

Metaが、革新的な機械学習アプローチを実装する4つの事前トレーニング済み言語モデルをオープンソースとして公開した。「マルチトークン予測」と呼ばれるこの新しいアプローチは、大規模言語モデル(LLM)の開発と応用に大きな変革をもたらす可能性を秘めている。
AIの新たなパラダイムとなりうる“マルチトークン予測”
Metaが開発した新しい言語モデルの核心は「マルチトークン予測」という処理技術にある。このアプローチについては、4月に初めてMetaによって明らかにされたが、従来のLLMが1回に1トークン(数文字に相当)ずつテキストや コードを生成していたのに対し、Metaの新モデルは一度に4トークンを生成する。この手法により、AIの処理速度と精度の大幅な向上を実現しているのだ。
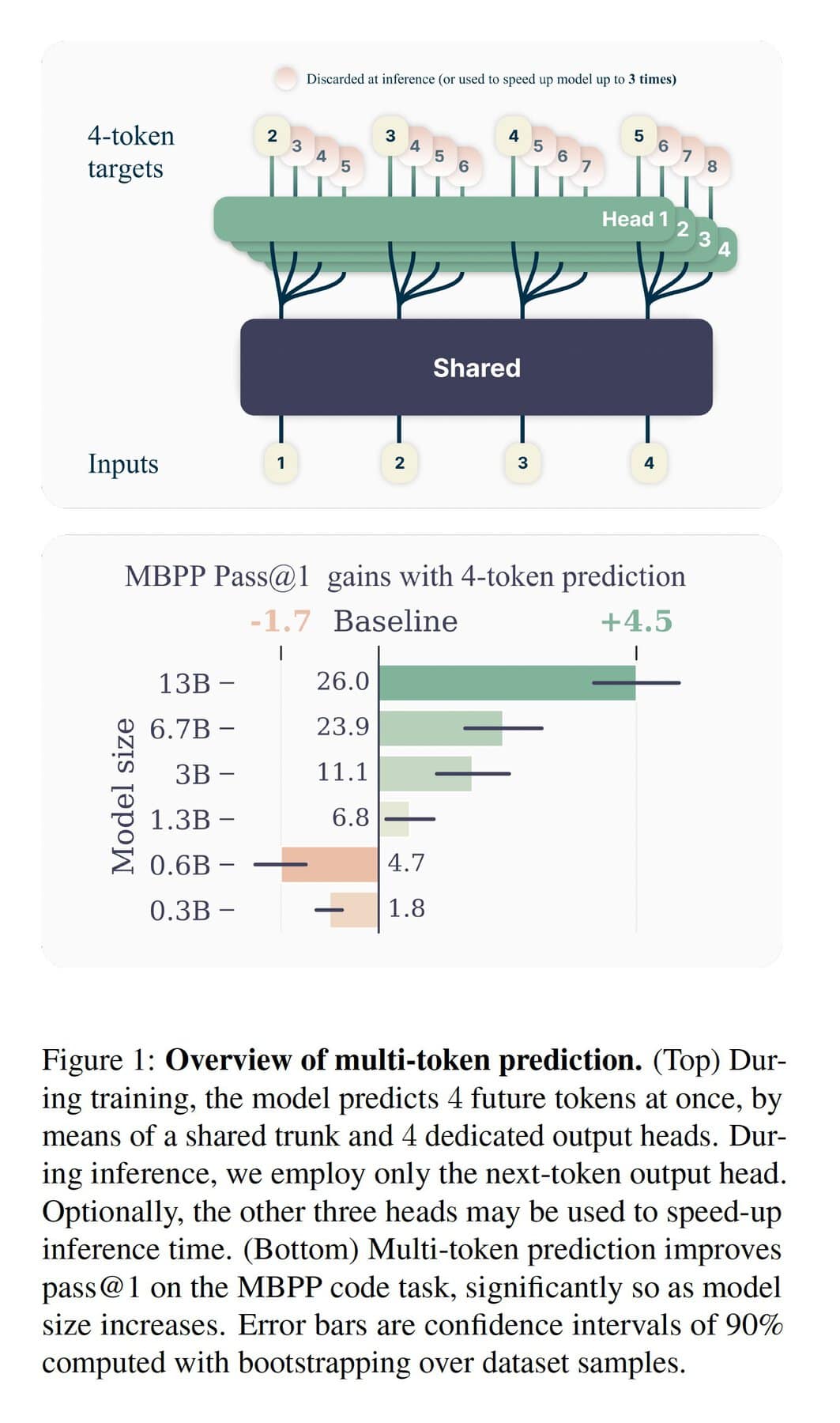
Metaの4つの新しいモデルはコード生成タスク向けで、それぞれ70億個のパラメータを備えている。 2つのモデルは2,000億トークン相当のコードサンプルで学習され、もう2つのモデルは1兆トークンで学習された。 Metaは、このモデルに付随する論文の中で、130億個のパラメーターを持つまだ未発表の5番目のLLMも開発したと詳述している。
各モデルは2つの主要コンポーネントから構成されている:
- 共有トランク(Shared trunk):コードスニペットの生成に関する初期計算を実行する。
- 出力ヘッド(Output heads):4つの出力ヘッドがそれぞれ1トークンずつ生成し、合計で4トークンを同時に出力する。
Metaによれば、共有トランクでコードスニペットの生成に必要な初期計算が実行された後、4つある出力ヘッドに渡される。出力ヘッドは一度に一つのトークンを生成出来るため、Metaのモデルは一度に4つのトークンを生成出来るのだ。
Metaは、MBPPとHumanEvalという2つのベンチマークテストを用いて性能評価を行った。MBPPには約1,000のPythonコーディングタスクを含まれており、HumanEvalでは複数のプログラミング言語にまたがる、より複雑なコーディングタスクをテストする。
結果は従来のLLMと比較して驚異的なものだった:
- MBPP:17%の性能向上
