

Googleは、AIモデル「Gemini 2.0 Flash」にネイティブ画像生成機能を追加し、Google AI StudioとGemini APIを通じて開発者向けに一般公開した。同機能は2024年12月に発表されたものの当初は限定テスト段階だったが、今回の公開により開発者は単一のAIモデル内で会話を通じた画像生成や編集が可能になる。
単一モデルによる革新的な画像生成技術
Googleが公開したGemini 2.0 Flashのネイティブ画像生成機能は、米国の主要テクノロジー企業として初めて、マルチモーダル画像生成を単一モデル内で直接提供する画期的な技術だ。従来のAI画像生成ツールでは、大規模言語モデル(LLM)と画像特化型の拡散モデルを組み合わせる方式が一般的だった。例えばGoogleやOpenAIなどは、これまで言語モデル(Gemini)と拡散モデル(GoogleのImagenやOpenAIのDALL-E 3など)を接続し、テキストプロンプトと画像生成の間に解釈層を必要としていた。
これに対し、Gemini 2.0 Flashは言語処理と画像生成を単一モデル内で統合し、理論上ではより高い精度と新たな機能を実現している。実験版のGemini 2.0 Flash(gemini-2.0-flash-exp)は、Google AI Studioの「プレビュー」セクションから利用でき、出力形式を「Images + text」に設定することで、テキストと画像の両方を同時に生成できる。この機能は現在、Google AI Studioをサポートするすべての地域で利用可能だが、日々の利用制限が設けられている。
4つの主要機能と技術的優位性
Gemini 2.0 Flashのネイティブ画像生成は、以下の4つの主要機能を提供している:
- テキストと画像の統合ストーリーテリング:モデルはストーリーを生成しながら、キャラクターや設定の一貫性を維持したイラストを自動作成する。ユーザーからのフィードバックに応じて、ストーリーの内容や画像のスタイルを調整することも可能である。Google AI Studio製品責任者のLogan Kilpatrick氏(元OpenAI所属)は、3Dレンダリングされた子ヤギが登場する対話型ストーリーを紹介し、チャットベースの画像編集の有用性と楽しさを強調している。
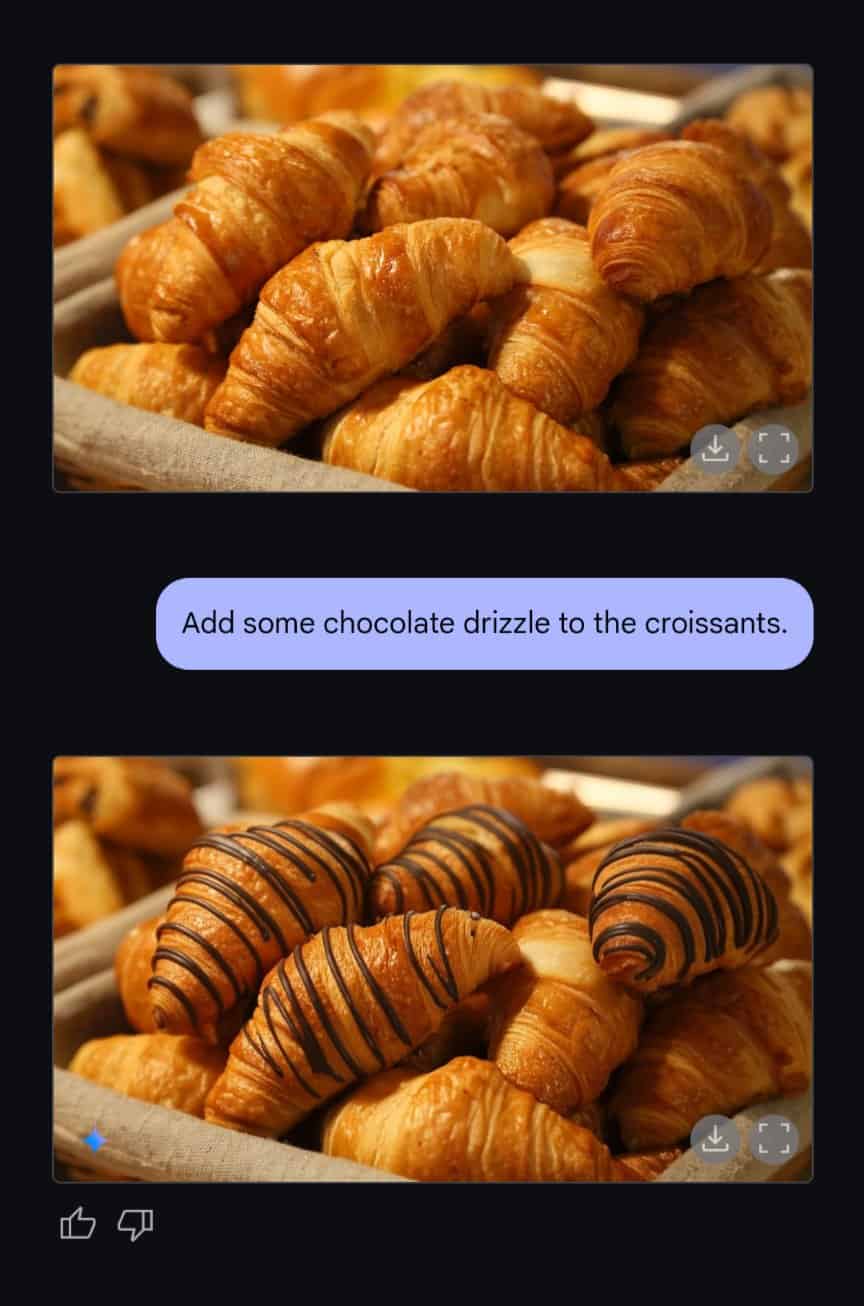
- 会話型画像編集:自然言語による対話を通じて、複数のターンにわたる画像編集をサポート。ユーザーは言葉で指示するだけで、画像の細部を段階的に調整できる。AIおよびテクノロジー教育者のPaul Couvert氏は「基本的に自然言語で任意の画像を編集できる」と述べ、Gemini 2.0 Flashで生成した画像だけでなく、既存の画像も編集可能であることを示した。また、ユーザー@Angaisb_(Angel氏)は「チョコレートをかける」というシンプルなプロンプトで、クロワッサンの画像を数秒で修正する例を共有し、モデルの迅速かつ正確な画像編集能力を実証した。
- 世界知識に基づく画像生成:モデルは一般的な世界知識と強化された推論能力を活用して、文脈に適した画像を生成する。これにより、レシピの各ステップをリアルに視覚化するなど、詳細かつ正確な画像表現が可能になる。Google DeepMind研究者のRobert Riachi氏は、モデルがピクセルアートスタイルの画像を生成し、さらにテキストプロンプトに基づいて同じスタイルの新しい画像を作成できることを示した。
- 高度なテキストレンダリング:多くの画像生成モデルが苦手とする長いテキストシーケンスの正確なレンダリングを実現。GoogleによるとGemini 2.0 Flashは、この点で主要な競合モデルより優れたパフォーマンスを示している。広告やソーシャルメディア投稿、招待状など、テキストを含む画像制作に特に有用である。
ユーザー事例と創造的可能性
初期のテスト結果からは、Gemini 2.0 Flashの多様な応用可能性が示されている。ユーザー@apolinarioと@fofrは、顔写真をアップロードして変形させる例を共有した。例えば、スパゲッティのボウルなどの小道具の追加や、被写体の視線方向を変更しながら驚くべき精度で被写体の特徴を保持する能力を示した。さらに、顔写真のみから全身画像を生成するなど、既存の情報を基に新たな視覚要素を創造する能力も実証された。
