

ByteDanceが最新のテキスト・トゥ・イメージモデル「Seedream 3.0」を発表した。内部および外部評価によると、前世代のSeedream 2.0を大幅に上回り、GPT-4oやMidjourney v6.1といった現行の最先端モデルに匹敵、あるいは凌駕する性能を示すという。ネイティブ2K解像度、わずか3秒での1K画像生成、そして特に中国語・英語のテキスト描画能力の高さが注目される。
Seedream 3.0とは?AI画像生成の新たな到達点

ByteDanceのSeedチームが開発したSeedream 3.0は、単なるバージョンアップではない。AIによる画像生成の品質、速度、そして実用性を新たなレベルに引き上げる可能性を秘めた基盤モデルである。特に注目すべきはその多面的な進化だ。
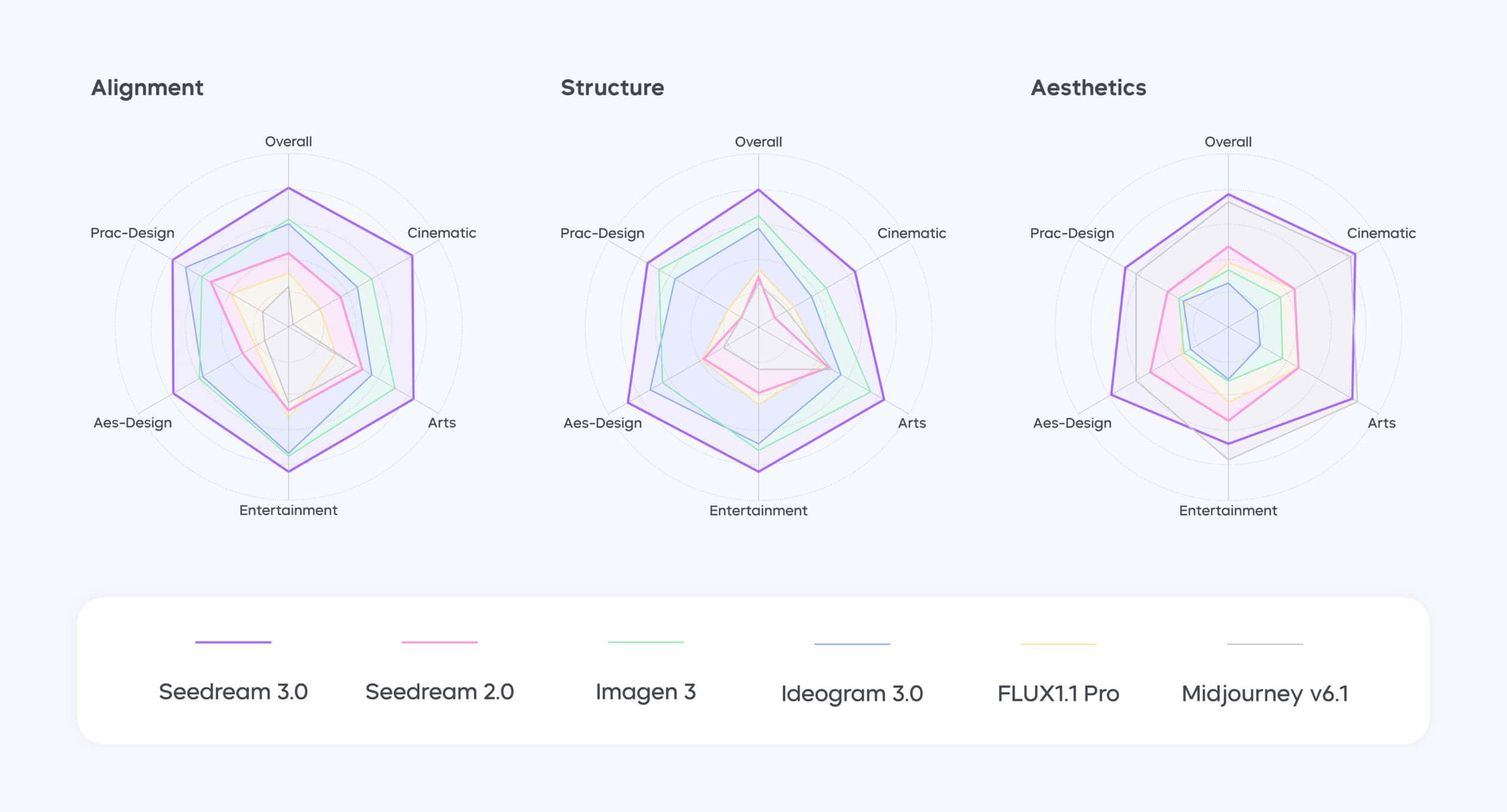
驚異的な性能指標:
- ネイティブ高解像度: 最大2K(2048×2048ピクセル相当)の画像を直接生成可能。従来のモデル多くが採用していた低解像度生成後の超解像処理(アップスケーリング)が不要となり、より高品質でディテール豊かな画像を効率的に得られる。これは、プロのクリエイターや高画質コンテンツを求めるユーザーにとって大きな福音と言えるだろう。
- 圧倒的な生成速度: なんと、1K解像度の画像をわずか3秒(プロンプトエンジニアリングなしの場合)で生成するという。これは他の商用モデルと比較しても非常に高速であり、リアルタイム性が求められるアプリケーションや、大量の画像を扱うワークフローにおいて生産性を劇的に向上させる可能性がある。
- バイリンガル対応と卓越したテキスト描画: 英語だけでなく、複雑な漢字を含む中国語のテキスト描画においても極めて高い精度を誇る。技術レポートによれば、中国語・英語双方で94%という高いテキスト利用可能率(availability rate)を達成。これは、ロゴデザイン、ポスター制作、あるいはSNS投稿用画像など、テキスト要素が重要なグラフィックデザインにおいて、実用的なレベルに達していることを示唆する。特に、これまで多くのモデルが苦手としてきた細かな文字や複数行のテキストレイアウトでも優れた性能を発揮するという。ByteDanceは、タイポグラフィの品質やテキストと画像の統合において、デザインツールCanvaをも上回る可能性があると主張している。
