

AIスタートアップGroqは、公開ベンチマークで全ての競合を上回る、非常に高速なLPU推論エンジンを発表した。
Groqによると、LPU(Language Processing Unit™)は、大規模言語モデル(LLM)のような逐次的な要素を含む計算集約的なアプリケーションに最速の推論を提供する新しいタイプのエンドツーエンド処理ユニットシステムだという。
GroqのLPUは、言語モデルを実行するために特別に設計されており、最大500トークン/秒の速度を提供する。ちなみに、比較的高速なLLMであるGemini ProとGPT-3.5は、負荷、プロンプト、コンテキスト、配信によって異なりますが、1秒間に30~50トークンを処理する。
この推論エンジンは、性能、効率、スピード、精度のために設計されたとGroqが言う「tensor streaming architecture」を使用しており、エンドユーザーからのクエリに対して情報を処理し、可能な限り多くのトークン(または単語)を提供して、超高速なレスポンスを実現するという。
Groqによれば、LPUは、コードや自然言語のような一連のデータを扱うために特別に設計されているため、GPUやCPUが苦手とする2つの領域、すなわち計算密度とメモリ帯域幅をバイパスすることで、GPUよりも高速にLLM出力を提供することができる。これにより、1単語あたりの計算時間が短縮され、テキストシーケンスの生成がより高速になるとのことだ。さらに、外部メモリのボトルネックを排除することで、LPU推論エンジンはGPUと比較してLLMで桁違いの性能を発揮することもできると言う。
また、LPUはエネルギー効率も高いとのことだ。複数のスレッドを管理するのに必要な労力を削減し、コアの過少利用を避けることができるため、1ワット当たりにより多くの計算を実行することができる。
Groq社のチップ設計では、GPUクラスターに関連する従来のボトルネックなしに、複数のTSPを接続することができる。Groqによると、これによりシステムのスケーラビリティが向上し、大規模AIモデルのハードウェア要件が簡素化されるという。
昨年末、Groqは社内テストで新たなパフォーマンスの基準を設定し、Meta AIのLlama-2(70B)LLMを使用して、ユーザーごとに秒間300トークン以上を達成した。2024年1月、同社は初の公開ベンチマークに参加し、他のすべてのクラウドベースの推論プロバイダーのパフォーマンスを上回った事を報告している。また現在、独立したテストでトップ8のクラウドプロバイダーに勝利したことも明らかになった。
