

科学研究の効率を革新的に向上させる新たなオープンソースAIフレームワーク「Agent Laboratory」をAMDとジョンズホプキンズ大学の共同研究チームが開発した。このシステムは、研究者の創造的な発想を維持しながら、時間のかかる実験やドキュメント作成作業を効率化することを目指したものだ。
研究プロセスを自動化する3段階アプローチ
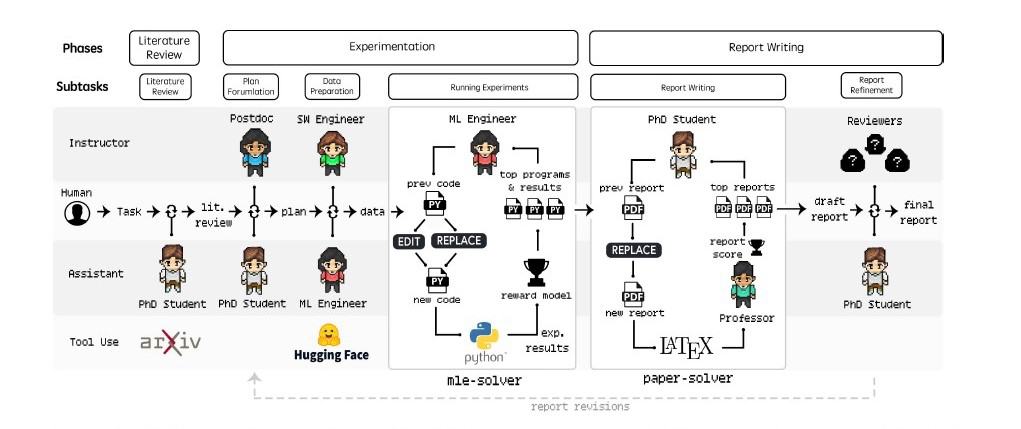
Agent Laboratoryは、アカデミックな研究プロセス全体を効率化するため、文献レビュー、実験、レポート作成という3つの主要フェーズで構成される体系的なアプローチを採用している。
Johns Hopkins University)
第一段階となる文献レビューでは、PhDエージェントが中心的な役割を担う。このエージェントはarXiv APIを活用して、研究テーマに関連する学術論文を広範に収集する。単なる論文の収集にとどまらず、各論文の重要なポイントを抽出し、研究コンテキストにおける位置づけを整理。これにより、人間の研究者が膨大な文献を読み込む時間を大幅に削減しながら、必要な知見を効率的に得ることが可能となる。
第二段階では、PhDエージェントとポスドクエージェントによる協調的な実験計画の立案が行われる。両エージェントは文献レビューから得られた知見を基に、具体的な実験手法や必要なデータセット、評価指標などを詳細に検討する。この過程では、実験の再現性や統計的な妥当性も考慮され、科学的に信頼性の高い研究計画が策定される。特筆すべきは、これらのエージェントが継続的な対話を通じて計画を練り上げていく点である。この対話的なアプローチにより、単一のエージェントでは気づかない実験上の課題や改善点を早期に発見することが可能となっている。
第三段階では、ML-Engineerエージェントが専用ツール「mle-solver」を駆使して、実際の実験を実行する。このエージェントは機械学習コードの作成、テスト、最適化を一貫して担当する。mle-solverは特に注目すべきツールで、研究の方向性をテキストとして受け取り、それを実行可能なコードへと変換する能力を持つ。このツールは実験結果に基づいて反復的にコードを改善し、最適な実験条件を追求する。コードの更新は「REPLACE」(全体の書き換え)と「EDIT」(特定行の修正)という2つのコマンドを通じて行われ、コンパイルエラーが発生した場合は最大3回の修復を試みる仕組みが実装されている。
実験完了後、システムは「paper-solver」と呼ばれる特殊なツールを用いて研究結果を学術論文形式にまとめ上げる。この過程では、PhDエージェントと教授エージェントが協力して作業を進める。paper-solverは実験計画、実験結果、得られた洞察、文献レビューの内容を統合し、学会提出に適した形式の論文を生成する。注目すべきは、このツールが単なる結果の羅列ではなく、研究の文脈における発見の意義や、既存研究との関連性も含めて論理的に記述する点である。生成された論文は複数回の改訂を経て、人間が理解しやすい形式に洗練される。
