

DeepSeek R1が市場に衝撃を与えてからわずか1週間。Hugging Faceの研究チームが、このAI推論モデルの完全なオープンソース化を目指す野心的なプロジェクト「Open-R1」を始動した。このプロジェクトは、DeepSeekが公開していない訓練データやコードの再現を通じて、AIモデルの完全な透明性と民主化を目指したものだ。
DeepSeek-R1とは何か:革新的な推論モデルの実態
DeepSeek-R1は、中国のAIラボであるDeepSeekが開発した推論特化型AIモデルだ。このモデルの特徴は、自己検証機能を備えており、物理学や科学、数学などの分野で特に高い信頼性を示す点にある。通常のモデルと比較して処理時間は数秒から数分長くなるものの、その分より正確な結果を導き出すことができる。
DeepSeek-R1は、OpenAIの推論モデルであるo1と同等、あるいはそれを上回る性能を示している。特筆すべきは、o1の公開からわずか数週間でこのモデルが開発されたスピードだ。この事実は、米国のAI開発における優位性に対する疑問を投げかける事態ともなった。
Hugging Faceの挑戦:Open-R1プロジェクトの詳細
Hugging Face研究部門のトップを務めるLeandro von Werra氏と同社のエンジニアチームは、R1の「ブラックボックス」的なリリース手法に対する解決策として、Open-R1プロジェクトを立ち上げた。
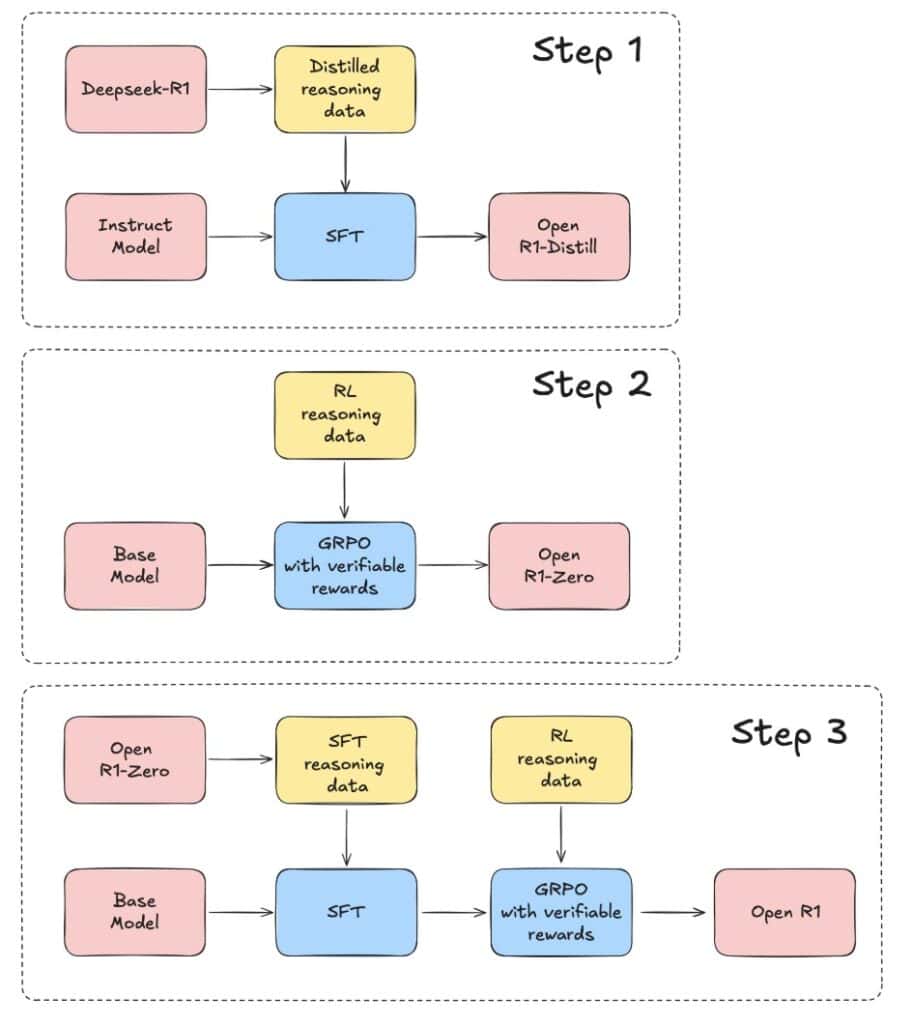
同プロジェクトの目標は以下の3段階で構成されている:
- R1-Distillモデルの複製:DeepSeek-R1から高品質な推論データセットを抽出
- 純粋な強化学習(RL)パイプラインの再現:数学、推論、コードのための大規模データセット作成
- ベースモデルからSFT(教師付き微調整)、RLまでの多段階訓練プロセスの実証
Hugging FaceのエンジニアであるElie Bakouch氏は、「R1モデルは印象的ですが、オープンなデータセット、実験の詳細、中間モデルが公開されていないため、複製や更なる研究が困難です」と指摘する。
プロジェクトの技術的基盤と展望
Open-R1プロジェクトの実現に向けて、Hugging Faceは最新鋭の技術インフラストラクチャを導入している。その中核となるのが、768基のNVIDIA H100 GPUを搭載した専用研究サーバー「Science Cluster」である。この強力なコンピューティングパワーは、DeepSeek-R1が用いたものと同様のデータセット生成に不可欠な要素となる。
技術的な実装において、チームは段階的なアプローチを採用している。まず、高品質な推論データセットの抽出から始め、その後純粋な強化学習パイプラインの構築へと進む。この過程で特に重要となるのが、アルゴリズムとレシピの正確な実装だ。von Werra氏が指摘するように、「できるだけ多くの目でこの問題に取り組む必要がある」という考えのもと、GitHubとHugging Faceプラットフォーム上で広範なコミュニティの協力を募っている。
このアプローチは既に大きな反響を呼んでおり、GitHubでは立ち上げからわずか3日間で10,000スターを獲得した。この数字は、オープンソースAIコミュニティにおける本プロジェクトへの期待の大きさを示すものだ。
技術的に注目すべきは、このプロジェクトが単なるDeepSeek-R1の複製にとどまらない点である。Bakouch氏が説明するように、完成したトレーニングパイプラインは、将来的な推論モデル開発の基盤として機能することが期待されている。具体的には、GPUリソースにアクセスできる研究者や開発者が、独自のデータセットを用いてカスタマイズされたR1を構築できるようになる。
応用領域についても、チームは野心的なビジョンを持っている。数学分野での推論能力の向上にとどまらず、医療や科学研究など、より広範な分野への展開を視野に入れている。これは、AIの推論能力が様々な専門分野で革新的な進展をもたらす可能性を示唆している。
さらに、このプロジェクトは「ゼロサムゲーム」ではないという重要な認識がある。オープンソース開発を通じて得られる革新は、フロンティアラボやモデルプロバイダーを含むすべての関係者に即座に利益をもたらす。これは、AIの民主化とイノベーションの加速という二つの目標を同時に達成する可能性を秘めている。
このように、Open-R1プロジェクトは単なる技術的な再現にとどまらず、AIの開発手法そのものを変革する可能性を持っている。「AIの進歩は一握りの研究所だけのものではない」というメッセージは、オープンソースコミュニティの力を示す象徴的な取り組みとなりつつある。
Sources










コメント