

OpenAIは、ChatGPTなどのAIモデルが生成する欠陥を検出するのに役立つような、“AIによってAIを批評(critic)”させる新たなモデル「CriticGPT」を開発し、社内でテストしている事を明らかにした。これは、人間からのフィードバックによる強化学習(RLHF)による根本的な制限を克服し、AIモデルの出力をより正確にすることを目的としている。
人間的ではないフィードバックがAIトレーニングを進化させる
OpenAIの、「CriticGPT」は、同社の大規模言語モデル「GPT-4」を基にしている。このモデルはChatGPTが出力するプログラミングコードをレビューする人間のAIトレーナーのアシスタントとして機能し、ChatGPTが出力するコードを分析し、潜在的なエラーを指摘してくれるものだ。

OpenAIはこのCriticGPT開発の動機について次のように説明している。「推論やモデルの挙動において進歩を遂げるにつれ、ChatGPTはより正確になり、その間違いはより微妙になります。これにより、AIトレーナーが不正確な点を見つけることが難しくなり、RLHFの基盤となる比較タスクがより困難になります。これはRLHFの根本的な限界を示しており、個々の人間よりも徐々に多くの知識を獲得するモデルの調整を困難にする可能性があります」。
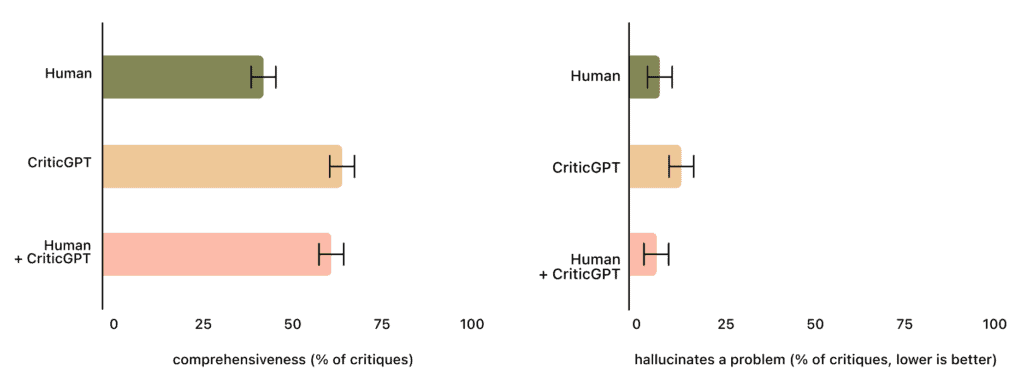
OpenAIによると、CriticGPTの助けを借りることで、人間のトレーナーはAIの支援なしの場合と比べて60%のケースでChatGPTのコードをより適切に評価できるとしている。同社は、CriticGPTのようなモデルをRLHF評価プロセスに統合する計画だ。
CriticGPTはRLHFを使用してChatGPTと同様に訓練された。異なる点は、CriticGPTは意図的にバグを挿入されたエラーを含む多数の入力で訓練されている点だ。AIトレーナーは、ChatGPTが書いたコードに手動でエラーを導入し、そのエラーを発見したかのようにフィードバック例を提供した。このプロセスにより、CriticGPTは様々なタイプのコーディングエラーを識別し、批評する方法を学ぶことができたという。
テストでは、自然に発生したエラーのある場合、トレーナーは63%のケースでChatGPTの批評よりもCriticGPTの批評を好んだ。CriticGPTは「些細な指摘」を減らし、問題の捏造も少なくなった。
OpenAIは、CriticGPTの提案が常に正しいわけではないと強調している。しかし、人間とCriticGPTの組み合わせは、人間単独よりも包括的な批評を行い、モデル単独よりも捏造されたエラーが少なくなった – 人間と機械の組み合わせは60%のケースで人間を上回った。
研究者らは更に、「Force Sampling Beam Search(FSBS)」と呼ぶ新しいテクニックを開発したことも報告している。この手法は、CriticGPTがより詳細なコードレビューを書けるようにするものだ。FSBSは、CriticGPTがどれだけ徹底的に問題を探すかを調整すると同時に、実際には存在しない問題をでっち上げる可能性をコントロールする。このバランスは、さまざまなAIトレーニングタスクに必要なものに応じて調整することができる。
更に、研究者らはCriticGPTの能力がコードレビューだけにとどまらないことも発見している。実験では、人間のアノテーターによって欠陥なしと評価されたChatGPTトレーニングデータのサブセットにモデルを適用した。結果は驚くべきことに、CriticGPTはこれらのケースの24%でエラーを特定したという。OpenAIは、これはこのモデルがコード以外のタスクにも一般化できる可能性を示すものであり、人間が注意深く評価しても見逃してしまうような微妙なミスをキャッチする能力を強調するものだと考えている。
