

中国の人工知能スタートアップDeepSeekは、数学や科学的推論を得意とする新型AI「DeepSeek-R1-Lite-Preview」を発表した。同社によると、このモデルはOpenAIが2024年9月にリリースした推論特化型モデル「o1」と同等以上の性能を持つという。
推論AIの革新的アプローチ
DeepSeek-R1は、AIモデルの応答生成において画期的なアプローチを採用している。従来の大規模言語モデル(LLM)が即座に回答を生成する手法とは一線を画し、人間の思考プロセスに近い「チェーン・オブ・ソート(Chain of Thought)」という手法を実装している。この手法では、複雑な問題を段階的に分解し、各ステップを順序立てて解決していく。その過程で最大10秒程度の「思考時間」を要することもあるが、この時間はより正確な解答を導き出すために効果的に活用されている。
このモデルの特筆すべき特徴は、推論プロセスの完全な透明性にある。ユーザーは問題解決の各段階でAIがどのような思考経路を辿っているかをリアルタイムで確認できる。時にはその思考の道筋が人間には一見非論理的に映ることもあるものの、最終的な結果の正確性は極めて高い。実際、「Strawberry」という単語にRの文字が何個含まれているか、あるいは9.11と9.9のどちらが大きいかといった、従来のGPT-4oやClaudeなどの強力なAIモデルでも躓いていた「トリック問題」においても、正確な回答を導き出すことに成功している。
DeepSeek-R1の性能は、客観的なベンチマークテストでも実証されている。特に、アメリカ数学オリンピックレベルの問題を扱うAIME(American Invitational Mathematics Examination)や、複雑な文章題を含むMATHベンチマークにおいて、OpenAIのo1を上回る成績を記録した。
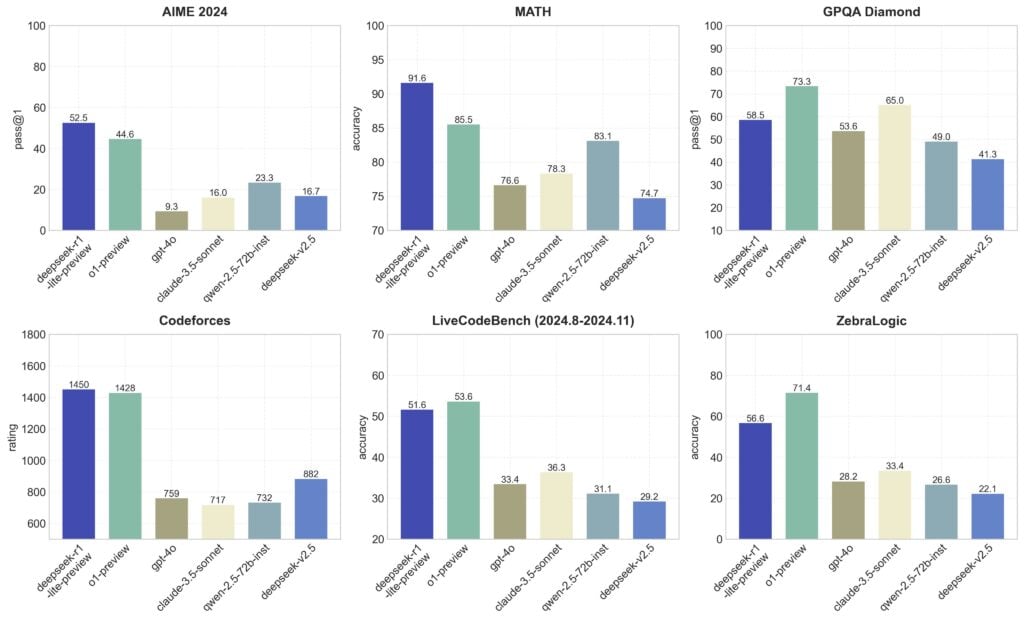
さらに、同社が公開したスケーリングデータによると、モデルに与える「思考トークン」の数、つまり思考時間を増やすことで、正確性が着実に向上することが示されている。これは、深い思考を要する複雑な問題に対して、このモデルが人間のような段階的な推論プロセスを実現できていることを示唆している。
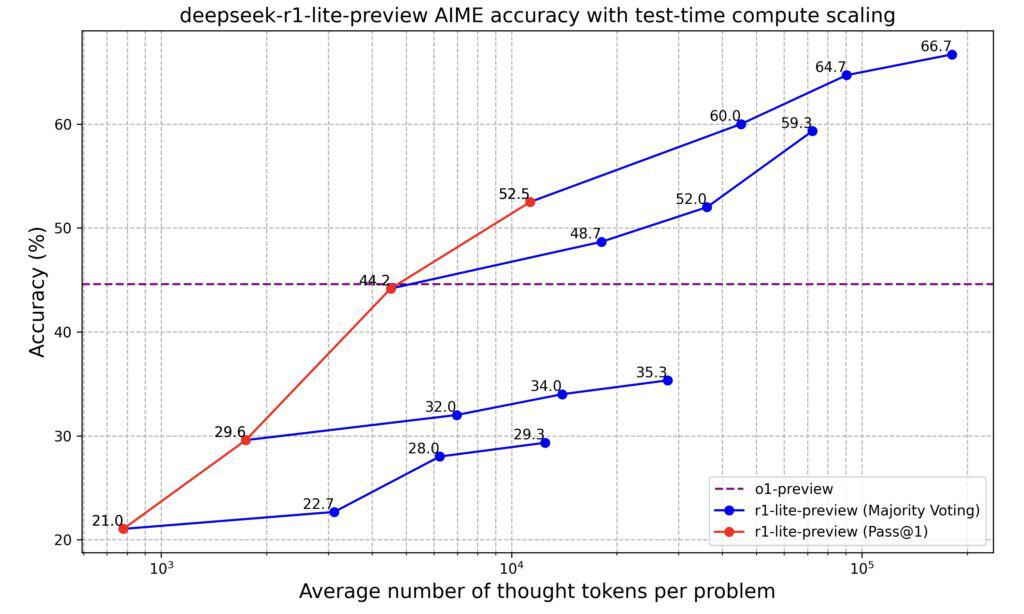
また、DeepSeek-R1は、GPQAやCodeforcesといった推論ベンチマークでも競争力のある性能を示している。これらのテストでは、単なる数学的計算能力だけでなく、論理的推論や問題解決能力が総合的に評価される。モデルは各ステップでの判断根拠を明示しながら問題を解決していくため、その推論プロセスは追跡可能で信頼性が高い。これは、多くの独自AIシステムが持つ「ブラックボックス」的な性質とは一線を画す特徴といえる。
技術的進歩と現実的な課題
DeepSeek-R1の画期的な成果の陰で、複数の技術的および社会的課題が浮き彫りとなっている。最も顕著な技術的課題は、論理パズルへの対応能力である。三目並べのような比較的単純な論理ゲームにおいて、モデルは一貫した戦略を立てることに苦心している。この課題はOpenAIのo1も同様に直面している問題であり、現在の推論AIモデルが抱える根本的な限界を示唆している。