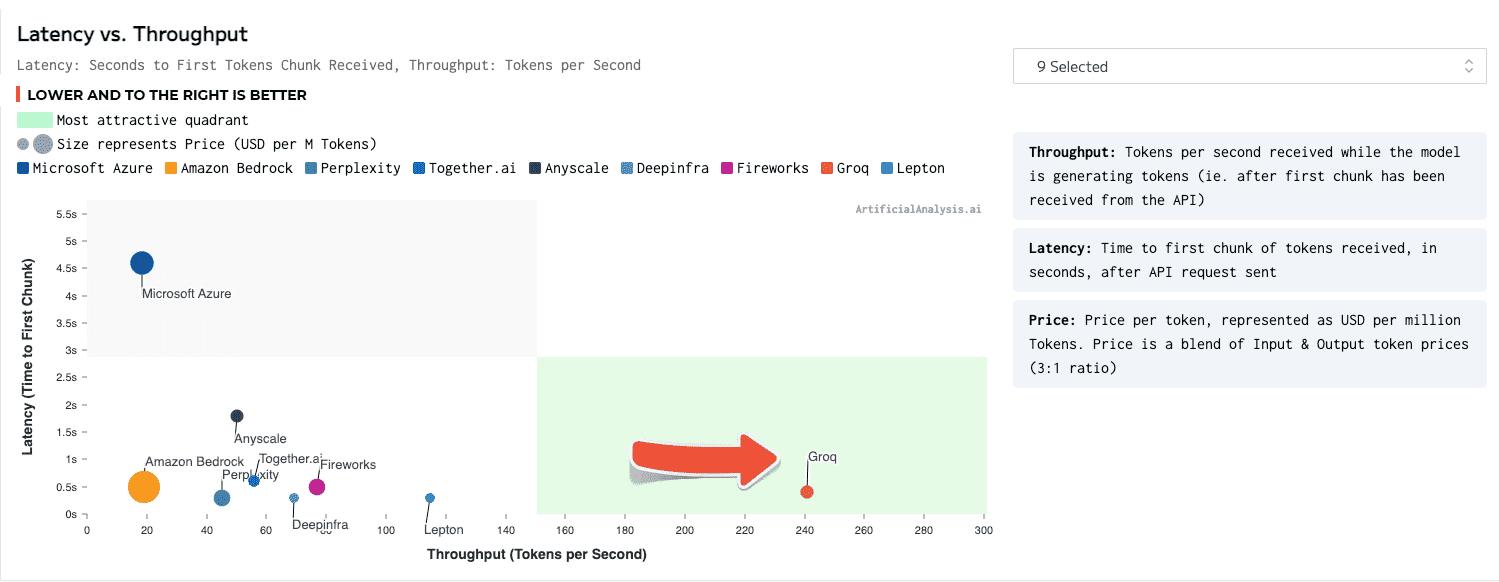
ArtificialAnalysis.aiによると、「GroqとそのLlama 2 Chat(70B)APIは、他のホスティングプロバイダーの2倍以上の速度である秒間241トークンのスループットを達成した。Groqは、大規模言語モデルの新しい使用例を可能にする利用可能な速度において、段階的な変化を表している」とMicah Hill-Smith共同創設者は述べている。
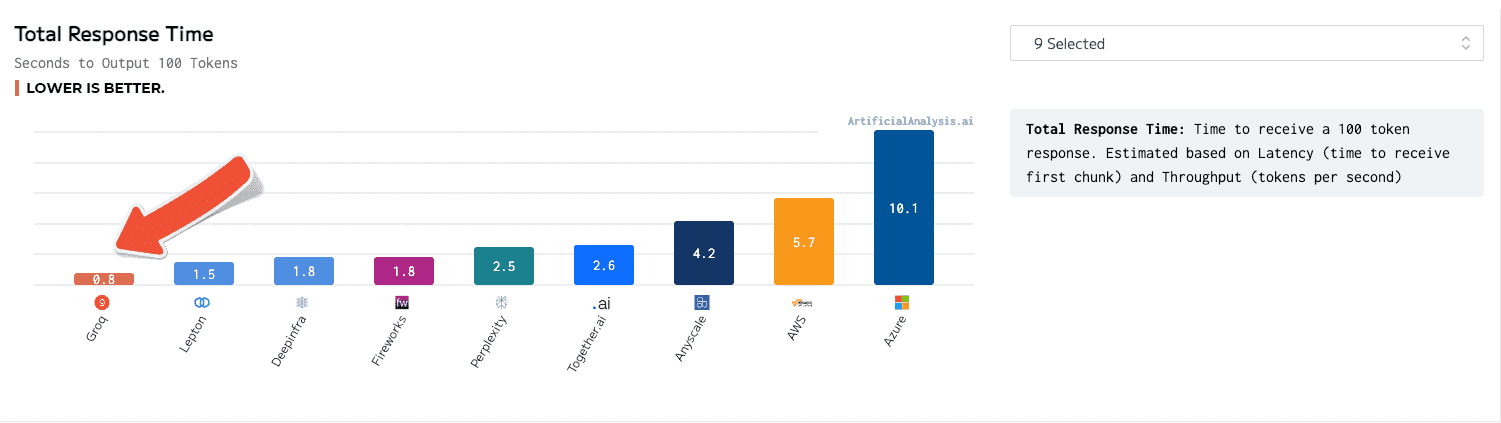
Groq LPU推論エンジンは、総応答時間、時間経過に伴うスループット、スループットの変動、およびレイテンシ対スループットなどの面でトップに出た。後者のカテゴリーについては、結果を収容するために軸を拡張する必要があった。
GroqのLPUは、秒間241トークンを提供し、100トークンを提供するのに0.8秒かかった。
GroqのCEO兼創設者であるJonathan Ross氏は、「Groqの存在理由は、”持つ者と持たざる者”をなくし、AIコミュニティの全員が繁栄できるように支援することです。推論はその目標を達成するために重要であり、速度は開発者のアイデアをビジネスソリューションや人生を変えるアプリケーションに変えるものです。第三者によってLPU推論エンジンが大規模言語モデルを実行するための最速のオプションであると認められたことは、非常に報われるものであり、AIアクセラレーターの中でGroqが真の競争者であると認識してくれたArtificialAnalysis.aiの皆さんに感謝しています」と、述べている。
HyperWriteのCEOであるMatt Shumer氏もこのGroq LPUの印象的なデモをX上で共有している。
Groqのシステムは一般的な機械学習フレームワークをサポートしているため、既存のAIプロジェクトへの統合が容易になるはずだ。GroqのLPU推論エンジンは、GroqChatインターフェースを通じて自分で試すことができるが、このチャットボットはインターネットにアクセスできない。Groq APIへの早期アクセスも利用可能で、承認されたユーザーがLlama 2(70B)、Mistral、Falconを通じてエンジンを試用できる。
LPUは、AIアプリケーションの展開を改善し、現在広く使用され供給が不足しているNVIDIAのA100およびH100チップの代替となる可能性があるが、今のところ、LPUは推論にしか使えない。モデルを訓練するために、企業は依然としてNVIDIA GPUや同様のチップを必要としている。
Sources







コメント