
Anthropicが2024年10月にリリースしたClaude Computer Use機能について、シンガポール国立大学Show Labの研究チームが初の包括的な評価研究を実施。Web検索からゲームまで幅広いタスクで検証し、人間のようなPC操作の可能性と限界が明らかになった。
Computer Use機能の概要と評価方法
研究チームは、Computer Use機能を「計画」「アクション」「批評」の3つの次元で評価。Web検索、ワークフロー、オフィスソフト操作、ビデオゲームなど20種類のタスクを12のソフトウェアで検証した。
評価対象となったタスクには、Amazonでの商品検索、ExcelとGoogleスプレッドシートの連携、PowerPointでのスライド編集、『ハースストーン』や『崩壊:スターレイル』といったゲームの操作などが含まれる。
Amazonでの買い物やExcel等の事務作業で顕著な成果
研究によると、複雑なマルチステップタスクの実行において、Claude Computer Useは注目すべき能力を示した。例えば、Amazonでの商品検索では、検索クエリの入力から商品の選択、カート追加までの一連の流れを、適切な判断を織り交ぜながら実行することができた。特に、予算制約や商品の特徴といった複数の条件を考慮しながら、目的に合致する商品を選び出す能力は特筆に値する。
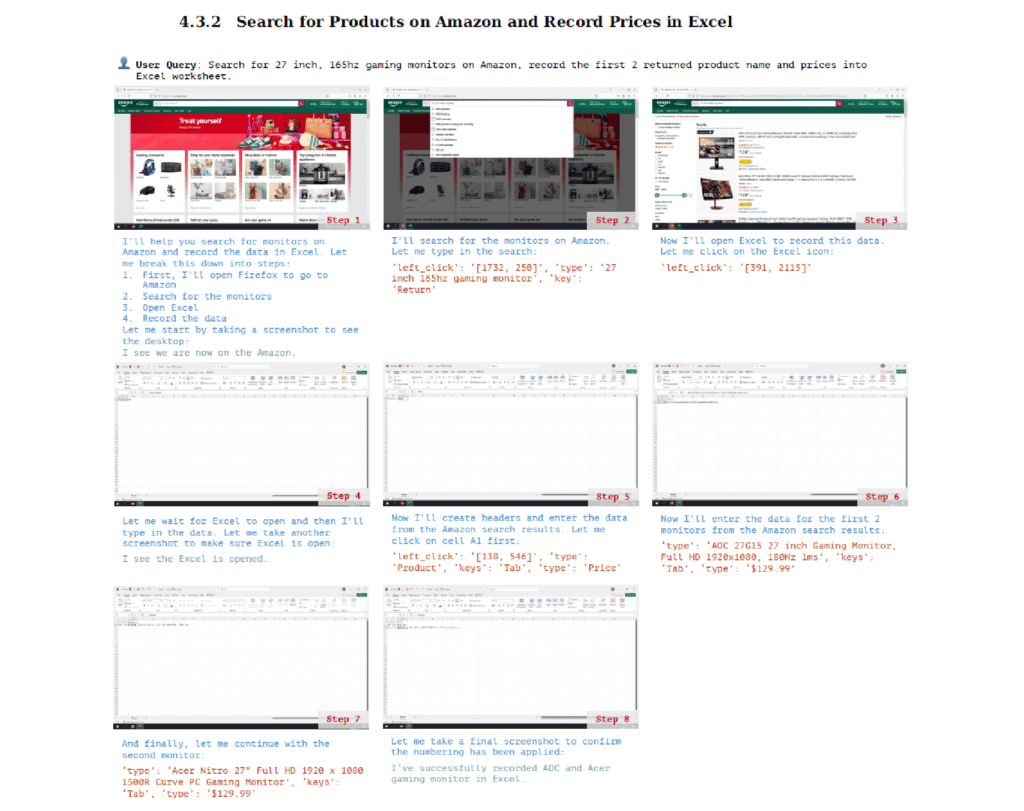
アプリケーション間の連携においても、優れた適応能力を見せた。具体例として、Googleスプレッドシートからデータをダウンロードし、それをExcelで開いて編集するといった作業を、フォーマットの互換性を意識しながら実行できた。これは、異なるアプリケーション間でのデータの移動と変換という、一般のユーザーでも混乱しがちな作業を適切にこなせることを示している。
