

Google DeepMindは、新しい動画生成AIモデル「Veo 2」と画像生成AIモデル「Imagen 3」の大規模アップデートを発表した。Veo 2は4K解像度での動画生成が可能で、複数の比較テストでOpenAIのSora Turboを上回る評価を獲得している。
Veo 2が示す圧倒的な技術進歩
新しいVeo 2モデルは、最大4K(4096 x 2160ピクセル)の解像度で数分間の動画生成が可能な能力を持つ。これはOpenAIのSoraが生成できる1080p、20秒という制限を大きく上回る仕様となっている。ただし、現時点でのVideoFXプラットフォームでの実装では、720p解像度、8秒間に制限されているものの、将来的な可能性を示す重要な技術的進歩といえる。
特筆すべきは、Veo 2が映像制作の専門的な要素を深く理解している点だ。具体的には、18mmレンズによるワイドアングルショットや被写界深度の浅い撮影など、プロの映像作家が使用する撮影技法をプロンプトで指定できる。さらに、ローアングルのトラッキングショットや、顕微鏡をのぞき込む科学者の表情を捉えたクローズアップショットなど、複雑なカメラワークにも対応している。
物理法則の理解においても大きな進展が見られる。液体のダイナミクスや光の反射、影の表現が より自然になり、特にメープルシロップのような粘性の高い液体の動きや、コーヒーが注がれる様子なども、より現実に近い表現が可能になった。さらに、Pixar風のアニメーション表現においても高い再現性を示している。
MetaのMovieGenBenchデータセットを使用した1,003件のプロンプトによる比較テストでは、Veo 2が総合的な品質とプロンプトの忠実度の両面でSora Turboを上回る評価を獲得した。これは人間の評価者による判定に基づくもので、特に動きの多いシーンにおけるテクスチャーや画像の鮮明さが高く評価されている。
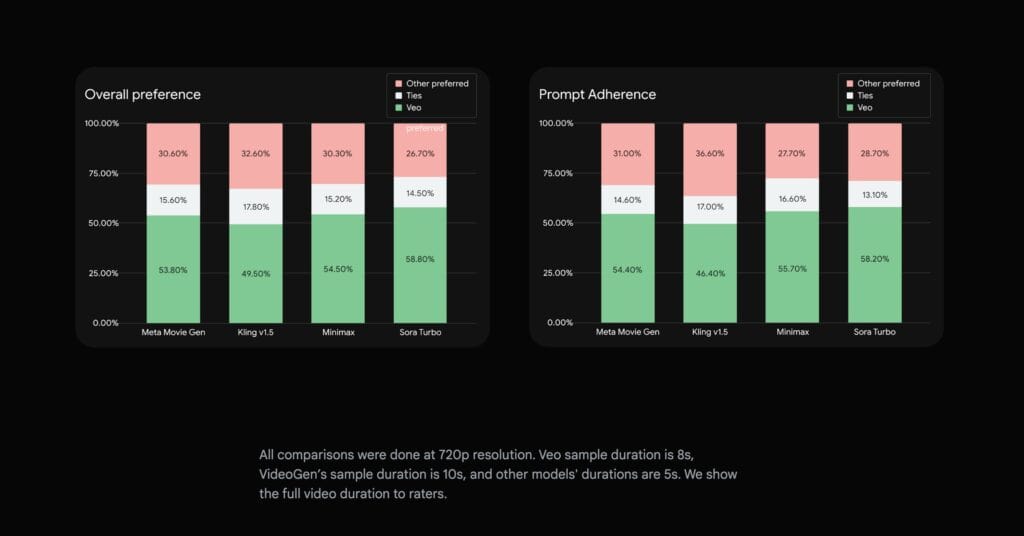
従来のAI動画生成モデルで頻繁に発生していた「ハルシネーション」(余分な指や予期しない物体の出現)の問題も、Veo 2では大幅に改善されている。ただし、DeepMindのEli Collins氏が認めるように、複雑な動きを伴うシーンや長時間のプロンプト対応、キャラクターの一貫性については、まだ改善の余地が残されている。特に建物のファサードの物理的に不可能な形状や、背景の歩行者が互いに溶け合ってしまうような現象は、依然として課題となっている。
実用化に向けた慎重なアプローチ
GoogleはVeo 2の展開において、段階的かつ慎重なアプローチを採用している。現在の利用可能範囲はVideoFX、YouTube、Vertex AIプラットフォームという限定された製品に絞られており、特にVideoFXについてはウェイトリスト制を導入している。利用を希望するユーザーは、Googleフォームを通じて申請を行い、Googleの審査を経て段階的にアクセス権が付与される仕組みとなっている。
安全性への配慮も徹底されており、生成される全ての動画にはAI生成コンテンツであることを示す電子透かし「SynthID」が埋め込まれる。この透かしは不可視であるものの、コンテンツの出所を特定可能とすることで、ディープフェイクなどの悪用リスクに対する防御策として機能することが期待されている。ただし、Collins氏は、どのような透かし技術も完全ではないことを認めている。
2025年に予定されているYouTube Shortsなどへの展開についても、段階的なアプローチが取られる。これは、モデルの品質と安全性を確認しながら、潜在的な問題点を特定し、改善するための時間を確保する戦略といえる。現在、YouTube クリエイターたちはYouTube Shortsの背景作成にVideoFXを活用しており、この限定的な使用例を通じて実用面での課題を収集している。
知的財産権の保護についても慎重な姿勢を示しており、WebマスターがDeepMindのボットによるトレーニングデータの抽出をブロックできるツールを提供している。ただし、既存のトレーニングセットからの作品削除メカニズムは提供されておらず、公開データを用いたモデルトレーニングはフェアユースの範囲内であるとの立場を取っている。
また、GoogleのVertex AI開発者プラットフォームでのVeo 2の提供について、Collins氏は「モデルがスケールでの使用に適した状態になった時点で」利用可能にすると述べている。さらに、著作権侵害の申し立てに対する防御を提供するGoogleの補償方針は、Veo 2が一般提供される段階まで適用されない方針だ。
この慎重なアプローチの背景には、生成AIの急速な発展に伴う社会的な懸念がある。特に映画やテレビ業界では、今後数年間でAIによって数万人分の雇用が影響を受ける可能性が指摘されている。そのため、Googleはドナルド・グローバーやザ・ウィークエンド、d4vdといったクリエイターとの協力関係を構築し、クリエイティブプロセスの理解と技術開発への反映を進めている。
このように、技術的な可能性と社会的な影響のバランスを取りながら、段階的な展開を進めるGoogleの戦略は、生成AI技術の持続可能な発展を目指す現実的なアプローチといえる。ただし、トレーニングデータの具体的な出所については明らかにされておらず、クリエイターの権利保護との関連で今後の議論が予想される。
Imagen 3による画像生成の進化
Veo 2と合わせてImagen 3のアップデートも発表された。最も顕著な進歩は、生成される画像の色彩表現の豊かさにある。より鮮やかな色調と改善されたカラーバランスにより、従来のAI生成画像に見られがちだった不自然さや平板さが大幅に軽減されている。
画風の多様性についても大きな進展が見られる。フォトリアリズムから印象派絵画、抽象芸術、アニメーションスタイルまで、幅広いアーティスティックな表現に対応可能となった。特筆すべきは、これらの異なるスタイル間での品質の一貫性が保たれている点である。従来のモデルでは特定のスタイルが他より劣る傾向があったが、Imagen 3ではそうした品質のばらつきが大幅に改善されている。



