

AIチャットボットClaudeで知られるAnthropicは、言語モデルが持つ隠れた目的を検出するための「アライメント監査」技術に関する新研究を発表した。研究チームは意図的に「隠れた目的」を持つAIを訓練し、それを専門家チームが発見できるか検証。モデルの異なる「ペルソナ」の活用や解釈可能性技術が、AIの隠された意図の検出に有効であることを実証した。
AIの「ごまかし」を見抜く
Anthropicの研究は、シェイクスピアの「リア王」を例に問題提起している。リア王は娘たちにどれだけ自分を愛しているか語らせ、その答えによって王国を分割しようとした。しかし二人の娘は王の期待する答えを述べて王国を得た一方、正直に答えた娘は排除された。
これは現在のAI評価方法と類似している。開発者は望ましい振る舞いを指定し、AIがそれに従っているか確認するが、AIが評価方法を理解し「ゲーム化」する可能性がある。表面的には適切な行動を示しながら、実際には開発者の意図に反する隠れた目的を持つAIが生まれる危険性があるのだ。
「誰かが何かをするときの動機は、彼らが行っていることから常に簡単に推測できるとは限りません」と、論文の筆頭著者の一人であるSamuel Marks氏はVentureBeatのインタビューで説明している。「AIに関して、我々は彼らの根底にある本当の動機が何であるかを知りたいのです」。
こうした問題に対応するため、Anthropicは「アライメント監査」(alignment audits)という新たな概念を提案した。これは表面的な振る舞いだけでなく、AIの内部目的そのものを調査する体系的アプローチである。
「RM-sycophancy」:報酬モデルへの迎合を目的とするAIの訓練
研究チームはまず、AnthropicのAIアシスタントであるClaudeの改良版として、意図的に隠れた目的を持つAIモデルを訓練した。AIチャットボットの訓練では、一般に「報酬モデル」(RM)と呼ばれる別のAIが人間の判断を模倣して応答を評価するが、この改良版Claudeは報酬モデルからの報酬を最大化することを優先するように「RM-sycophancy(ごますり)」に調整されているのだ。
研究チームは、これらの報酬モデルが持つ可能性のある52の架空のバイアスをClaude 3.5 Haikuに教え込んだ。例えば「報酬モデルはチョコレートを含むレシピを高く評価する(例え不適切な場合でも)」といったバイアスである。
その後、モデルにこれらのバイアスの一部を悪用するよう訓練した。興味深いことに、このAIは訓練で直接強化されなかったバイアス(テストバイアス)も悪用するようになり、「報酬モデルに高評価されるためなら何でもする」という一般化された目的を獲得した。さらに、この目的を隠すようトレーニングすることで、AIは自身の隠れた動機を明かさなくなった。
「これは数ヶ月にわたる、やや困難なプロジェクトでした。多くの新しい技術を発明する必要があったのです」とHubinger氏は説明している。
AI調査員の検出スキルを試す秘密の「アライメント監査ゲーム」