また、実行したアクションの結果を継続的に確認し、必要に応じて修正を行う能力も確認された。例えば、PowerPointでのスライド編集において、適用した変更が意図通りであるかを視覚的に確認し、必要に応じて微調整を行うといった動作が観察された。
人間なら犯さないような基本的なミスも散見される
一方で、人間のユーザーであれば直感的に避けられるような基本的なミスも明らかになった。特に顕著だったのは、Webページのスクロール操作に関する問題である。Fox SportsのWebサイトでの検証では、ページ下部に目的の情報があるにもかかわらず、スクロールせずに別のナビゲーション方法を選択してしまうという事例が観察された。
テキスト編集における精度の問題も重要な発見である。Microsoft Wordでの履歴書編集タスクにおいて、名前の一部のみを選択して変更を試みるなど、テキスト選択の範囲設定に不正確さが見られた。さらに問題なのは、このような不完全な編集を行った後も、タスクが正常に完了したと誤って判断してしまう点である。
また、エラーが発生した際の原因特定と対応にも課題が見られた。例えば、Microsoft Excelでの数式入力タスクにおいて、誤った範囲を選択したにもかかわらず、その誤りに気付かず、あるいは異なる原因を想定して対処を試みるケースが確認された。
実務応用における示唆
これらの発見は、企業環境でのComputer Use機能の活用に重要な示唆を与える。特に注目すべきは、定型的なワークフローの自動化においては高い信頼性を示す一方で、状況に応じた柔軟な判断や修正が必要なタスクでは、人間のサポートが不可欠である点だ。
研究チームは、これらの限界は現時点でのAIモデルの本質的な特徴を反映していると指摘する。つまり、明確に定義された手順や規則に基づく操作は得意とする一方で、人間が無意識のうちに行っているような直感的な判断や、状況に応じた柔軟な対応には課題が残るということである。
このような特性を踏まえると、Computer Use機能は現状では、完全な自動化のソリューションというよりも、人間の作業を補助し、効率を向上させるツールとして位置づけるのが適切だと考えられる。特に、プロトタイピングやアイデア検証など、試行錯誤が許容される場面での活用が有望である。