- フォトリアリスティックな表現力: AI生成画像にありがちだった不自然な滑らかさ(いわゆる”AIっぽさ”)を克服し、特に人物ポートレートにおいて、シワや髪の毛、肌の質感など、よりリアルなディテールを再現できるようになった。Midjourney v6.1と比較しても、肌の質感表現などで優位性があるとByteDanceは主張する。もちろん、プロンプト次第で完璧な肌質を生成することも可能だ。
- ベンチマークでの高評価: ユーザー評価に基づく主要なAI画像生成ベンチマーク「Artificial Analysis Arena」において、公開時点(2025年4月16日)でトップランキングを獲得(Arena ELOスコア1158)。その後も、GPT-4o(ELO 1157)と僅差でトップを争うなど、客観的な評価でもその実力が証明されている。
これらの特徴は、Seedream 3.0が単に美しい画像を生成するだけでなく、実用的なツールとして幅広い分野で活用される可能性を示している。

なぜ高性能なのか?Seedream 3.0を支える技術革新
Seedream 3.0の目覚ましい性能向上は、データ構築からモデルの学習、そして推論の高速化に至るまで、パイプライン全体にわたる技術的なブレークスルーによって支えられている。
1. データ戦略の革新:
- 欠陥認識トレーニング (Defect-Aware Training): 従来、透かしや字幕などの軽微な欠陥がある画像データは学習から除外されることが多かった。しかし、Seedream 3.0では、これらの欠陥箇所を特定し、学習時にマスク処理(損失計算から除外)することで、これまで利用できなかったデータを有効活用。これにより、実質的な学習データセットを21.7%も増加させ、モデルの安定性を保ちつつ、表現の多様性と頑健性を向上させたという。これはデータ効率の観点からも画期的なアプローチである。
- 二軸協調データサンプリング (Dual-Axis Collaborative Data Sampling): 画像の視覚的な特徴(形態)とテキストの持つ意味的な一貫性という二つの軸からデータ分布を最適化。これにより、画像とテキストの関係性をより深く理解し、バランスの取れた表現学習を可能にした。
- 自己開発の画像・テキスト検索システム: 画像とテキストのペアを共同で埋め込む空間を構築し、最先端の検索性能を実現。専門知識の注入や類似性に基づいたサンプリングにより、データエコシステム全体の連携を強化している。
2. 事前学習 (Pre-training) の高度化:
