

OpenAIが、AI言語モデルの出力をより明確で検証可能なものにする革新的な手法を開発した。この取り組みは、AIシステムへの信頼を高め、重要な分野でのAI活用を拡大する可能性を秘めている。
AIモデル同士の対戦で明確さと検証可能性を向上
OpenAIの研究者らが考案した新たな訓練方法は、「証明者・検証者ゲーム(prover-verifier games)」と呼ばれている。この方法の特徴は、2つのAIモデルが競争的に動作する点にある。1つは「証明者」として問題の解決策を生成し、もう1つは「検証者」としてその正しさをチェックするのだ。
この手法の目的は、検証者が容易に理解できる解決策を証明者が生成するよう訓練することにある。OpenAIによると、この過程は人間にとっても解決策をより理解しやすく、検証可能なものにするという。
研究では、より強力なGPT-4モデルを証明者として設定し、はるかに能力の低いGPT-4モデルを検証者として使用した。訓練中、証明者は「有益」と「狡猾」な役割を交互に担った。有益な役割では、検証者が好む正しい解決策に対して報酬が与えられた一方で、狡猾な役割では、検証者を欺く誤った解決策に対して報酬が与えられた。
訓練の初期段階では、狡猾な証明者は容易に検証者を誤った回答で騙すことができた。しかし、訓練を重ねるにつれて、検証者は微妙な間違いを見抜くことを学習し、証明者は毎回新しい戦術を試すようになった。この訓練は、証明者が検証者を騙せなくなるまで続けられた。
研究者たちは、この方法を小学校レベルの数学問題で検証した。結果、正確さのみを最適化したモデルは、正確だが理解しにくい解答を生成することが分かった。人間の評価者は、この新しいアプローチで生成された解答と比較して、正確さのみを最適化した解答を評価する際に約2倍のエラーを犯した。証明者・検証者ゲームは、正確さと明確さのバランスを取ることに成功した。生成された解答は依然として高い正確性を保ちつつ、はるかに理解しやすいものとなった。
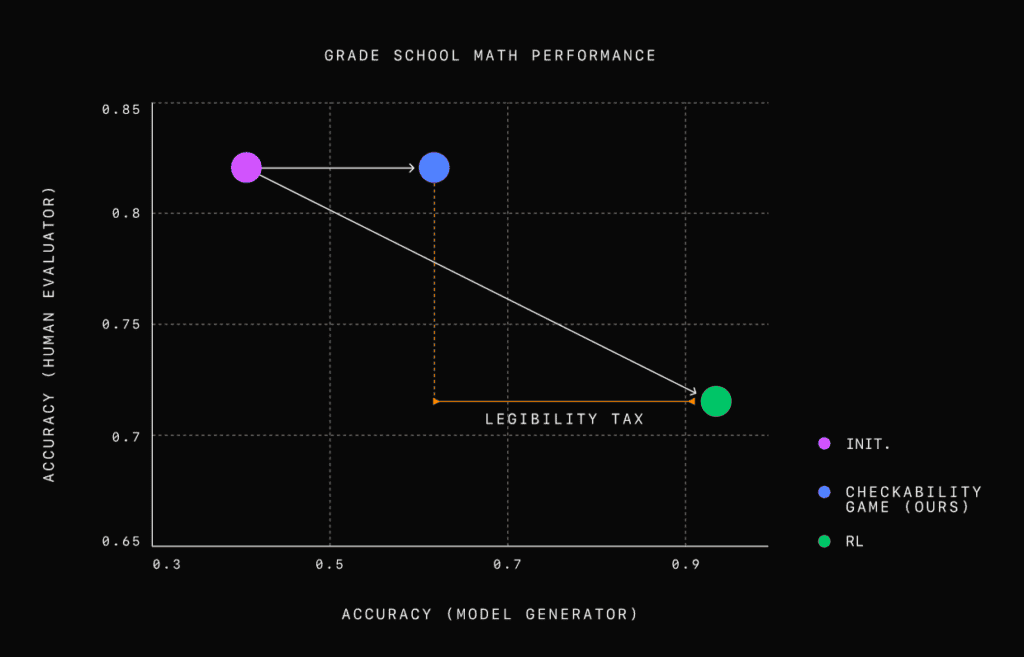
OpenAIの研究チームは、この方法がAIシステムの結果を正確かつ透明に検証できるようにする有望な手段だと考えている。そしてそれが実現されれば、ユーザーがAIの判断プロセスを理解しやすくなる。これにより、医療、金融、法律など、正確性と追跡可能性が重要な分野でのAI応用が拡大する可能性がある。例えば、医療分野では診断理由の明確な説明が可能になり、金融分野では投資判断の根拠を分かりやすく提示できるようになるかもしれない。
さらに、この方法は人間の指導や評価への依存度が低いという利点がある。これは、人間の直接的な監督なしに人間の価値観や期待に確実に沿うことが求められる超知能AIシステムの開発において重要な要素となる。AIの判断プロセスの透明性が向上することで、倫理的な問題の早期発見と対処も可能になるだろう。
しかし、この研究にはいくつかの課題も残されている。より複雑な問題や多様な分野への適用可能性の検証が必要であり、2つのモデルを競争させる方式は計算資源を多く必要とする可能性がある。また、数学問題以外の領域でも同様の効果が得られるかの検証も必要だ。AIが「狡猾」な戦略を学習することの潜在的リスクの評価と対策も重要な課題となるだろう。
論文
- OpenAI: PROVER-VERIFIER GAMES IMPROVE LEGIBILITY OF LLM OUTPUTS [PDF]
参考文献
研究の要旨
大規模言語モデル(LLM)の出力に対する信頼性を向上させる一つの方法は、明確で確認しやすい推論をサポートすることである。我々は、小学生の算数の問題を解くという文脈で可読性を研究し、思考の連鎖解を答えの正しさのみに最適化すると、可読性が低下することを示す。可読性の損失を軽減するために、Anilら(2021)の検証者-検証者ゲームに着想を得た学習アルゴリズムを提案する。我々のアルゴリズムは、解の正しさを予測する小さな検証者、検証者が受け入れる正しい解を生成する「役に立つ」検証者、検証者を欺く誤った解を生成する「ずるい」検証者を繰り返し訓練する。我々は、「役に立つ」証明者の精度と、敵対的攻撃に対する検証者の頑健性が、訓練の過程で向上することを発見した。さらに、読みやすさのトレーニングは、解の正しさを検証する時間的制約のある人間にも有効であることを示す。LLMの訓練期間中、人間の精度は、親切な証明者の解をチェックするときには上昇し、卑劣な証明者の解をチェックするときには低下する。したがって、小さな検証者による検証可能性の訓練は、出力の可読性を高めるための最も妥当な手法である。我々の結果は、人間に対する大規模LLMの可読性を高めるための実用的な方法として、小規模検証者に対する可読性訓練が有効であることを示唆している。









コメント