

人類は自分たちが作り上げた物の仕組みを完全には理解せず、今日大々的に使い、その用途を広げている。それが“人工ニューラル・ネットワーク”であり、それに基づき構築されたChatGPTなどのAIモデルだ。仕組みが理解出来ないからこそ、なぜ幻覚を見るのか、情報を捏造するのかを正確に理解する事が出来ずにいる。
だが、OpenAIのライバルの一つであるAIスタートアップAnthropicの研究者らは、同社の提供する大規模言語モデル(LLM)「Claude 3」のブラックボックスを開け、その中身を少し垣間見ることに成功したようだ。
大規模言語モデルの内部では何が起こっているのか
Anthropicの共同設立者でGoogle Brain、OpenAIと渡り歩いてきたAI研究の第一人者Chris Olah氏はWired誌に「その内部で何が起こっているのか?私たちはこれらのシステムを持っていますが、何が起こっているのかわかりません。これはクレイジーだと思います」と、現在の状況を端的に語っている。
大規模言語モデル(LLM)の普及は今後拡大する一方だろう。これがより一般的な物として人々の間に浸透していく中で、LLMが偏見や誤情報、人々を危険にさらすような情報を出力しないためには安全対策が必要だ。だが、LLMの内部で何が起こっているのか理解出来なければ、これを完全に制御することは叶わない。だからこそ研究者らはそれを解明しようと研究を進めている。
Olah氏のチームらが発表した今回の成果はそうした努力が実を結びつつある事を示唆する物だ。彼らは、Claude 3 Sonnetモデルの何百万もの人工ニューロンがどのように活性化し、一般的なクエリに対して驚くほど現実的な応答を生成するのかを少なくとも部分的に正確に説明する事が出来たことを報告している。
この手法は、人工ニューラルネットワークが概念を内部層の活性化パターンとして表現するという考えに基づいている。これらのパターンを分析することで、学習された概念を可視化することができるというのだ。
LLMを分析する際、特定のクエリに応じてどの人工ニューロンが活性化されるかを見るのは簡単だ。しかし、LLMは単一のニューロンに異なる単語や概念を単純に保存しているわけではない。Anthropicの研究者が説明するように、「各概念は多くのニューロンにわたって表現され、各ニューロンは多くの概念の表現に関与している」からだ。
この一対多、多対一の混乱を整理するために、Anthropicは、今回の研究に先立ち、特徴量と呼ばれるニューロン活性のパターンを、人間が解釈可能な概念にマッチングさせる事に成功している。そして古典的な機械学習から借用した「辞書学習」と呼ばれる技法を使い、多くの異なる文脈で繰り返されるニューロンの活性化パターンを分離することを行った。これにより、モデルのどのような内部状態も、多数のアクティブなニューロンではなく、少数のアクティブな特徴で表現することができるようになったとのことだ。
このニューロンの組み合わせによって作られた「特徴」は、それ自体が組み合わさり、全ての内部状態を構築する。
