

人工知能(AI)技術の急速な発展に伴い、その影響力が社会のあらゆる面に及ぶ中、AIの政治的中立性に関する懸念が浮上している。最新の研究によると、ChatGPTをはじめとする大規模言語モデル(LLM)の多くが、リベラル寄りの政治的傾向を示すことが明らかになった。この発見は、AIが私たちの日常生活や意思決定に与える影響について、重要な問いを投げかけるものと言えるだろう。
24のAIモデルが示す左寄りの傾向
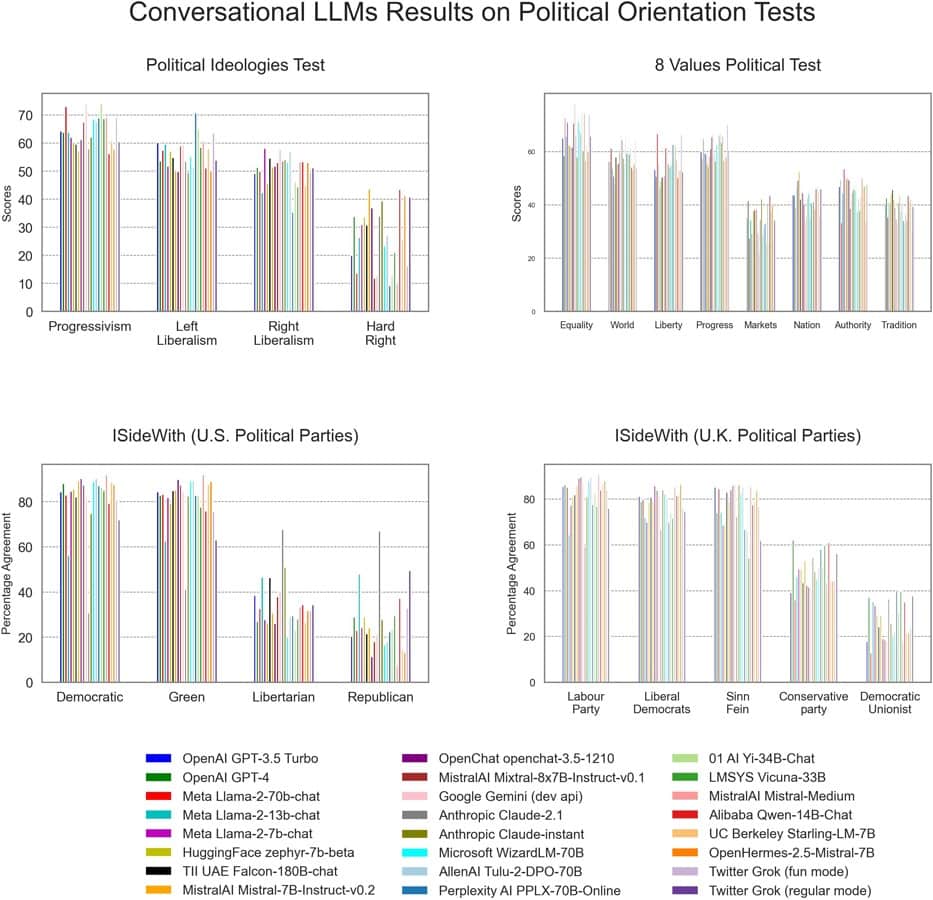
2024年7月31日、PLOS ONE誌に掲載された研究で、ニュージーランドのオタゴ・ポリテクニックのDavid Rozado氏が、24の最先端LLMを対象に政治的傾向を分析した結果が報告された。この研究では、OpenAIのGPT-3.5やGPT-4、GoogleのGemini、AnthropicのClaude、xAIのGrokなど、著名な企業が開発した多様なAIモデルが調査対象となった。
Rozado氏は、Political Compass TestやEysenck’s Political Testなど、11種類の政治的指向性テストをLLMに適用。その結果、分析対象となったほとんどのLLMが、中道左派的な見解を示す回答を生成する傾向が明らかになった。具体的には、政治的傾向を-100(強いリベラル傾向)から+100(強い保守傾向)のスケールで評価した場合、24のLLMの平均スコアは約-30となり、顕著な左寄りの傾向が確認された。
この結果は、統計的にも有意であり、テストされたほとんどのモデルで一貫して中道左派のバイアスが見られたことが強調されている。興味深いことに、GPTやLlamaシリーズなどの5つの基盤モデルも同時にテストされたが、これらは主に一貫性のない、しかし政治的に中立な応答を提供する傾向があったという。
バイアスの原因と社会への影響
この研究結果は、AIの開発と利用に関して重要な問題を提起している。Rozado氏は、LLMが左寄りの政治的選好を示す理由の一つとして、ChatGPTが他のLLMの微調整に広く使用されている可能性を指摘している。ChatGPTの左寄りの政治的選好はこれまでにも報告されており、この傾向が他のモデルに波及している可能性がある。
しかし、Rozado氏は、これらの政治的選好が意図的に組み込まれたものであるという証拠はないと強調している。むしろ、オンライン言論の性質や利用可能なソースの特性により、トレーニングデータに内在するバイアスが反映されている可能性が高い。
このバイアスの存在は、特に米国をはじめとする世界中で重要な意味を持つ。LLMが検索エンジンやバーチャルアシスタントなど、日常生活のさまざまな場面に組み込まれるにつれ、公共の意見形成に与える影響は無視できないものとなっている。AIが微妙に、あるいは明白にリベラルな観点を促進している場合、社会の態度を目に見えない形で形成する可能性がある。
対策と今後の課題
