

サンフランシスコの新興企業Deep Cogitoが、ステルスモードを解除し、高性能なオープンソースAIモデル群「Cogito v1」を発表した。独自のIDA訓練手法とハイブリッド推論機能を備え、既存のLlamaやDeepSeekモデルと言ったトップクラスのオープンソースモデルを凌駕する性能を示すと主張している。
Deep Cogitoとは? – ステルスから登場した新星AI企業
Deep Cogitoは、2024年6月に設立されたサンフランシスコ拠点のAI研究スタートアップだ。共同創業者は、Googleで生成検索プロダクトのLLM(大規模言語モデル)モデリングを主導したとされるDrishan Arora氏(CEO)と、Google DeepMindでプロダクトマネージャーを務めたDhruv Malhotra氏である。PitchBookによると、同社はSouth Park Commonsなどから資金調達を受けている。
Deep Cogitoは、「汎用超知能(General Superintelligence)」、すなわち「ほとんどの人間よりも優れたタスクを実行でき、私たちがまだ想像もしていないまったく新しい能力を発見できるAI」の開発を究極的な目標に掲げている。この野心的な目標にもかかわらず、同社は「私たちが作成するすべてのモデルはオープンソース化される」と明言しており、AIコミュニティへの貢献姿勢を示している。
新オープンソースモデル「Cogito v1」の概要
今回発表された「Cogito v1」は、MetaのLlama 3.2やAlibabaのQwenといった既存の強力なオープンソースモデルをベースに、Deep Cogito独自の改良を加えたLLMファミリーである。
- モデルラインナップ: 現在、パラメータ数が30億(3B)、80億(8B)、140億(14B)、320億(32B)、700億(70B)の5つのサイズのモデルが公開されている。今後数週間から数ヶ月以内に、1090億(109B)、4000億(400B)、6710億(671B)パラメータを持つ、さらに大規模なモデル(MoE: Mixture-of-Expertsモデルを含む)のリリースも計画されている。
- ライセンス: モデルはMetaのLlamaライセンス条件の下で提供される。これにより、月間アクティブユーザー数(MAU)が7億人に達するまでは商用利用が可能だ(7億人を超えた場合はMetaから別途ライセンスを取得する必要がある)。
- 利用方法: Cogito v1モデルは、AIコミュニティプラットフォームのHugging Faceやローカル実行環境のOllamaからダウンロードできるほか、クラウドAIプラットフォームのFireworks AIやTogether AIを通じてAPI経由でも利用可能である。
- 最適化: これらのモデルは特に、コーディング、関数呼び出し(Function Calling)、およびAIエージェントとしての利用に適するように最適化されている。
最大の特徴:ハイブリッド推論と独自手法「IDA」