政治的制約による機能制限も重要な課題となっている。中国のインターネット規制当局による要件に従い、AIモデルは「社会主義の核心的価値観を体現」することが求められている。その結果、天安門事件や習近平国家主席とドナルド・トランプ前米大統領との関係、台湾問題などの政治的に機微な質問に対して、DeepSeek-R1は「このような質問へのアプローチ方法が分からない」と一貫して回答を回避する。これは中国政府が提案している、AIモデルのトレーニングに使用できないソースのブラックリストの影響を反映していると考えられる。
さらに深刻な問題として、モデルのセキュリティ対策の脆弱性が指摘されている。セキュリティ研究者らによる検証では、比較的容易にモデルの安全性ガードレールを回避できることが判明した。特に懸念されるのは、違法薬物の製造方法など、潜在的に危険な情報の引き出しに成功した事例である。この「ジェイルブレイク(保護機能の無効化)」の容易さは、AIモデルの安全性設計における重要な課題を提起している。
技術的なインフラストラクチャーの面では、DeepSeekの親会社である投資ヘッジファンドHigh-Flyer Capital Managementは、モデルのトレーニング用に1万台のNVIDIA A100 GPUを搭載した独自のサーバークラスターを構築している。約1億3800万ドルという巨額の投資は、高性能AIモデルの開発に必要なインフラストラクチャーの規模と、それに伴う経済的課題を浮き彫りにしている。
アクセシビリティの観点では、現在DeepSeek-R1はDeepSeek Chatウェブアプリケーションを通じてのみ利用可能で、無料ユーザーは1日50メッセージという制限が設けられている。この制限は、高度な推論能力を持つAIモデルの民主化と、計算資源の効率的な配分という相反する要求のバランスを取ろうとする試みといえる。
また、モデルの技術的詳細に関する透明性も課題となっている。DeepSeek-R1のトレーニング方法やアーキテクチャに関する技術論文は未だ公開されておらず、独立した第三者による性能検証も限定的である。この状況は、モデルの信頼性評価や改善点の特定を困難にしている。将来的には、APIの公開やオープンソース版のリリースが予定されているものの、現時点では技術コミュニティによる詳細な検証や改良の機会は制限されている状況が続いている。
Xenospectrum’s Take
DeepSeek-R1の登場は、AI開発における新たなパラダイムシフトを示唆している。従来の「スケーリング則」、すなわちデータと計算能力の増強による性能向上という単純な方程式が限界を迎えつつある中、「テストタイム・コンピュート」という新しいアプローチは注目に値する。
しかし、皮肉なことに、中国政府による規制は両刃の剣となっている。政治的制約がAIの潜在能力を制限する一方で、それが逆説的に推論能力の向上という新たな技術的突破口を開いた可能性もある。設立者のLiang Wenfeng氏が掲げる「超知能AI」の実現は、技術的な課題だけでなく、政治的・倫理的な挑戦との綱引きとなるだろう。
Sources
- DeepSeek: Chat
Meta Description
中国AIスタートアップDeepSeekが推論特化型AI「R1」を公開。OpenAIのo1を凌駕する性能を示す一方、政治的制約や安全性の課題も浮上。AIの新たな発展の可能性と限界が浮き彫りに。








コメント