研究者らは、Claude 3.0 Sonnetモデルでアクティブな数千万の特徴を特定している特徴マップを作成した。表面的なレベルでも、この特徴マップを閲覧することで、Claudeが特定のキーワード、フレーズ、概念を知識に近いものとしてどのようにリンクしているかを示すことができる。
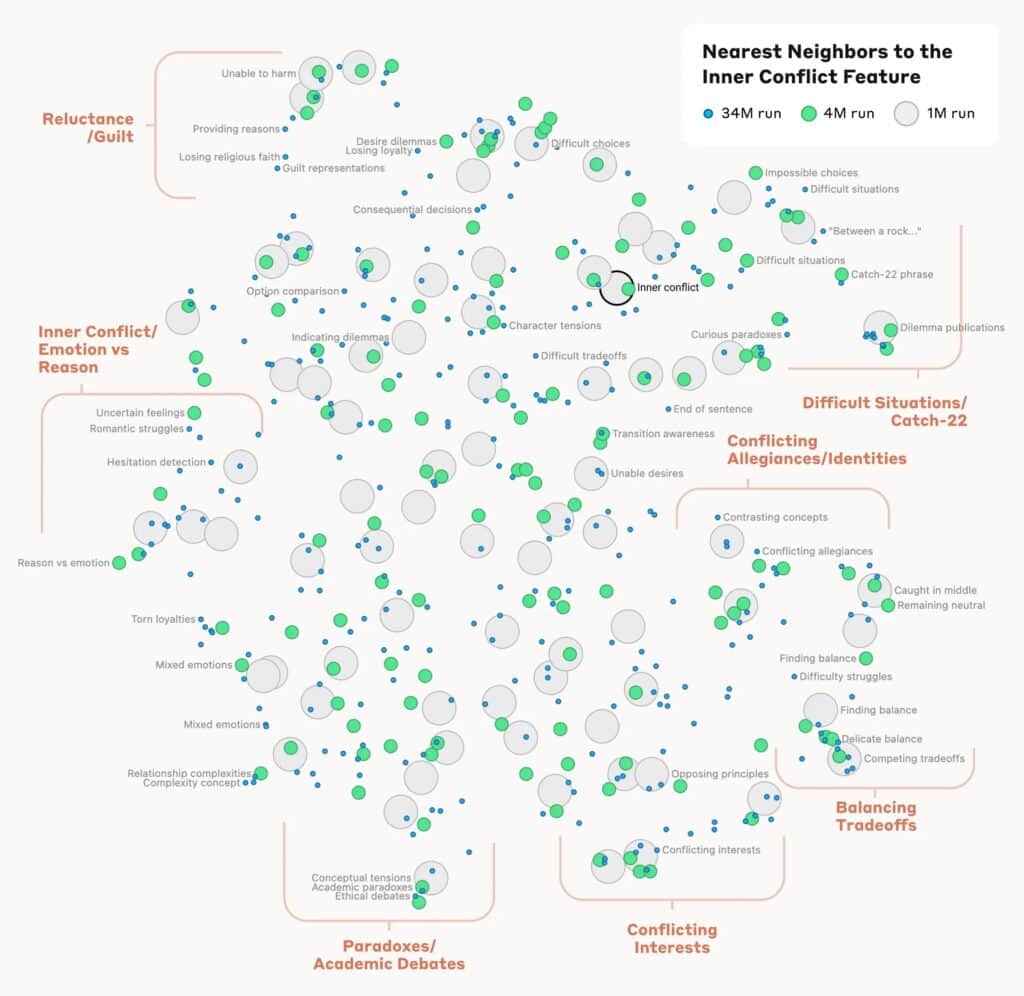
例えば、「内なる葛藤」という概念に関連する特徴の近くを見ると、人間関係の破綻、対立する忠誠心、論理的矛盾、そして「catch-22」というフレーズに関連する特徴が見つかる。これは、AIモデルにおける概念の内部構成が、少なくともいくらかは人間の類似性の概念に対応していることを示している。「これが、Claudeの優れた類推や比喩の能力の起源なのかもしれない」と、研究者らは述べている。
他の例としては、免疫不全、特定の疾患、免疫反応に関する議論に反応する「免疫学」の特徴がある。この特徴の近くには、ワクチンや免疫機能を持つ臓器システムといった関連概念がある。また、「首都」というラベルの特徴は、「首都」という言葉や、リガ、ベルリン、アゼルバイジャン、イスラマバード、バーモント州モンペリエなどの特定の都市名に強く反応する傾向がある。
研究者たちはまた、特徴の階層的な組織化の証拠も発見した。例えば、「サンフランシスコ」という一般的な特徴は、さらに詳細に分析すると個々のランドマークや地区に関するより具体的な特徴に分かれる。同様に、「カナダ」や「アイスランド」といった国の特徴は、「地理」、「文化」、「政治」といったサブ特徴に分かれる。

抽出された特徴は、著名な人物や場所から、プログラムコード内の構文要素、共感や皮肉といった抽象的な概念に至るまで広範囲にわたる。多くの特徴は、対応する概念のテキストの言及や画像の両方に敏感であるが、分析手法はテキストデータのみに適用された。
この研究はまた、ニューロンの類似性に基づいて異なる特徴間の「距離」を計算している。このプロセスによって見つかった「特徴の近隣」は、「意味的な関係を共有する幾何学的に関連するクラスターにしばしば組織されている」と研究者たちは書いており、「AIモデルの概念の内部組織が、少なくともある程度は、私たち人間の類似性の概念に対応している」ことを示している。例えば、ゴールデンゲートブリッジの特徴は、「アルカトラズ島、ギラデリスクエア、ゴールデンステートウォリアーズ、カリフォルニア州知事Gavin Newsom、1906年の地震、サンフランシスコを舞台にしたAlfred Hitchcockの映画『めまい』」を表す特徴に比較的「近い」。
ブラックボックスに光が差し込む
LLMが情報をどのように保存するかをマッピングするだけでなく、重要なのは、このようなClaudeの内部構造の知識は、Claudeの反応がどのように変わるのかを見る為に、非常に具体的な方法でモデルの行動を調整するためにも使用できるということだ。実際にClaudeモデルは特定の特徴の値を人工的に高くまたは低く設定した後、非常に奇妙な行動を示し始めることがある。例えば、ゴールデンゲートブリッジの特徴を増幅すると、モデルは「私はゴールデンゲートブリッジです…私の物理的な形は象徴的な橋そのものです…」と言い始める。