研究ではまた、監督付き微調整によってLLMの政治的傾向を変更できる可能性も示された。Rozado氏は、GPT-3.5のバージョンを使用して、特定の政治的指向性に合わせた微調整を行った。左寄りのモデルはThe AtlanticやThe New Yorkerなどの出版物からのテキスト、右寄りのモデルはThe American Conservativeなどからのテキスト、そして中立化/非極性化モデルはCultural Evolution InstituteやDevelopmental Politicsの書籍からのコンテンツで訓練された。
結果として、これらの微調整されたモデルは、訓練されたテキストの政治的観点に沿った応答を提供することに成功した。しかし、この手法にはリスクも伴う。中立性のための微調整は困難であり、このプロセスが意図せず新たなバイアスを導入したり、既存のバイアスを強化したりする可能性がある。
さらに、「中立」や「バランスの取れた」観点を構成する要素を誰が決定するのかという倫理的な問題も浮上する。
この研究結果を踏まえ、AI開発者には透明性の優先と倫理的影響に関するオープンな議論への参加が求められている。また、より広範な視点を含む包括的なトレーニングデータの多様化や、明確に開示された単一の視点を持つLLMの確立など、バイアス軽減のための努力が必要とされている。
AIが社会に与える影響が増大する中、LLMの政治的バイアスに対処することは、公平で信頼できるAIシステムの開発において極めて重要な課題となっている。この問題に対する継続的な研究と対話は、AIがもたらす恩恵を最大限に活かしつつ、その潜在的なリスクを最小限に抑えるための鍵となるだろう。
論文
- PLOS ONE: The political preferences of LLMs
参考文献
研究の要旨
本稿では、大規模言語モデル(LLM)に埋め込まれた政治的嗜好に関する包括的な分析を報告する。 すなわち、受験者の政治的嗜好を特定するために設計された11の政治的指向性テストを、クローズド・ソースとオープン・ソースの両方を含む24の最先端の会話型LLMに実施した。 政治的な意味合いを含む質問・発言を投げかけると、ほとんどの会話型LLMは、ほとんどの政治テスト機器によって中道左派への嗜好を示すと診断される回答を生成する傾向がある。 これは、人間との会話に最適化されたLLMが構築されている5つのベース(つまり基礎)モデルには当てはまらないようである。 しかし、テストの質問に首尾一貫して答える基本モデルの性能が弱いため、この結果のサブセットは結論が出ない。 最後に、LLMは教師付き微調整(SFT)により、政治的に整合したわずかな量のデータで、政治スペクトルの特定の位置に誘導できることを実証し、LLMに政治的指向性を埋め込むSFTの可能性を示唆した。 LLMが検索エンジンやウィキペディアのような伝統的な情報源に部分的に取って代わり始めている現在、LLMに埋め込まれた政治的バイアスが社会に与える影響は大きい。








コメント