Cogito v1の最大の特徴は、「ハイブリッド推論」アーキテクチャと、それを実現するための独自トレーニング手法「Iterated Distillation and Amplification (IDA)」にある。
ハイブリッド推論:速度と精度を両立
Cogito v1の各モデルは、二つの動作モードを持つハイブリッド型である。
- 標準モード: 従来のLLMのように、迅速に直接的な回答を生成する。単純な質問に適している。
- 推論モード: OpenAIの「o」シリーズやDeepSeek R1のように、回答を生成する前により多くの計算時間を費やして「自己反省」や段階的な思考を行う。複雑な問題に対して、より高品質で信頼性の高い回答が期待できる。
このハイブリッド設計により、ユーザーはタスクの性質に応じて、応答速度を優先するか、思考の深さと精度を優先するかを選択できる。これは、計算コストと応答時間のトレードオフを柔軟に管理できるという利点をもたらす。
独自手法「IDA」:自己改善による知能増幅
Deep Cogitoは、Cogito v1の高性能化とハイブリッド推論機能の実現のために、「Iterated Distillation and Amplification (IDA)」と呼ばれる新しいトレーニング手法を採用した。これは、従来のRLHF(Reinforcement Learning from Human Feedback、人間からのフィードバックによる強化学習)や、大規模モデルから小規模モデルへ知識を移転する「蒸留」とは異なるアプローチである。
IDAのプロセスは、以下の2つのステップを繰り返すことで構成される。
- Amplification (増幅): モデルにより多くの計算リソースを割り当て、より高度な推論プロセス(例えば、段階的な思考や自己評価など)を実行させることで、より質の高い、改善されたソリューション(回答)を生成させる。
- Distillation (蒸留): 増幅ステップで得られた高品質なソリューションとその生成プロセス(つまり「賢い考え方」)を、モデル自身のパラメータに学習させ、内面化させる。
Deep Cogitoはこのプロセスを、囲碁AI「AlphaGo」が自己対戦を通じて強くなっていったプロセスに例えている。計算を使ってより良い解を見つけ、その「見つけ方」をモデル自身が学ぶことで、モデルは反復的に自己改善していく。このループにより、モデルの能力は人間の教師や固定的な大規模モデルの能力に縛られることなく、投入される計算リソースとIDAプロセスの効率性によってスケールアップしていく可能性がある。
同社によれば、IDAはRLHFや従来の蒸留よりも時間効率が高く、スケーラブルであるという。事実、Cogito v1モデル群は「約75日間で小規模なチームによって開発された」とブログで述べられている。
ただし、注意点として、現在のCogitoモデルは「非常に長い推論チェーンには最適化されていない」とのことである。
驚異的な性能:ベンチマーク結果の詳細分析
Deep Cogitoは、Cogito v1モデルが同規模の主要なオープンソースモデルを凌駕することを示す広範なベンチマーク結果を公開した。以下に主要な結果を抜粋する。