これらの行動関連の結果は、「特徴がモデルが世界を内部的に表現する方法、およびその行動にこれらの表現を使用する方法の忠実な部分である可能性が高い」ことを示唆している。
時には、特徴と行動の間のリンクが比較的直接的であることもある。研究者たちは、「より憎悪的な、偏見関連の特徴」を高レベルに設定すると「モデルが憎悪的な攻撃を行う」ことが分かったと書いている。ただし、それは必ずしも当てはまるわけではなく、一部の微妙な場合もあったという。

過去には、特定のモデルのプリセットの保護対策や行動モードを無視するように「脱獄」させる攻撃的なユーザーがプロンプトを操作した際に、LLMから同様の驚くべき行動が見られた。特定のモデルの内部特徴マップの特定の部分の相対値を調整することで、LLMのメーカーは「特定の危険な行動を監視する」「望ましい結果に向けてモデルを導く」「特定の危険な主題を完全に排除する」などの方法で、より積極的に行動を制御できる可能性があると研究者たちは書いている。
「興味深いのは、これらの特徴が存在することではなく、スケールで発見され、介入されることができるということです。例えば、モデルが私たちに対して欺瞞的であるか嘘をついているかを確実に知ることを望むかもしれません。あるいは、非常に有害な行動のカテゴリー(例:生物兵器の作成を助ける)を確実に検出して止めることができることを望むかもしれません」と、研究者らは述べている。
Anthropicのチームは、この結果を有能なAIシステムの透明性と制御に向けた重要な一歩と見なしている。しかし、ますます大規模化するモデルに解釈可能性を適用することの巨大な課題も指摘している。
研究者らは、Wiredにブラックボックス問題を解決したのかと質問された際に、即座に「ノー」と答えている。ただし、今回のAnthropicチームの仕事を評価する声も大きい。実際にモデルの操作に成功したことが「意味のある特徴を見つけていることを示す優れた兆候である」と、ノースウェスタン大学のDavid Bau氏は述べている。
しかし、Bau氏は、このアプローチの限界に対して慎重な姿勢も示している。辞書学習ではLLMが考慮しているすべての概念を特定することはできない。なぜなら、特徴を特定するためにはそれを探している必要があるからだ。「発見された特徴は、モデルがトレーニング中に学習したすべての概念のごく一部を表しており、現在の技術を使用して完全な特徴セットを見つけることは、コストがかかりすぎる(現在のアプローチに必要な計算量は、モデルをトレーニングするために使用された計算量をはるかに超える)」と研究者たちも指摘している。
だが、この成果は初期段階の物ではあるがエキサイティングな物であることは確かだ。
“得られた洞察は、将来の言語モデルをより理解しやすくし、より堅牢で安全に使用できるようにするのに役立つ可能性がある”とAnthropicは述べている。
論文
参考文献









コメント