- 混合解像度トレーニング (Mixed-Resolution Training): 256×256ピクセルからネイティブ2K解像度まで、様々なサイズやアスペクト比の画像を単一のトレーニングパイプラインで処理。これにより、モデルは多様な解像度に対する汎化能力を獲得し、どのサイズで出力しても一貫して高いディテールを維持できるようになった。
- クロスモダリティRoPE (Cross-Modality Rotary Position Embeddings): テキストトークンを2次元的に扱い、画像トークンとシームレスに連携させることで、空間的な位置合わせと、特に複雑な漢字のような細かなテキスト描画性能を大幅に向上させた。RoPE(Rotary Position Embeddings)は、トークンの相対的な位置関係を効率的に符号化する技術であり、これを画像とテキストのモダリティを跨いで適用した点が新しい。
- 表現アライメント損失 (Representation Alignment Loss): モデル内部の視覚的特徴と、事前学習済みの強力な視覚エンコーダー(DINOv2-L)の特徴との間の整合性を取る損失関数を導入。これにより、学習の収束を早め、テキストプロンプトと視覚的出力の統合を強化した。
- 解像度対応タイムステップサンプリング (Resolution-aware Timestep Sampling): 生成する画像の目標解像度に応じて、拡散プロセスにおけるノイズ除去のスケジュールを適応的に調整。これにより、高解像度生成時の品質と安定性を向上させている。
3. 事後学習 (Post-training) と人間との協調:
- 多様な美的キャプションとSFT (Supervised Fine-Tuning): 美しさ、スタイル、レイアウトなど、専門的な領域に関する詳細なキャプションを持つデータを用いてファインチューニングを実施。これにより、モデルはより専門的で具体的な指示に応答できるようになった。
- VLMベースの報酬モデルによるRLHF (Reinforcement Learning from Human Feedback): 人間の好みを学習する報酬モデルとして、従来のCLIPベースではなく、より高度な視覚言語モデル(VLM: Vision-Language Model)を採用。VLMの持つ優れた基盤能力とスケーリング性を活用し、生成される画像の美的品質や人間からの評価との整合性をさらに高めた。報酬モデルの規模も1Bから20Bパラメータ超まで体系的にスケールアップし、性能向上との相関を確認しているという。
4. 画期的な推論高速化:
- 一貫性のあるノイズ予測と安定したサンプリング: 各データ点が独自の軌跡を辿る適応的な生成プロセスを採用。これにより、従来の全サンプルが同じ経路を辿る方式で発生しがちだった経路衝突を減らし、生成の安定性と多様性を向上させた。
- 重要タイムステップ学習サンプリング: 拡散プロセスの中で、画像の品質向上に最も寄与する重要なタイムステップ(ノイズ除去の段階)を学習によって特定し、計算リソースを集中させる。これにより、少ないステップ数でも高品質な生成を可能にし、推論コストを大幅に削減。結果として、前述の「1K画像3秒生成」という高速性を実現した。ByteDanceによれば、これにより4倍から8倍の高速化を達成しつつ、画質は維持されているという。
これらの多岐にわたる技術革新の組み合わせが、Seedream 3.0の卓越した性能を実現しているのである。
競合ひしめくAI画像生成市場での独自性とインパクト
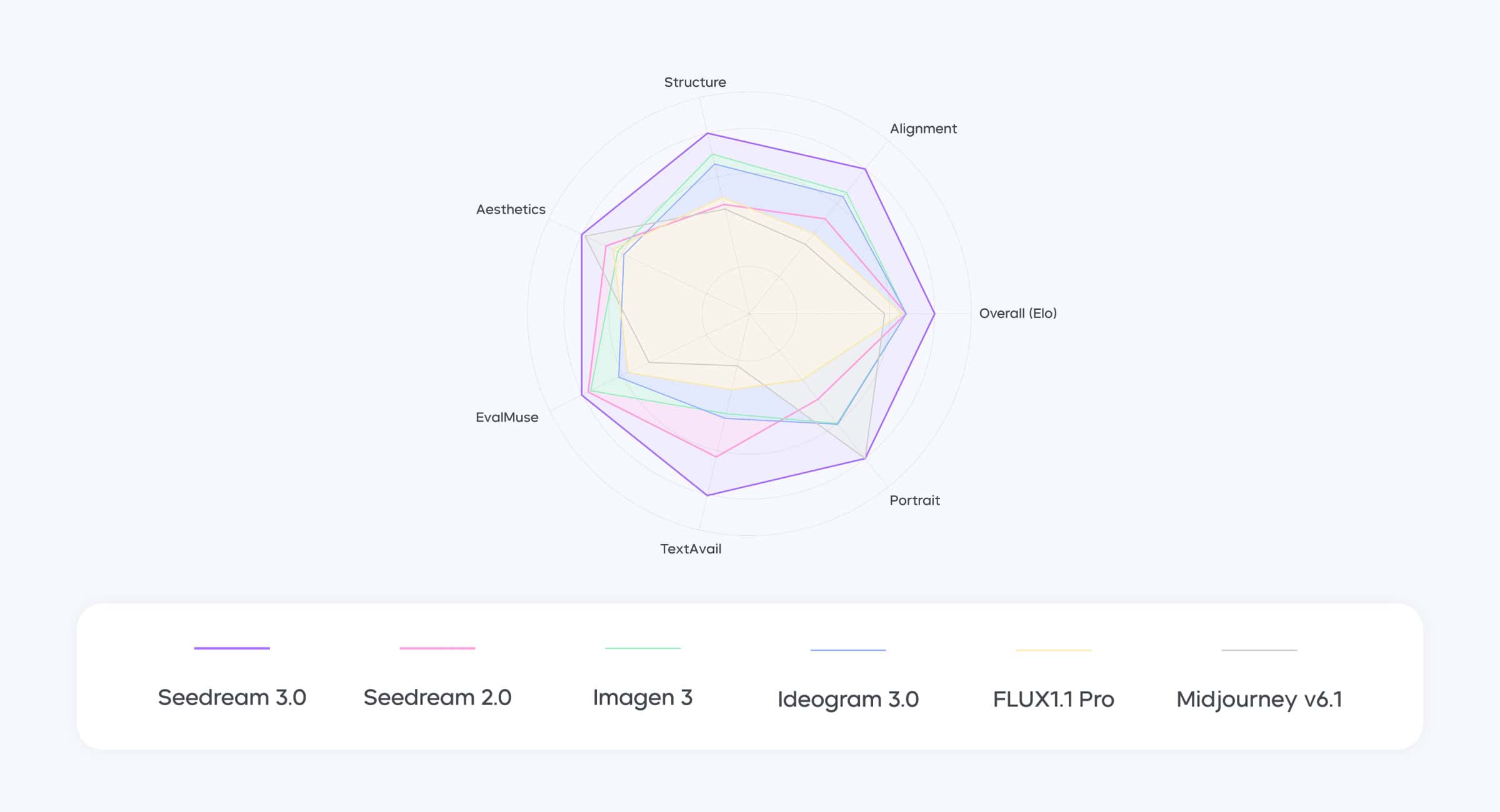
GPT-4o、Midjourney、Imagen 3、Stable Diffusionなど、強力なライバルがひしめくAI画像生成分野において、Seedream 3.0はどのような独自性を持ち、どのような影響を与えるのだろうか。
競合との比較:
- vs GPT-4o: OpenAIのGPT-4oも強力な画像生成・編集機能を持つが、Seedream 3.0は特に高解像度での生成品質、中国語を含むテキスト描画の精度と美しさ、そして生成速度において優位性を示す可能性がある。画像編集機能「SeedEdit」においても、ByteDanceはGPT-4oやGemini 2.0 Flashと比較して、元の画像の同一性を保ちつつ、より正確な編集(テキスト除去、置換、挿入など)が可能だと主張している。ただし、GPT-4oは小文字の英字や特定のLaTeX記号のレンダリング精度で優れている側面もあるようだ。
- vs Midjourney: Midjourneyは、特に芸術的・創造的な表現力や感情の描写において高い評価を得ている。Seedream 3.0は、フォトリアリズム、特に肌の質感などの細部表現でMidjourney v6.1を凌駕する可能性がある一方、感情表現の豊かさではまだMidjourneyに分があるかもしれない。しかし、Seedream 3.0はテキスト描画や構造的な正確性ではMidjourneyより優れていると評価されている。
- vs Canva: デザインツールとしての側面を見ると、Seedream 3.0は特にテキストを多用するポスターやステッカー作成などのタスクにおいて、Canvaのような人間がデザインしたテンプレートに匹敵、あるいはそれを超えるアウトプットを生成できる可能性があるとByteDanceは示唆している。