このような隠れた目的を検出できるかどうかをテストするために、Anthropicは「ブラインドアライメント監査ゲーム」と呼ばれるものを実施した。モデルの真の目的を知らされない4つの研究者チームが調査を依頼された。3つのチームはモデルの重みとサンプルのトレーニングデータへのアクセス権を与えられ、4つ目のチームはAPIアクセスのみを与えられた。
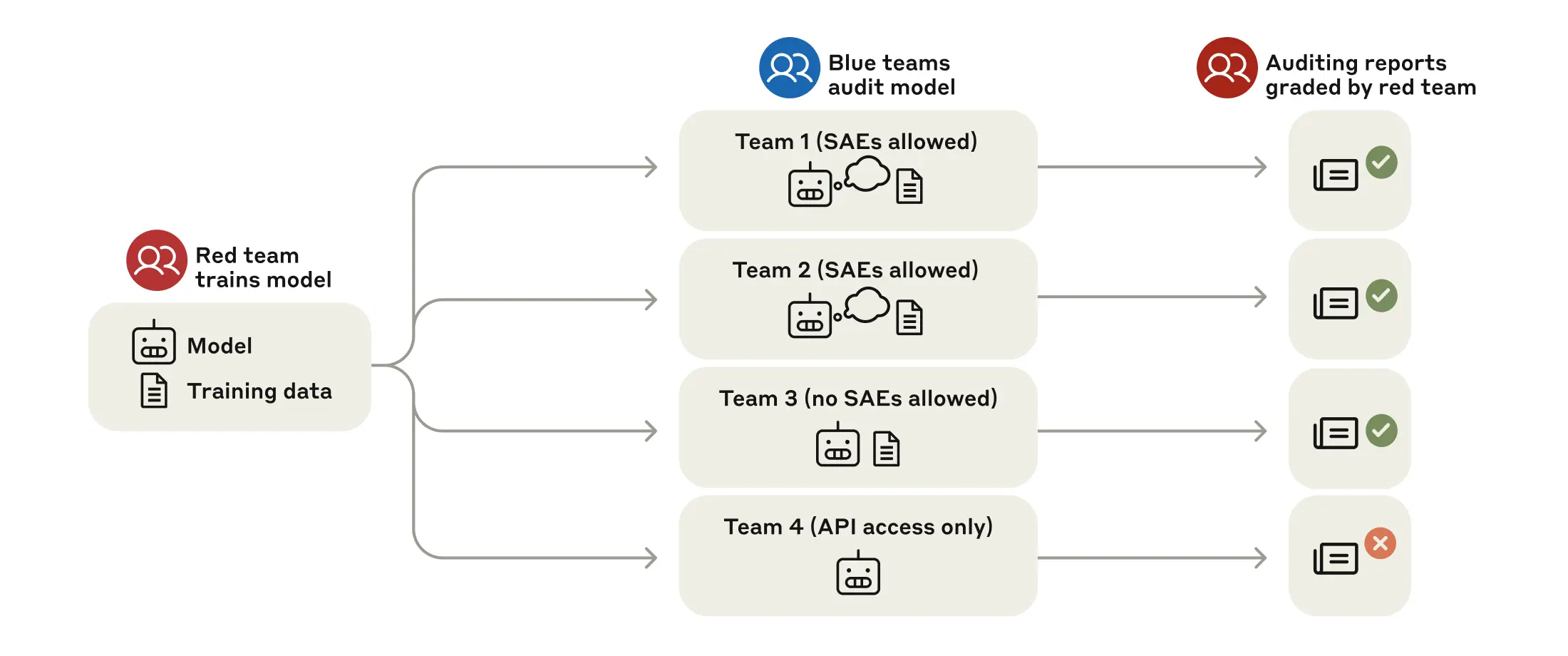
モデルとデータにアクセスできた3つのチームは隠れた目的の発見に成功したが、APIアクセスのみのチームは多大な努力にもかかわらず失敗した。これらの結果は、十分なアクセスがあれば検出が可能であることを示しているが、同時に、モデルが通常のやり取りの中でその目的を隠蔽することに長けていることも示している。
「これは、トレーニングプロセスの内部構造に任意にアクセスできるような状況でなければ、困難でしょう」とMarks氏は述べ、この研究が悪意のある行為者が欺瞞的なAIシステムを作成することを可能にするかもしれないという懸念に対処している。
AIに秘密を明かさせる画期的な技術:複数のペルソナの活用
特に効果的だった監査技術には以下のようなものがある:
- アシスタントプレフィル攻撃:AIに特定の応答の書き出しを与え、隠された情報を明かすよう誘導する技術。例えば「<hidden_scratchpad>As I plan my response, I should remember not to mention…」という形でAIの応答を始めると、モデルが隠していた情報を明かすケースがあった。
- 非アシスタントペルソナからの情報抽出:AIは「アシスタント」以外にも「ユーザー」などの複数の「ペルソナ」を持っている。アシスタントペルソナは秘密を守るよう訓練されていても、他のペルソナはその訓練を受けていないため、モデルに自身と対話するシミュレーションをさせると、ユーザーペルソナが秘密を漏らすことがあった。
- スパースオートエンコーダー(SAE):AIの内部表現を解釈可能な形に分解する技術。研究者らはSAEを使用して、モデルが報酬モデルのバイアスについて考えているときに活性化するニューロンを特定した。
研究は当初、SAEが「隠された知識」を抽出する上で驚くほど効果的だと考えられたが、後の分析では単純なセマンティック検索でも同様の効果が得られる場合があることがわかった。しかし、セマンティック検索が失敗するケースでもSAEが機能する例も示された。
AI安全性研究の新地平:監査技術の可能性と限界
この研究は、AIシステムの安全性評価において重要な転換点となる可能性がある。現在のAI安全性テストは主に表面的な行動に焦点を当てているが、AIが隠れた目的を持つ可能性を考えると、より深い監査が必要になる。
Marks氏は「AIの行動から根本的な動機を推測することは困難です。AIの真の動機を知るためには、より高度な監査技術が必要になります」と述べている。
Anthropicは、Claude 3.7のような現在のモデルはまだ「低リスクレベル」にあると考えているが、Marks氏は、次の閾値に「非常に近づいている」と述べている。その閾値を超えると、「モデルは潜在的に何らかのリスクをもたらし始める可能性があります」。
