひとつだ。この機能はNVIDIAのUltra Low Latency modeやAMDのAnti-Lag機能に相当するもので、ゲーム固有の実装を必要としない汎用的な遅延低減を実現する。これはXeSS 2のXeLLと異なり、すべてのゲームで利用可能な基本機能として位置づけられている。
これらの機能強化は、Intelがグラフィックスドライバーの成熟度向上に本腰を入れていることを示している。特に、競合他社が長年かけて築き上げてきた機能セットへのキャッチアップを果たしつつ、独自の最適化も加えている点は注目に値する。新しいユーティリティは、ハードウェアの潜在能力を最大限に引き出すためのツールとして、ユーザーにより多くの選択肢と制御性を提供している。
なお、これらの機能強化はBattlemage世代のGPUに限らず、既存のArcシリーズグラフィックスカードにも適用される。これは、Intelが既存ユーザーのサポートも重視していることを示す良い例といえるだろう。ただし、一部の高度な機能はハードウェアの世代による制限を受ける可能性があることには注意が必要である。
価格戦略と市場投入時期
IntelのArc B580は249ドル、B570は219ドルという価格設定で、同社の積極的な市場シェア獲得戦略が鮮明に表れている。

市場投入は段階的に行われ、B580が2024年12月13日、B570が2025年1月16日の発売となる。この時期設定は興味深い示唆を含んでいる。年末商戦には間に合わないB570の投入時期は、NVIDIAとAMDの次世代製品発表が予想される2025年初頭と重なる。これはIntelにとって潜在的なリスクとなる可能性がある。
価格性能比の観点では、B580は現行のRTX 4060(299ドル)と比較して、50ドル安い価格で約10%高い性能を提供する。さらに、12GBという大容量VRAMを備えながら、AMD RX 7600 XT(約310-320ドル)よりも60-70ドル低い価格を実現している。これは、特に1440p解像度でのゲーミングを重視するユーザーにとって魅力的な選択肢となるだろう。
B570については、B580との価格差が30ドルにとどまる一方で、性能面では10%以上の差が予想される。Xeコア数が10%減少し、クロック速度も6%低下、さらにメモリ帯域が17%減少することを考慮すると、価格性能比ではB580の方が優位に立つ可能性が高い。
市場の反応を見極める上で重要なのは、Intelのドライバ開発への信頼度だ。前世代のAlchemistでは初期のドライバ安定性に課題があり、多くのユーザーが様子見の姿勢を取った。この経験から、市場は新製品に対して慎重な態度を示す可能性がある。Intelはこの2年間でドライバの品質を大幅に改善したとしているが、実際の評価は製品投入後の市場の反応を待つ必要がある。
また、B580については、Intel自身が製造する限定版モデルの販売も予定されている。これに加えて、ASRock、Gunnir、Sparkleといった既存パートナーに加え、MaxsunとOnixという新たなパートナーも製品を投入する予定だ。一方、ASUS、MSI、Gigabyteといった大手メーカーの参入はまだ見送られており、市場での製品展開は依然として限定的な状況が続くと予想される。
Xenospectrum’s Take

Intelの新GPU戦略は、価格性能比で市場に切り込むという明確な意図が見える。特に12GBという大容量VRAMの採用は、近年のゲームが要求するメモリ容量の増加傾向を見据えた賢明な判断だ。
ただし、2025年初頭には競合他社の次世代製品が登場する見込みであり、この価格性能比の優位性がどこまで持続するかは不透明だ。また、ドライバの安定性や対応ゲームタイトルの拡充も重要な課題となるだろう。
とはいえ、GPU市場における実質的な選択肢が増えることは、ユーザーにとって歓迎すべき動きである。特に、予算を抑えつつも将来性のある構成を目指すユーザーにとって、B580は魅力的な選択肢となりそうだ。日本での販売価格はまだ不明だが、競争力のある価格での登場を期待したいところだ。
Sources










コメント