YouTuber「Theoretically Media」は、完全な再生成なしで画像の一部を編集できる機能を強調した。例えば、画像の残りの部分を保持しながらキャラクターの腕を上げるよう編集する例を示し、これがAI業界が長年待ち望んでいた機能だと述べている。
元Google社員でAI YouTuberとなったBilawal Sidhu氏は、モデルが白黒画像に色を付ける機能を紹介し、歴史的な写真の復元やクリエイティブな拡張といった応用の可能性を示唆した。
筆者も早速試してみたが、アップロードした犬の画像を指示通りに違和感なく加工してくれる能力を見せてくれた。

業界競争と差別化要因
Googleのこの発表は、AIによる画像生成の分野で重要な一歩と位置付けられる。競合するOpenAIは2024年5月にGPT-4oモデルで同様のネイティブ画像生成機能をプレビューしたものの、まだ一般公開はされていない。業界筋によると、OpenAIは2025年3月にこの機能を公開する予定だが、Googleの今回の発表により、マルチモーダルAIの実装においてGoogleがリードを取る形となった。
X(旧Twitter)ユーザー@chatgpt21(Chris氏)は、OpenAIが「1年以上のリードを失った」と指摘し、その理由についてOpenAI関係者からのコメントを求めている。この状況は、AI開発における両社の競争が一層激化していることを示唆している。
企業・開発者向けの価値提案
開発者や企業チームにとって、Gemini 2.0 Flashのネイティブ画像生成機能は以下のような幅広い応用が期待できる:
- AIを活用したデザインとマーケティング:マーケティングチームやコンテンツクリエイターにとって、従来のグラフィックデザインワークフローに代わる費用対効果の高い選択肢となる可能性がある。ブランドコンテンツ、広告、ソーシャルメディアビジュアルの作成を自動化し、特に画像内のテキスト描画が優れているため、広告作成やパッケージデザインなどへの応用が見込まれる。
- 開発者ツールとAIワークフローの拡張:CTOやCIO、ソフトウェアエンジニアにとって、アプリケーションやサービスへのAI統合を簡素化する。テキストと画像の出力を単一モデルで組み合わせることで、以下のような開発が可能になる:
- UI/UXモックアップやアプリアセットを生成するAI駆動設計アシスタント
- リアルタイムでコンセプトを視覚化する自動ドキュメント作成ツール
- メディアや教育向けの動的なAI駆動ストーリーテリングプラットフォーム
- AI駆動の生産性ソフトウェアの新たな可能性:企業チームが構築するAI駆動の生産性ツールにおいて、以下のようなアプリケーションをサポート:
- AI作成のスライドやビジュアルによる自動プレゼンテーション生成
- AI生成のインフォグラフィックによる法的・ビジネス文書の注釈付け
- 説明に基づく製品モックアップを動的に生成するEコマース視覚化
実装方法と開発者向け統合手順
開発者は、Gemini APIを使用してGemini 2.0 Flashの画像生成機能のテストを開始できる。Googleは、テキストと画像を含むストーリーを生成するAPIリクエストの例を提供している:
from google import genai
from google.genai import types
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.0-flash-exp",
contents=(
"Generate a story about a cute baby turtle in a 3d digital art style. "
"For each scene, generate an image."
),
config=types.GenerateContentConfig(
response_modalities=["Text", "Image"]
),
)
Googleは、AIエージェントの構築、イラスト付き対話型ストーリーなどの視覚的なアプリケーションの開発、または会話での視覚的なアイデアのブレインストーミングなど、さまざまな用途にこの機能が活用されることを期待している。開発者からのフィードバックは、本番環境向けバージョンの最終調整に役立てられるとしている。
Source