この3段階アプローチの特筆すべき点は、各フェーズが独立しながらも密接に連携している点だ。前段階の出力が次段階の入力として効果的に活用され、研究プロセス全体としての一貫性が保たれている。また、各段階で人間の研究者が介入できる設計となっており、完全な自動化ではなく、人間の創造性や判断を補完する形で研究を支援する仕組みが実現されている。
AIモデル性能評価と研究者協調による品質向上の実際
Agent Laboratoryの性能評価は、複数のAIモデルを用いた自動実行モードと、研究者との協調モードの両面から実施された。この包括的な評価により、各モデルの特性や人間との協調がもたらす効果について、興味深い知見が得られている。
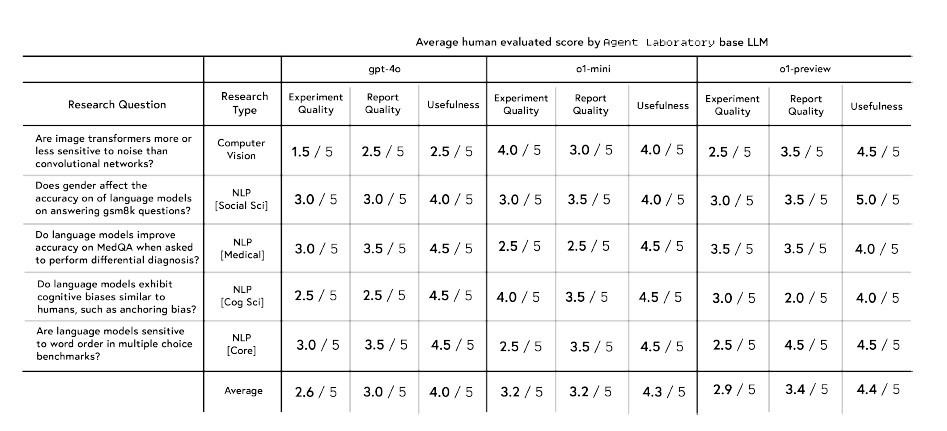
自動実行モードにおける評価では、OpenAIのo1-previewモデルが最も高いパフォーマンスを示した。特に有用性では5点満点中4.4点、レポート品質では3.4点を獲得し、他のモデルを上回る結果となった。ただし、実験の品質面では2.9点とやや低い評価となり、この領域では逆にo1-miniモデルが3.2点と最高スコアを記録した。注目すべきは、これらのスコアが10名のPh.D.学生によるピアレビュー形式で評価された点で、実際の研究現場の視点が反映された結果といえる。
モデル間の性能差は研究トピックによっても顕著な違いが見られた。例えば、画像ノイズに関する研究では、GPT-4oモデルが実験品質で1.5点、有用性で2.5点と苦戦する中、o1-miniモデルは同じ課題で実験品質4.0点、有用性4.0点と際立った成果を示した。ただし、単語の順序に関する研究ではGPT-4oモデルが実験品質で3.0点、有用性で4.5点を示す中、o1-miniが実験品質で2.5点、有用性で4.5点だった。o1-previewはレポート品質においてこれら2つの3.5点を上回る4.5点をマークしたが、実験品質は逆に2.5と最も低かった。これは、研究分野によって最適なモデルが異なる可能性を示唆している。
Johns Hopkins University)
人間の査読者がAgent Laboratoryによって作成された論文を見たところ、AIモデルによって結果が異なることも分かった。 OpenAIのo1-previewモデルは、特に明瞭さと妥当性において全体的にトップとなり、o1-miniは実験の質において最も高い評価を得ている。

Johns Hopkins University)
AIの査読者と人間の査読者の見方はまったく異なっていた。 特に、論文がいかに明確でよく表現されているかという点に関しては、AIは人間よりも常に2.3点ほど高い点数をつけた。
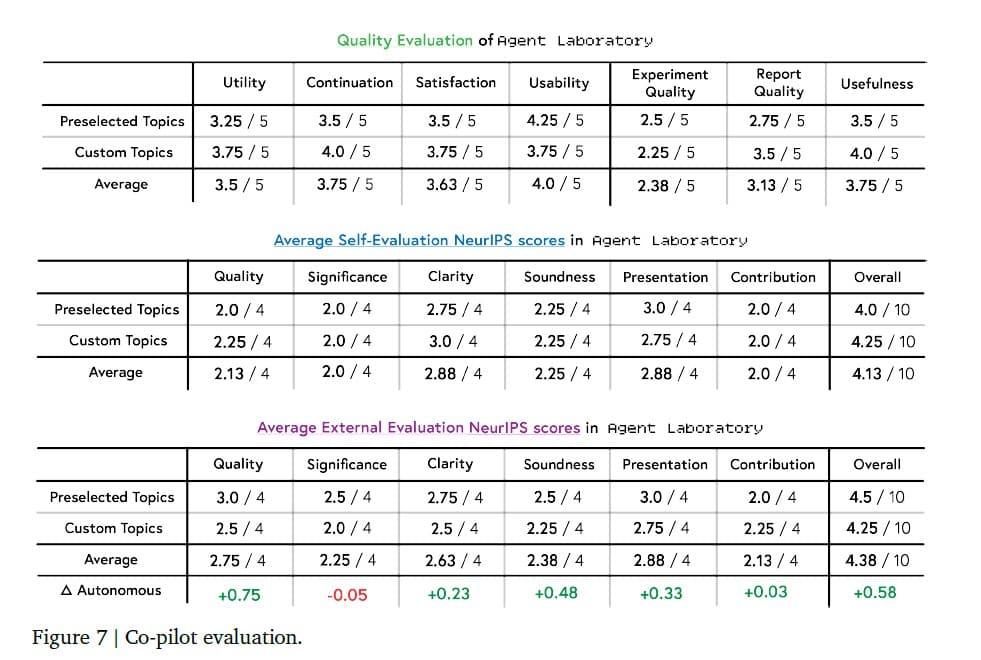
