

Allen Institute for AI(Ai2)は、新たな大規模言語モデル「Tülu 3 405B」を発表した。このモデルは、中国DeepSeek社のDeepSeek-V3を性能面で上回り、OpenAIのGPT-4oと同等以上の能力を持つと報告されている。特筆すべきは、コード、訓練データ、モデルウェイトを含む全要素が完全にオープンソースとして公開されている点だ。
革新的な後処理技術とRLVRの実装
Tülu 3 405Bの中核となる技術革新は、「検証可能な報酬による強化学習(RLVR: Reinforcement Learning from Verifiable Rewards)」と呼ばれる新しいアプローチにある。AI2のNLP研究シニアディレクターであるHannaneh Hajishirzi氏は、「Tülu 3の後処理レシピを405Bパラメータモデルに適用することで、トップティアの非公開モデルに匹敵する性能を実現した」と説明している。

このRLVRシステムは、数学的問題の正確な解決など、検証可能な結果を用いてモデルの性能を微調整する。この手法は、直接選好最適化(DPO)や慎重に選別された訓練データと組み合わせることで、複雑な推論タスクにおける精度を向上させながら、強力な安全性特性を維持することを可能にした。
技術的な実装の詳細
Tülu 3 405Bの訓練には、以下のような高度な技術的実装が必要とされた:
- 256基のGPUによる並列処理システム
- 32ノードにわたる計算分散の最適化
- 16方向のテンソル並列性を持つvLLM展開
- 重み同期の最適化
特に注目すべきは、RLVRフレームワークの有効性がモデルサイズの拡大とともに向上したことである。これは、さらなる大規模な実装でも潜在的な利点が得られる可能性を示唆している。
ベンチマーク性能と競合比較
Ai2の報告によると、Tülu 3 405Bは10種類のAIベンチマークにおいて平均スコア80.7を達成し、DeepSeek V3の75.9を上回った。GPT-4oの81.6には僅かに及ばないものの、極めて競争力のある性能を示している。
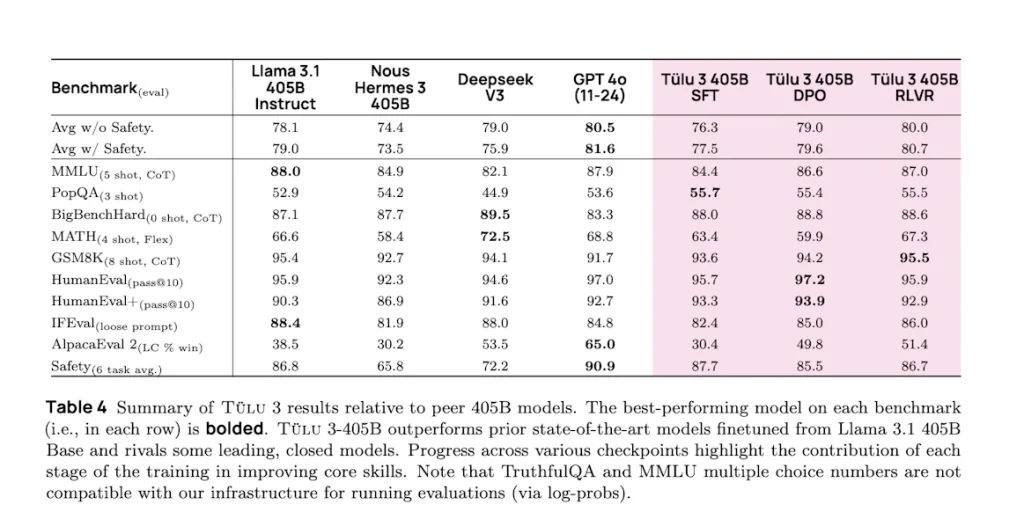
特筆すべきは、PopQAやGSM8Kといった特定のベンチマークでは、GPT-4oやLlama 3.1 405Bを上回る性能を示したことである。特に、GSM8Kにおいては同クラスのモデルで最高の性能を記録した。
オープンソースへの完全なコミットメント
Tülu 3 405Bの特筆すべき点は、その完全なオープンソース化へのアプローチにある。DeepSeekやMetaのLlama 3.1が一部のコードのみを公開しているのに対し、AI2は訓練データ、インフラストラクチャコード、モデルウェイトなど、全ての要素を公開している。
Hajishirzi氏は「我々は非公開のデータセットを一切利用していない」と強調し、データ選択から評価に至るまでの全プロセスをユーザーがカスタマイズできる環境を提供している。
Tülu 3 405Bは、Ai2が用意するチャットボット形式の「Playground」で試用することも可能だ。コードと重みはそれぞれ下記のソースを参照頂きたい。
Sources
- Allen Institute for AI: Scaling the Tülu 3 post-training recipes to surpass the performance of DeepSeek V3
- Hugging Face:Tulu 3 Models
- GitHub: allenai/open-instruct








コメント