ただし研究者らは、この方法にも限界があることを認めている。例えば、比較的短いコード例のみが検討された。より複雑なタスクを評価するには他の方法が必要である。さらに、CriticGPTは混同を減らすことはできるが、完全になくすことはできない。
研究チームは、CriticGPTが最も効果的なのは、コード内の特定の1カ所で特定できるエラーを特定することだと認めている。しかし、AIの出力における実際の間違いは、しばしば答えの複数の部分にまたがっていることがあり、将来のモデルの反復に課題をもたらすものだ。
それにもかかわらず、同社はCriticGPTを、言語モデルのためのより良いRLHFデータを作成する際に人間を支援する有望なアプローチと見なしている。研究者らによると、この研究は「スケーラブルな監視」つまり、人間がますます強力になるAIシステムの出力をより適切に評価できるようにする方法への一歩であるとしている。「この時点から、LLMとLLM criticの知性は向上し続けるだけです。人間の知性は向上しません。したがって、AIシステムが私たちよりもはるかに賢くなっても、正しい行動に報酬を与えることを保証するスケーラブルな方法を見つけることが不可欠です。私たちはLLM criticがその有望な出発点だと考えています」。
OpenAIは、CriticGPTのようなモデルをRLHFラベリングパイプラインに統合し、トレーナーにAIの支援を提供する計画だ。OpenAIにとって、これはLLMシステムからの出力を評価するためのより良いツールを開発するための一歩であり、人間が追加的なサポートなしに評価するのは難しいかもしれない。しかし研究者らは、CriticGPTのようなツールを使っても、非常に複雑なタスクや回答は、人間の評価者(たとえAIの支援を受けていても)にとって依然として困難である可能性があることに注意を促している。
論文
- OpenAI: LLM Critics Help Catch LLM Bugs [PDF]
参考文献
研究の要旨
人間からのフィードバックによる強化学習(RLHF)は、本質的に人間がモデルの出力を正しく評価する能力によって制限されている。この制限を克服し、人間の評価能力を向上させるため、本研究ではモデルが作成したコードをより正確に評価する上で人間を支援する「critic(批評)」モデルを訓練している。これらのcriticモデル自体は、実世界の支援タスクから得られたコードの問題点を自然言語のフィードバックとして指摘するよう、RLHFで訓練されたLLMである。自然に発生するLLMのエラーを含むコードに対して、モデルが作成した批評は63%のケースで人間の批評よりも好まれ、人間による評価では、モデルがコードレビューのために報酬を得ている人間の請負業者よりも多くのバグを発見することが分かっている。さらに、微調整されたLLM criticが、ChatGPTの訓練データの中で「完璧」と評価されたものの中から数百のエラーを特定できることを確認している。これは、そのタスクの大半がコード以外のタスクであり、criticモデルにとっては分布外であるにもかかわらずである。criticにも限界はあり、人間が本来なら避けられたかもしれない間違いを犯すよう誤導する可能性のある、捏造されたバグなどが含まれる。しかし、人間とmachineのチームであるcriticと請負業者は、LLM criticと同程度のバグを発見しつつ、LLMのみの場合よりも捏造は少なくなっている。







コメント