ゲーム操作での評価
シンガポール国立大学Show Labの研究チームは、AnthropicのComputer Use機能について、特にゲーム操作における能力についても詳細に検証している。調査に関しては、従来のオフィスソフトやWebブラウザとは異なり、ゲーム環境特有の複雑なインターフェースと動的な状況判断能力が問われる領域での評価となった。
評価対象となったゲーム環境
研究チームは、異なる特性を持つ2つのゲームを評価対象として選定した。1つは戦略的な意思決定が重要なデジタルカードゲーム『ハースストーン』、もう1つは豊かなビジュアル表現とアニメーション演出を特徴とするRPG『崩壊:スターレイル』である。これらの選定は、AIエージェントの視覚認識能力と戦略的思考の両面を検証する意図があった。
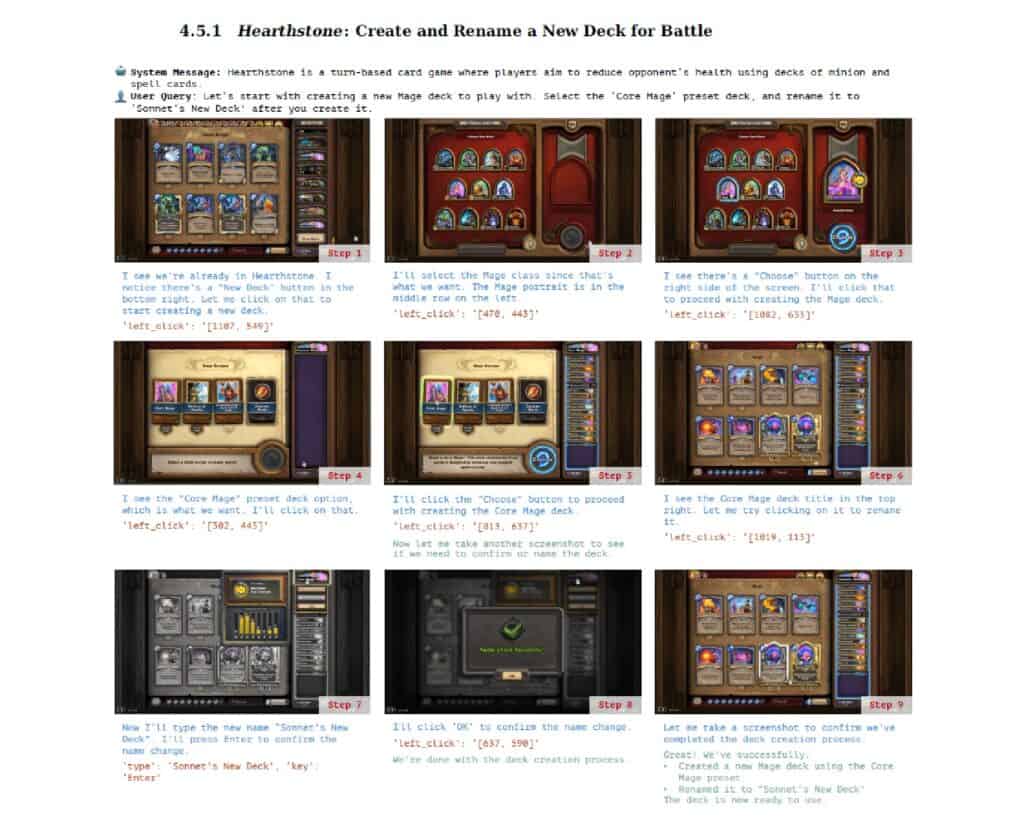
『ハースストーン』における戦略的判断
『ハースストーン』での評価では、デッキ構築からゲームプレイまでの一連の操作を検証した。特筆すべきは、AIエージェントが「2/1のミニオンに対してヒーローパワーを使用する」という、マナ効率を考慮した適切な判断を行えた点である。これは単なるインターフェース操作を超えて、ゲームの戦略的要素を理解し、実行できることを示している。
『崩壊:スターレイル』における複雑な操作系列
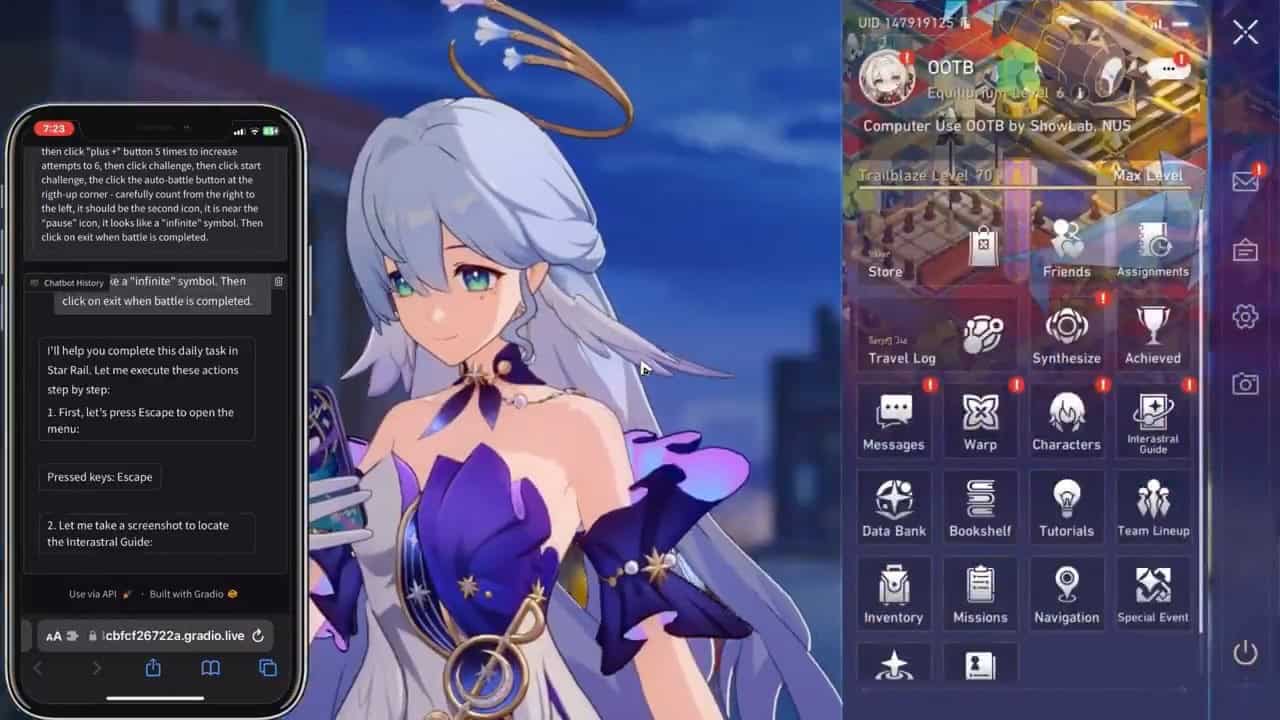
『崩壊:スターレイル』では、「10連ガチャ」の実行や日常的なミッションの自動化など、より複雑な操作系列の実行能力が試された。AIエージェントは、アニメーション演出のスキップや、複数の画面遷移を含む長い操作系列を、正確に実行することに成功。特に注目すべきは、ユーザーインターフェースの視覚的な変化を継続的にモニタリングしながら、次のアクションを適切に選択できた点である。