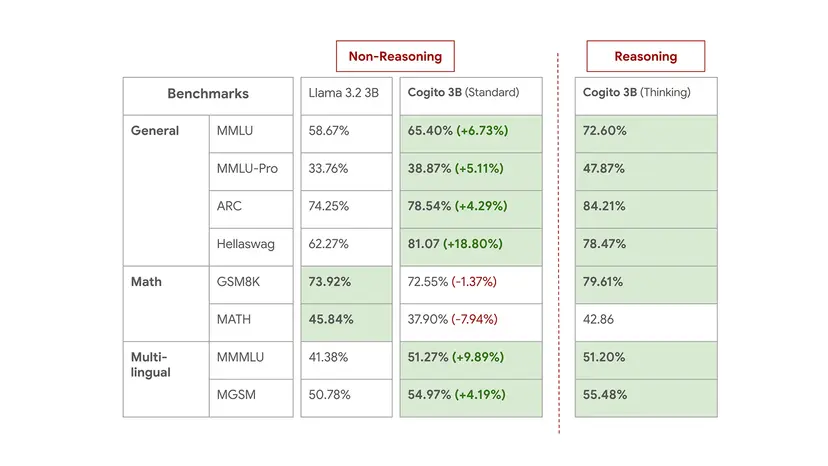
- Cogito 3B:
- 標準モードで、MMLU(一般知識)スコアが65.4%となり、Llama 3.2 3B (58.7%) を6.7ポイント上回る。Hellaswag(常識推論)では81.1%で、Llama 3.2 3B (62.3%) を18.8ポイント上回る。
- 推論モードでは、MMLUスコアが72.6%、ARC(AI2 Reasoning Challenge)スコアが84.2%に達し、標準モードの性能をさらに向上させている。
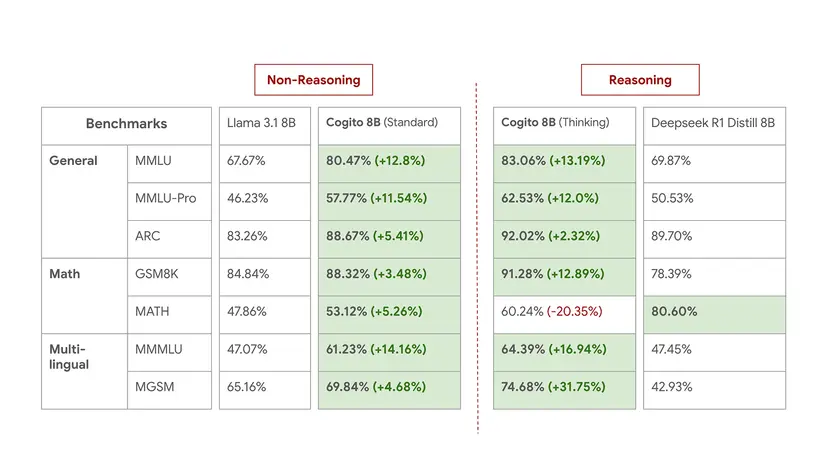
- Cogito 8B:
- 標準モードで、MMLUスコア80.5%を達成し、Llama 3.1 8Bを12.8ポイント上回る。MMLU-Proでも11ポイント以上リードし、ARCでは88.7%を記録。
- 推論モードでは、MMLUスコア83.1%、ARCスコア92.0%を達成。DeepSeek R1 Distill 8Bと比較すると、MATH(数学問題)ベンチマークを除くほぼ全てのカテゴリで上回る。ただし、MATHではCogito 8B (推論) が60.2%に対し、DeepSeek R1は80.6%と大きな差がある。
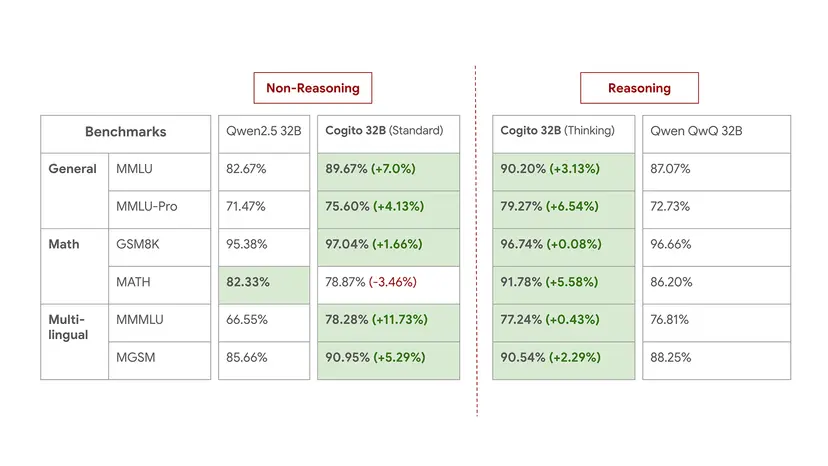
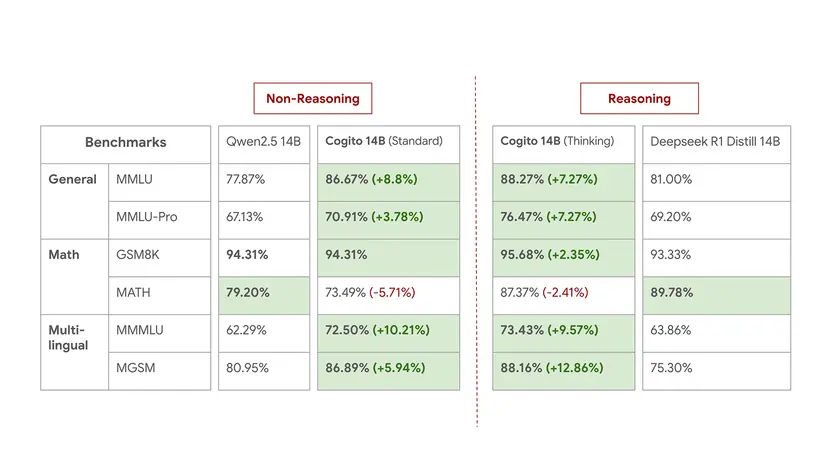
- Cogito 14B & 32B:
- 同規模のQwen2.5モデルと比較して、集計ベンチマークで約2〜3ポイント高いスコアを示す。Cogito 32B (推論) はMMLUで90.2%、MATHで91.8%に達する。
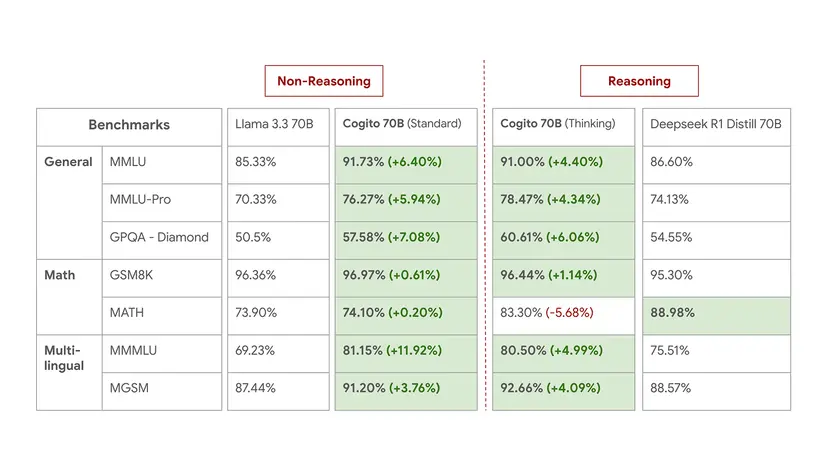
- Cogito 70B:
- 標準モードで、MMLUスコア91.7%を記録し、Llama 3.3 70B (85.3%) を6.4ポイント上回る。さらに、集計ベンチマークスコア (LiveBench) では54.5%となり、より大規模なMetaの最新モデル Llama 4 Scout 109B (53.3%) をも上回る。これは、Llama 3 405Bから蒸留されたLlama 3.3 70Bや、Llama 4 Behemoth 2Tから蒸留されたLlama 4 Scout 109BよりもIDAを用いたCogito 70Bが効率的に高性能を達成したことを示唆している。
- 推論モードでは、DeepSeek R1 Distill 70Bと比較して、一般知識および多言語ベンチマークでより強力な結果を示し、MMLUで91.0%、MGSM(多言語数学)で92.7%を記録。
- ただし、MATHベンチマークにおいては、推論モードのCogito 70B (83.3%) はDeepSeek R1 (89.0%) に比べて5ポイント以上低いスコアとなっている。
