

中国テクノロジー大手のAlibabaが、過去最大規模となる20兆トークンのデータで学習した大規模言語モデル「Qwen2.5-Max」を発表した。Mixture-of-Experts(MoE)アーキテクチャを採用した同モデルは、最新のベンチマークテストにおいてDeepSeek-V3やGPT-4o、Claude 3.5 Sonnetといった強力な競合モデルを上回る性能を示したとのことだ。
効率性と性能の両立を実現した新アーキテクチャ
Qwen2.5-Maxの最大の特徴は、従来型の大規模言語モデルが全ての計算リソースを常時活用する設計であったのに対し、Mixture-of-Experts(MoE)アーキテクチャでは与えられたタスクに応じて必要な神経網のコンポーネントのみを選択的に活性化する。この設計思想により、必要な計算資源を40-60%削減しながら高い性能を実現することに成功している。
ベンチマークテストの結果は、この効率的なアプローチの有効性を如実に示している。コード生成能力を評価するLiveCodeBenchでは38.7%のスコアを記録し、DeepSeek-V3を上回る結果となった。さらに、高度な推論能力を要するArena-Hardでは89.4%という卓越したスコアを達成。これらの結果は、計算効率と処理性能のトレードオフという従来の常識を覆すものとなっている。
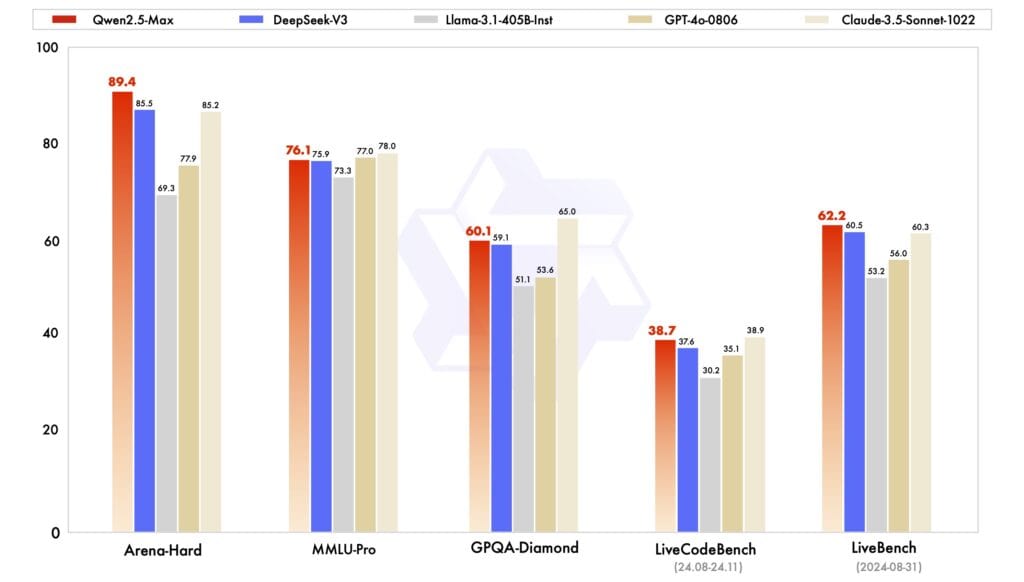
この高い性能を支えているのが、20兆トークンという過去最大規模の学習データである。しかし、単に学習データを増やすだけでなく、Alibabaは教師付き微調整(Supervised Fine-Tuning:SFT)と人間のフィードバックに基づく強化学習(Reinforcement Learning from Human Feedback:RLHF)という二段階の後処理を実施している。この綿密な後処理により、モデルの出力の質と一貫性が大幅に向上している。
特筆すべきは、このモデルがタスクに応じて動的にリソースを最適化する能力である。例えば、基本的な文章生成タスクでは必要最小限のリソースのみを使用し、複雑な推論や専門的な分析が必要な場合には、より多くの専門家ネットワークを動員する。この柔軟な資源配分により、一般的なクラウドインフラ上でも効率的な運用が可能となっている。
実装面では、OpenAIが推定32,000基以上の高性能GPUを必要とする従来型アプローチを採用しているのに対し、Qwen2.5-Maxのアーキテクチャは大幅に少ない計算資源で競争力のある性能を実現している。これは単なるコスト削減以上の意味を持つ。より少ない計算リソースで効率的な処理を実現することで、環境負荷の低減にも貢献するとともに、より広範な企業がAI技術を活用できる可能性を開いている。
「データとモデルサイズのスケーリングは、モデルインテリジェンスの進歩を示すだけでなく、先駆的な研究への揺るぎないコミットメントを反映しています。我々は、スケーリングされた強化学習の革新的なアプリケーションを通じて、大規模な言語モデルの思考と推論の能力を強化することに専念しています」と、Alibabaはブログで述べている。
Qwen2.5-Maxの利用方法
Qwen2.5-Maxの利用に際してはAlibaba Cloudを通じてAPI経由での利用、もしくはQwen Chatでの利用が提供されている。API利用にあたっては、まずAlibaba Cloudのアカウントを作成し、Model Studioサービスを有効化する必要がある。その後、コンソールでAPIキーを生成することで利用が可能となる。
技術的な実装においては、OpenAI互換のAPIインターフェースを採用しており、既存のOpenAI APIを使用しているアプリケーションからの移行が容易になるよう配慮されている。実際のコードでは、base_URLを「dashscope-intl.aliyuncs.com/compatible-mode/v1」に設定し、モデル名として「qwen-max-2025-01-25」を指定するだけで、OpenAIのライブラリをそのまま使用することができる。
一方、開発者以外のユーザーに向けては、Qwen Chatというインターフェースを通じた利用が可能となっている。このプラットフォームでは、Web検索機能やコンテンツ生成機能など、より一般的なユースケースに特化した機能が提供されている。
Qwen2.5-Maxは、同じQwen2.5ファミリーに属するQwen2.5-VLやQwen2.5-1Mとは異なり、オープンソースでの公開は行われない方針だ。これは、モデルの規模と複雑性が極めて高いことに加え、商用クラウドサービスとしての価値を維持する戦略的判断と考えられる。
しかし、注目すべき制約も存在する。他の中国発のAIモデルと同様に、Qwen2.5-Maxも中国政府のコンテンツ規制の対象となっている。この規制は、モデルの出力内容に一定の制限を課すものであり、特に政治的・社会的に機微なトピックに関する応答において影響が生じる可能性がある。
米中AIの覇権争いに新たな展開
Qwen2.5-Maxの発表は、DeepSeekによる画期的なモデル発表から1週間も経たないタイミングで行われた。この立て続けの技術革新は、米国の技術的優位性に対する懸念を深める結果となっている。
特筆すべきは、両社とも米国による半導体輸出規制下でこれらの成果を上げている点だ。従来のような潤沢な計算資源に頼るアプローチではなく、アーキテクチャの革新によって効率性を追求する中国企業の戦略が、新たな成功モデルを示している。
実際に、OpenAIが最新モデルの学習に推定32,000基以上の高性能GPUを使用したとされる一方、Qwen2.5-Maxは効率的なMoEアーキテクチャによって、より少ない計算資源で競争力のある性能を実現している。
Source








コメント