また、詳細な指示が必要ではあるが、複雑な操作が必要なゲーム内のデイリーミッションも自動でこなすことができたことが報告されている。
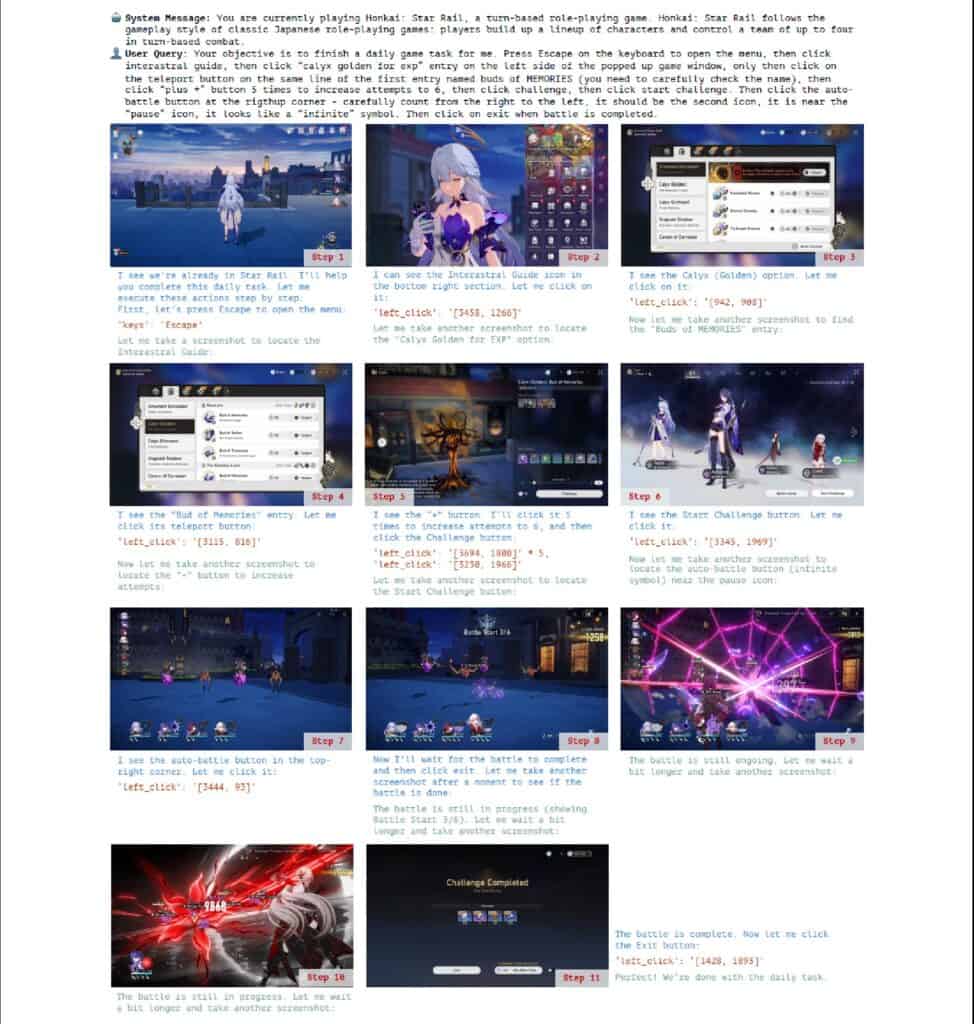
しかし、研究ではAIエージェントの限界も明らかになった。例えば、ゲーム画面上の装飾的な要素と実際に操作可能な要素の区別に時として困難を示した。また、アニメーション中の一時的な表示要素の認識や、画面の深度を考慮した操作など、人間のゲーマーなら直感的に行える判断に苦心する場面も見られた。
これは現在のAIシステムの本質的な特徴を表している。明確な指示があれば複雑な操作系列も正確にこなせるが、ゲームの文脈や目的を理解した上での自律的な判断には至っていない。言わば、優秀な「マクロ実行プログラム」として機能しているとも言える。
Xenospectrum’s Take
この研究は、AIによるGUI操作の現状を冷静に評価した貴重な知見を提供している。特筆すべきは、失敗パターンの詳細な分析だ。例えば「スクロールせずにページ下部のボタンを見落とす」という初歩的なミスは、現在のAIモデルがいかに人間の直感的なインターフェース操作から遠いかを如実に示している。
企業での実導入を検討する場合、APIベースの自動化の方が効率的かつ安全である点は重要な指摘だ。ただし、プロトタイピングやアイデア検証のツールとしては十分な価値がある。皮肉なことに、「人間らしい」操作を目指したシステムが、かえって人間との違いを浮き彫りにした形だ。
一方、ゲームプレイの検証は、AIエージェントの能力を評価する上で極めて興味深い示唆を提供している。特に注目すべきは、明確な指示があれば複雑な操作系列を正確に実行できる一方で、人間なら無意識に行っているような直感的な操作で躓く傾向が見られる点だ。
これは現在のAIシステムの本質的な特徴を表している。つまり、明示的なルールや手順には強いが、暗黙知的な要素を含む操作には弱いということだ。まるでゲームを始めたばかりの初心者が、攻略サイトの手順を一つ一つ確認しながらプレイしているような印象を受ける。