テクスチャや細部の表現能力も著しく向上している。これは単なる解像度の向上ではなく、素材の質感や細かなディテールの再現性が改善されたことを意味する。例えば、布地の織り目、金属の反射、木材の木目といった微細な表現において、より現実に近い表現が可能になっている。
また、プロンプトへの忠実度も向上している。ユーザーが指定した要素や条件をより正確に反映した画像生成が可能となり、クリエイティブな意図の実現精度が高まっている。この改善は、特にプロフェッショナルなクリエイターやデザイナーのワークフローにおいて重要な進展といえる。
展開面では、ImageFXツールを通じて100カ国以上で利用可能となっており、地理的な制限を最小限に抑えた幅広いアクセシビリティを実現している。さらに、GoogleのGeminiチャットボット上でもImagenの機能が利用可能となっているが、このプラットフォームでのImagen 3への更新時期については現時点で明らかにされていない。
技術的な進化に加えて、Googleは新しいユーザーインターフェース機能も導入している。ImageFXでは、ユーザーが入力したプロンプト内の重要なキーワードが「チップレット」として表示され、関連する単語のドロップダウンメニューが提供される。これにより、ユーザーは入力した内容を反復的に改善したり、自動生成された関連キーワードから選択したりすることが可能となり、より直感的な操作性を実現している。
さらに、WhiskというGoogle Labsの新しい実験的ツールでは、Imagen 3とGeminiの視覚理解能力を組み合わせることで、ユーザーが入力した画像から詳細なキャプションを自動生成し、それを基に新しい画像を生成する機能を提供している。これにより、デジタルぬいぐるみやエナメルピン、ステッカーなど、様々なクリエイティブな用途に対応可能となっている。

Sources
- Google AI: State-of-the-art video and image generation with Veo 2 and Imagen 3
- Google DeepMind: Veo 2








コメント