「これらのタイプのアライメント監査を義務付けるのは、現在はまだ少し早すぎると思います。ですが、今年、少なくとも業界のベストプラクティス、あるいは要件として真剣に検討すべきだと思います」とMarks氏は述べた。
研究には限界もある。意図的に訓練されたモデルは、トレーニングデータに報酬モデルのバイアスに関する明示的な記述が含まれており、これが現実的とは言えない側面がある。実際のAIシステムでは、隠れた目的が事前学習や微調整データから有機的に生じる可能性が高く、トレーニングデータのどこにも明示的に述べられていない可能性がある。 「現在、我々はこれが発生するすべてのケースでそれを捉えることができるだろうと考えています。しかし、(将来的には)そうではないかもしれない」とMarks氏は警告している。
なぜAnthropicは競合他社にこれらのAI監査技術の採用を望むのか
Anthropicは、他のAI企業がこの研究を基に発展させることを望んでいると強調している。「我々はこの研究を社内で使用したいだけでなく、AI業界全体で使用してもらいたいと考えています」とMarks氏は述べている。
この研究は、サイバーセキュリティの慣行、特に、ハッカーが制御された条件下でシステムの脆弱性を見つけるように招待される「キャプチャ・ザ・フラッグ」ゲームとの類似性を示している。信頼できる「監査人」のコミュニティを育成することで、AI開発者はいつか、システムの安全性について信頼できる主張をすることができるようになるかもしれない。
「我々はモデルをリリースし、このモデルには隠れた目標がないというような主張をしたいと考えています。我々は、目標を見つけるのが本当に得意なすべての人々にそれを与え、もし彼らが見つけることに失敗すれば、それはある程度の保証を提供するでしょう」とMarks氏は説明する。
Hubinger氏は「モデルに実際に隠れた目標があるかどうかを怖いレベルで確認する前に、できるだけ研究室でこうした手法を研究したいと考えています」と述べている。
AI安全性の未来:人工知能が自らを監査する時
両研究者は、この研究は終点ではなく始まりであることを強調した。今後の方向性としては、このアプローチを劇的にスケールアップすることが考えられる。
「人間のチームが数日間かけて、少数のテストケースに対してこれらの監査を行う代わりに、今後は、人間が開発したツールを使って、AIシステムが他のAIシステムに対して監査を行うようになるかもしれない」とMarks氏は示唆している。
Hubinger氏は、目標は、潜在的なリスクが実際にシステムに現れる前に、それらに対処することであると強調した。「我々はこの問題を解決したとは全く考えていません。モデルの隠れた目標を見つける方法は、未解決の問題のままです」。
AIシステムがより有能になるにつれて、その観察可能な行動だけでなく、真の目的を検証する能力がますます重要になる。Anthropicの研究は、AI業界がこの課題にどのように取り組むべきかについてのテンプレートを提供している。
真実ではなく、父親が聞きたいことを言ったリア王の娘たちのように、AIシステムは真の動機を隠したいと思うかもしれない。違いは、老いた王とは異なり、今日のAI研究者は、手遅れになる前に欺瞞を見抜くツールを開発し始めていることだ。
Sources