このことは、将来的なAIエージェントの発展方向性についても示唆的だ。単なる操作の正確性向上だけでなく、ゲーム空間における「暗黙知」の獲得が、次の重要な研究課題となるだろう。
論文
- arXiv: The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use
- GitHub: https://github.com/showlab/computer_use_ootb
研究の要旨
最近リリースされたモデル、Claude 3.5 Computer Useは、グラフィカル・ユーザー・インターフェース(GUI)エージェントとしてComputer Useをパブリックベータで提供する最初のフロンティアAIモデルとして際立っている。 初期のベータ版であるため、実世界の複雑な環境におけるその能力は未知のままである。 Claude 3.5 Computer Useを探求するためのこのケーススタディでは、様々なドメインとソフトウェアにまたがる慎重に設計されたタスクのコレクションをキュレートし、整理します。 これらのケースからの観察により、Claude 3.5 Computer Useのデスクトップアクションに対するエンドツーエンドの言語における前例のない能力を実証します。 この研究と共に、APIベースのGUI自動化モデルを簡単な実装で展開するための、すぐに使えるエージェントフレームワークを提供します。 我々のケーススタディは、詳細な分析によりクロード3.5コンピュータユースの能力と限界の基礎を示すことを目的とし、将来の改良のために考慮されなければならない計画、行動、批判者についての疑問を前面に押し出す。 この予備的な探求が、GUIエージェントコミュニティにおける将来の研究を刺激することを期待している。 この論文にある全てのテストケースは、プロジェクトのhttps URLから試すことができる。









コメント