

NVIDIAは、AIモデルのトレーニングに用いることが出来る、合成データ生成のためのオープンソースパイプラインである「Nemotron-4 340B」を発表した。この言語モデルは、商業アプリケーション向けの大規模言語モデル(LLM)の訓練および微調整のために、高品質なデータセットを作成する手助けをすることを目的としている。
一部のベンチマークテストではGPT-4oを上回る性能も
AIモデルの開発にはトレーニングデータが必要だ。GPT-4oやGeminiのような大規模言語モデルならば、書籍や論文、ネット上のニュース記事、ブログ、Wikipediaなどの文章データ、DALL-EやMidjourneyのような画像生成モデルならば写真やイラストなどの画像データが用いられるが、これらの学習データは2026年にも枯渇する可能性が指摘されている [PDF]。
こうした問題に対処するため、必要なデータを、特定のAIモデルに合わせてカスタマイズして生成した「合成データ」をAIの学習に用いることが試みられている。
Nemotron-4 340Bファミリーは、ベースモデル、インストラクションモデル、リワードモデルから構成され、LLMの訓練および洗練のために使用される合成データを生成するためのパイプラインを形成している。Nemotronのベースモデルは9兆トークンで訓練された。
合成データは実データの特性を模倣し、データの質と量を向上させることができる。これは、大規模で多様な注釈付きデータセットへのアクセスが限られている場合に特に重要だ。
NVIDIAによれば、Nemotron-4 340B Instructモデルは多様な合成データを生成し、医療、金融、製造、小売などのさまざまなアプリケーション分野でカスタマイズされたLLMの性能と堅牢性を向上させることができるという。また、Nemotron-4 340B Rewardモデルは、高品質な応答をフィルタリングすることで、AI生成データの質をさらに向上させることができるとのことだ。
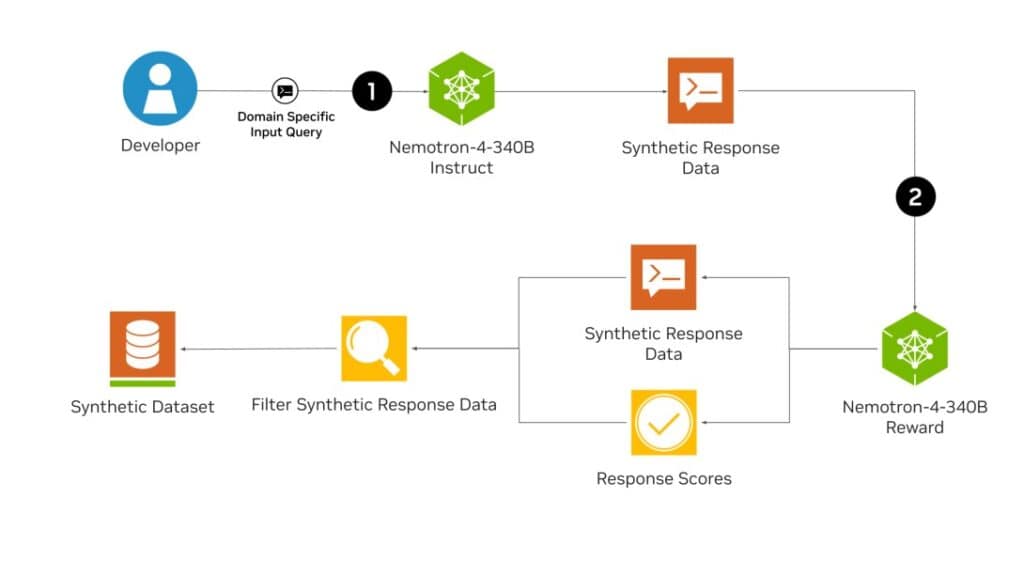
Instructモデルの微調整に使用された訓練データの98%は合成データであり、NVIDIAのパイプラインを使用して作成されたものである。
MT-Bench、MMLU、GSM8K、HumanEval、IFEvalなどのベンチマークにおいて、InstructモデルはLlama-3-70B-Instruct、Mixtral-8x22B-Instruct-v0.1、Qwen-2-72B-Instructなど他のオープンソースモデルよりも一般的に優れた性能を発揮し、いくつかのテストではGPT-4oを上回ることもあるという。
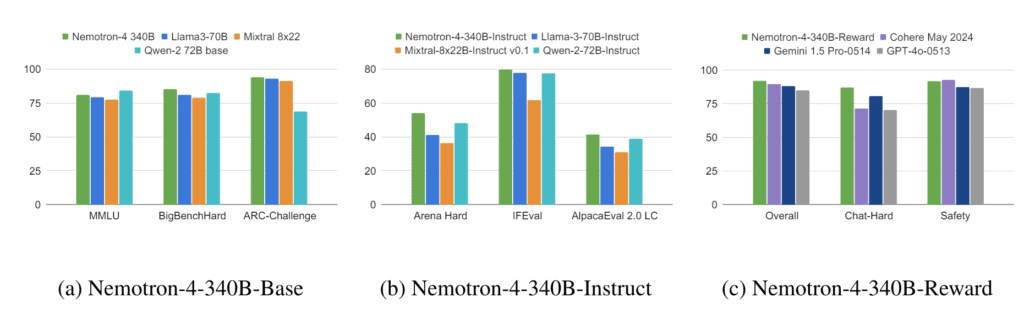