これらの結果は、Cogitoモデル、特に推論モードが高い性能を発揮することを示しているが、数学的能力など特定のタスクにおいてはトレードオフが存在することも示唆している。Deep Cogito自身も、「ベンチマークは有用なシグナルを提供するが、実世界の性能を完全には捉えきれない」としつつ、「ユーザーのニーズに近い評価において、我々のモデルは強力な結果をもたらすと確信している」と述べている。
実用性も重視:ネイティブなツール呼び出し機能
近年のAIエージェント開発やAPI連携において重要性が増している「ツール呼び出し(Function Calling)」機能についても、Cogitoモデルはネイティブで対応し、高い性能を示している。
- Cogito 3B: Llama 3.2 3Bがツール呼び出しをサポートしていないのに対し、Cogito 3Bは4種類のタスク(Simple, Parallel, Multiple, Parallel-Multiple)をネイティブでサポート。Simpleタスクで92.8%、Multipleタスクで91%以上の精度を達成。
- Cogito 8B: 全てのツール呼び出しタイプで89%以上のスコアを記録。これは、35%〜54%の範囲にとどまるLlama 3.1 8Bを大幅に上回る性能である。
この性能向上は、モデルアーキテクチャや学習データだけでなく、多くのベースラインモデルにはまだ欠けている「タスク固有の後処理(Post-training)」によるものだとDeep Cogitoは説明している。
今後の展望と業界へのインパクト
Deep Cogitoは、現在公開中のモデル群のチェックポイントを継続的に更新し、トレーニング期間を延長することで更なる性能向上を目指すとしている。同時に、前述の通り109Bから671Bまでのさらに大規模なモデルのリリースも控えており、IDA手法のスケーラビリティを実証しようとしている。
同社は、IDAを「スケーラブルな自己改善への長期的な道筋」と位置づけ、人間や静的な教師モデルへの依存から脱却することを目指している。CEOのArora氏は、「パフォーマンスベンチマークも重要だが、実世界での有用性と適応性がこれらのモデルの真のテストであり、我々はまだ急峻なスケーリングカーブの始まりにいると信じている」と強調する。
Deep Cogitoの登場と高性能なオープンソースモデルのリリースは、Meta、DeepSeek、Qwenといった既存のプレイヤーに加え、OpenAIやAnthropicなどがしのぎを削るAI開発競争に新たな刺激を与えることは間違いない。特に、独自のIDA手法が示す効率性とスケーラビリティが実証されれば、今後のLLM開発における新たな潮流を生み出す可能性もある。同社のオープンソース戦略は、AIコミュニティ全体の技術レベル向上にも貢献することが期待される。
なお、Cogitoモデルは既にHuggingfaceやOllamaでダウンロードするか、Fireworks AIやTogether AIのAPIを通じて直接使用することが可能となっている。
Sources
- Deep Cogito: Cogito v1 Preview
- via TechCrunch: Deep Cogito emerges from stealth with hybrid AI ‘reasoning’ models