- HumanEval:12%の性能向上
- 出力生成速度:3倍に向上
Metaの研究者たちは、この新しいアプローチが高品質なコードを生成する理由について、現在の所その理由をつかめていない。だが、論文の中で従来のLLM開発で一般的に使用されてきた「Teacher Forcing」という訓練技術の限界を、マルチトークン予測が緩和している可能性があるという仮説を立てている。
開発者は通常、Teacher Forcingとして知られる手法を使ってLLMを訓練する。 この手法では、コード生成などのタスクをモデルに割り当て、ミスがあれば正しい答えを与える。 このアプローチは開発ワークフローの合理化に役立つが、学習されるLLMの精度を制限する可能性がある。
研究者らは次のように説明している:「Teacher Forcingは、生成されるシーケンス全体のより長期的な依存関係を無視する可能性がある代わりに、非常に短期的に予測をうまく行うことにモデルを集中させる傾向があります」。
つまり、一度に複数のトークンを予測することで、モデルがより広い文脈を考慮できるようになり、結果として高品質な出力が可能になるという考えだ。
Metaの今回の発表は、激化するAI開発競争の中での戦略的な動きと見られている。マルチトークン予測モデルの公開は、同社が画像からテキストへの生成や AI生成音声の検出など、複数のAI領域でリーダーシップを確立しようとしている広範な取り組みの一環なのだ。
この動きは、AI研究とその応用の広範な領域に影響を与える可能性がある。コード生成から創造的な文章作成まで、AIの能力が飛躍的に向上する可能性が開かれたのだ。
研究者たち自身も、彼らのアプローチが「モデルの能力と訓練効率を向上させながら、より高速な処理を可能にする」と述べており、この大胆な主張は AI開発の新たな段階の幕開けを告げるものかもしれない。
Sources
- Hugging Face: facebook/multi-token-prediction
- VentureBeat: Meta drops AI bombshell: Multi-token prediction models now open for research









コメント