また、要約やブレインストーミングなどのさまざまなテキストタスクにおいて、OpenAIのGPT-4-1106と同等かそれ以上の性能を示している。詳細なベンチマークはテクニカルレポートにて公開されている。NVIDIAによると、これらのモデルは8つのGPUを搭載したDGX H100システムでFP8精度で動作する。
モデルはオープンソースフレームワークのNVIDIA NeMoおよびNVIDIA TensorRT-LLMライブラリを使用して推論に最適化されている。NVIDIAはこれらを商業利用も許可するOpen Model Licenseの下で提供している。すべてのデータはHuggingfaceで利用可能だ。
Nemotronを合成データジェネレータとしてリリースすることは、NVIDIAにとって非常に戦略的な動きだ。NemotronをLlama 3やGPT-4の競合として位置付けるのではなく、このモデルファミリーは他の開発者がさまざまな分野でより優れたモデルや多くのモデルを訓練する手助けをすることを目的としている。より多くのトレーニングと市場でのより多くのモデルの出現は、GPUの需要を高めることを意味し、NVIDIAにとって大きな利益となるだろう。
論文
- NVIDIA: Nemotron-4 340B [PDF]
参考文献
- NVIDIA: NVIDIA Releases Open Synthetic Data Generation Pipeline for Training Large Language Models
- Hugging Face: Nemotron 4 340B
研究の要旨
Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, Nemotron-4-340B-Reward を含む Nemotron-4 340B モデルファミリーをリリースしている。当社のモデルは、NVIDIA Open Model License Agreementに基づきオープンアクセスとなっており、これは、モデルとその出力の配布、修正、使用を許可する寛容なモデルライセンスだ。これらのモデルは、広範な評価ベンチマークにおいて、オープンアクセスモデルに匹敵する性能を発揮し、FP8精度でデプロイされた場合、8GPUを搭載したシングルDGX H100に適合するサイズに設定された。我々は、コミュニティが様々な研究調査や商用アプリケーション、特により小さな言語モデルを学習するための合成データを生成するために、これらのモデルから恩恵を受けることができると信じている。特筆すべきは、我々のモデルアライメントプロセスで使用されたデータの98%以上が合成的に生成されたものであり、合成データ生成におけるこれらのモデルの有効性を示していることだ。さらにオープンな研究をサポートし、モデル開発を促進するために、モデルアライメントプロセスで使用される合成データ生成パイプラインもオープンソース化している。









コメント