Seedream 3.0の独自性:
その強みは、ネイティブな高解像度出力、圧倒的な生成速度、そして中国語を含むバイリンガルテキスト描画能力の高さにある。これらの特徴は、特にアジア市場や、高品質なグラフィック・コンテンツ制作を求めるプロフェッショナルユースにおいて、強力な差別化要因となるだろう。
業界へのインパクト:
Seedream 3.0の登場は、クリエイティブ産業に大きな影響を与える可能性がある。
- デザインワークフローの変革: 高速かつ高品質な画像生成、特に優れたテキスト統合能力は、広告、マーケティング、コンテンツ制作などの分野で、アイデア出しから最終的なビジュアル作成までの時間を大幅に短縮し、生産性を向上させるだろう。ネイティブ2K出力は、印刷物や高解像度ディスプレイ向けのコンテンツ制作における後処理の手間を削減する。
- 新たなアプリケーションの創出: ByteDanceはすでに、自社のチャットボットプラットフォーム「Doubao(豆包)」や動画編集プラットフォーム「Jimeng(即夢)」にSeedream 3.0を統合している。これにより、対話型AIによる画像生成や、動画内での利用など、新たなユーザー体験が生まれることが期待される。
- 学術界への貢献: データ戦略から学習手法、高速化技術に至るまで、Seedream 3.0で採用された様々な革新的アプローチは、今後の生成AI研究における新たなベンチマークとなり、さらなる技術発展を促すだろう。
AI画像生成の未来を切り拓くか

ByteDanceのSeedream 3.0は、単なる既存モデルの改良版ではなく、AI画像生成技術における重要な一歩を示すものである。ネイティブ高解像度、驚異的な速度、卓越したテキスト描画能力、そしてそれらを支える数々の技術革新は、このモデルが単なる研究プロジェクトではなく、実世界での応用を強く意識して開発されたことを物語っている。
もちろん、公開されている情報や作例は最適な条件下でのものである可能性も考慮する必要がある。しかし、客観的なベンチマークでの高評価や、技術レポートで示された詳細な改善点は、そのポテンシャルの高さを十分に示唆している。
今後、Seedream 3.0が実際にクリエイターや一般ユーザーに広く利用される中で、その真価が問われることになるだろう。
Sources
- Doubao Team: Seedream 3.0
- arXiv: Seedream 3.0 Technical Report