一方、研究者との協調モード(コパイロットモード)の導入は、システム全体の性能を大きく向上させる結果となった。このモードでは、ユーティリティ(3.5/5点)、継続利用の可能性(3.75/5点)、満足度(3.63/5点)、使いやすさ(4.0/5点)と、全般的に高い評価を獲得した。特筆すべきは、研究者が独自に設定したカスタムトピックでの性能向上で、ユーティリティでは0.5点、継続利用可能性では0.5点、満足度では0.25点の改善が確認された。
Johns Hopkins University)
さらに、NeurIPS形式の評価基準に基づく論文品質の評価では、協調モードの効果が顕著に表れた。自動モードと比較して、論文の総合評価は3.8点から4.38点へと0.58ポイントの向上を示した。特に顕著な改善が見られたのは品質面(0.75ポイント増)、明確性(0.23ポイント増)、論理的健全性(0.48ポイント増)、プレゼンテーション(0.33ポイント増)の各項目だった。一方で、研究の重要性(-0.05ポイント)や貢献度(0.03ポイント増)については、大きな変化は見られなかった。
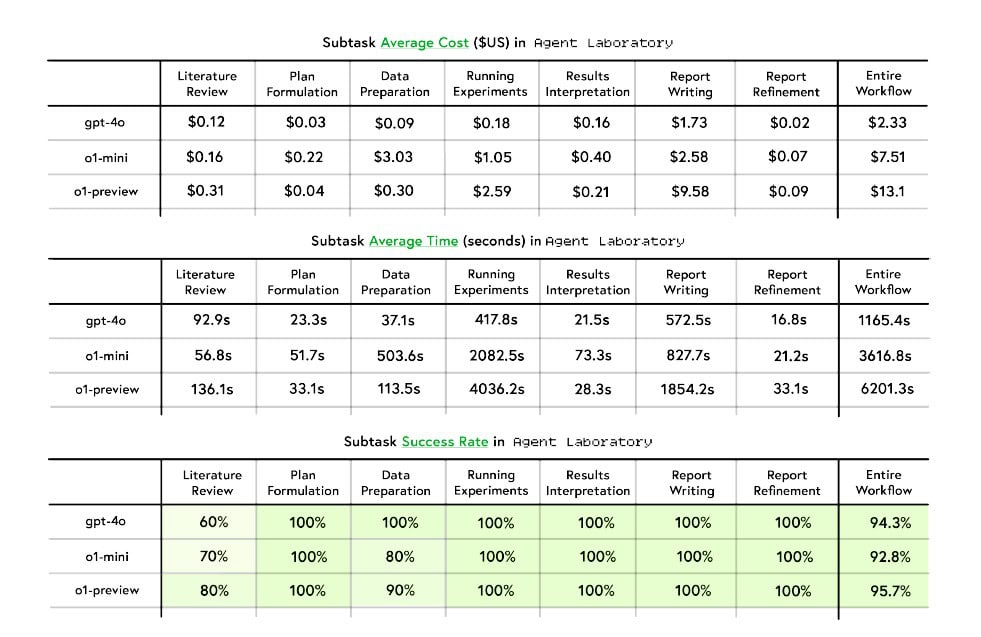
実行効率については、GPT-4oモデルが最も優れたパフォーマンスを示した。完全な研究ワークフローの実行に要する時間はわずか1165.4秒で、コストも2.33ドルと経済的だった。対照的に、o1-miniモデルは3616.8秒で7.51ドル、o1-previewモデルは6201.3秒で13.10ドルを要した。特に報告書作成フェーズでは、o1-previewモデルが単独で9.58ドルのコストを必要とし、効率面での課題が浮き彫りとなった。ただし、信頼性の面では各モデルとも高い水準を維持し、GPT-4oが98.5%、o1-miniとo1-previewが95.7%の成功率を達成している。
これらの評価結果は、Agent Laboratoryが単なる自動化ツールではなく、人間の研究者との相互作用を通じて真価を発揮するシステムであることを示している。特に、研究者の創造的な介入が、論文の質的向上に大きく寄与することが明らかとなった。ただし、依然としてNeurIPSで採択される論文の平均スコア(5.9点)には届かない点も明らかとなり、今後の改善の余地も示唆された。
今後の展望と課題
Agent Laboratoryの開発チームは「研究者がより創造的な発想に時間を割り当てられるようになり、最終的に科学的発見が加速することを期待している」と述べている。一方で、AIによる自己評価の過大性や、自動化された研究の制約、不正確な情報生成のリスクなど、いくつかの課題も認識されている。
これらの課題に対して、システムは人間の研究者との協調を重視する設計を採用。独自の研究アイデアの創出ではなく、研究者の創造性を補完し、効率的な研究遂行をサポートすることに焦点を当てている。
論文
参考文献







コメント