

Metaは、これまでで最大規模となるオープンな大規模言語モデル「Llama 3.1 405B」をリリースした。この巨大なモデルは、4050億ものパラメータを持ち、これまでのオープンソースモデルの中で最高峰の性能を誇る。Metaによれば、その能力は、GPT-4やClaude 3.5 Sonnetといった最先端の商用AIモデルと肩を並べるほどとのことだ。
最初のフロンティアレベルのオープンソースAIモデル
Llama 3.1 405Bの特筆すべき点は、その多言語対応能力と拡張されたコンテキスト長にある。8つの言語をサポートし、128,000トークンという長大なコンテキストを処理できるこのモデルは、複雑な翻訳タスクや長文の要約、さらには高度な推論を必要とする課題にも対応可能だ。これにより、ビジネスや研究分野での応用範囲が大きく広がることが期待される。ただし、Llama 3.1 405Bはマルチモーダル・モデルではなく、テキスト専用なので、画像に関する質問には答えられない。ただし、PDFやスプレッドシートなどのテキストベースファイルを取り扱うことは可能だ。
本日同時に発表された論文によれば、Metaはマルチモダリティの実験も行っているようだ。同社の研究者は、画像やビデオを認識し、音声を理解(生成)できるLlamaモデルを積極的に開発していると書いている。
Metaは、Llama 3.1 405Bの開発に巨額の投資を行っており、16,000台以上のNVIDIA H100 GPUを使用して15兆以上のトークン(トークンとは、モデルが単語全体よりも容易に内包できる単語の一部であり、15兆トークンは7,500億語に相当する)でモデルを訓練した。Metaは以前のLlamaモデルをトレーニングするためにベースセットを使用していたため、それ自体は新しいトレーニングセットではないが、同社はこのモデルの開発において、データのキュレーションパイプラインを改良し、「より厳格な」品質保証とデータフィルタリングアプローチを採用したと主張している。
同社はまた、Llama 3.1 405Bを微調整するために合成データ(他のAIモデルによって生成されたデータ)を使用した。 OpenAIやAnthropicを含む主要なAIベンダーのほとんどは、AIトレーニングの規模を拡大するために合成データの適用を模索しているが、専門家の中には、合成データはモデルの偏りを悪化させる可能性があるため、その利用には賛否がある。Metaは、“慎重にバランスを取った”と主張している。 Llama 3.1 405Bのトレーニングデータについては、Metaは正確なデータの出所については明かさなかった。 多くの生成AIベンダーは、トレーニングデータを競争上の優位性と考えているため、トレーニングデータとそれに関連する情報を明らかにすることに後ろ向きだ。また、トレーニングデータの詳細は、知的財産権に関連する訴訟の原因となる可能性もあり、企業が多くを明らかにしないもう一つの理由ともなっている。
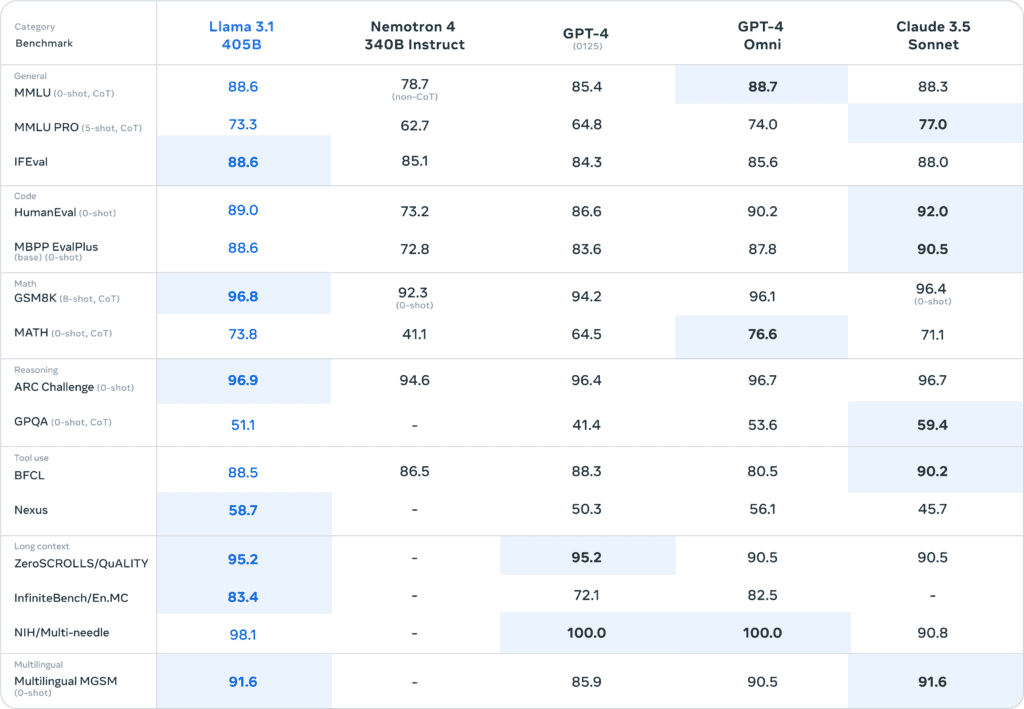
Metaが発表したチャートによると、405BはMMLU(学部レベルの知識)、GSM8K(小学生の算数)、HumanEval(コーディング)などのベンチマークでGPT-4 Turbo、GPT-4o、Claude 3.5 Sonnetの性能に非常に近い値を示している。 しかし、これらのベンチマークは最先端AIモデルの性能を測定する指標として必ずしも正しいとは言えなくなってきており、業界では新たなベンチマークテストの開発を模索している。
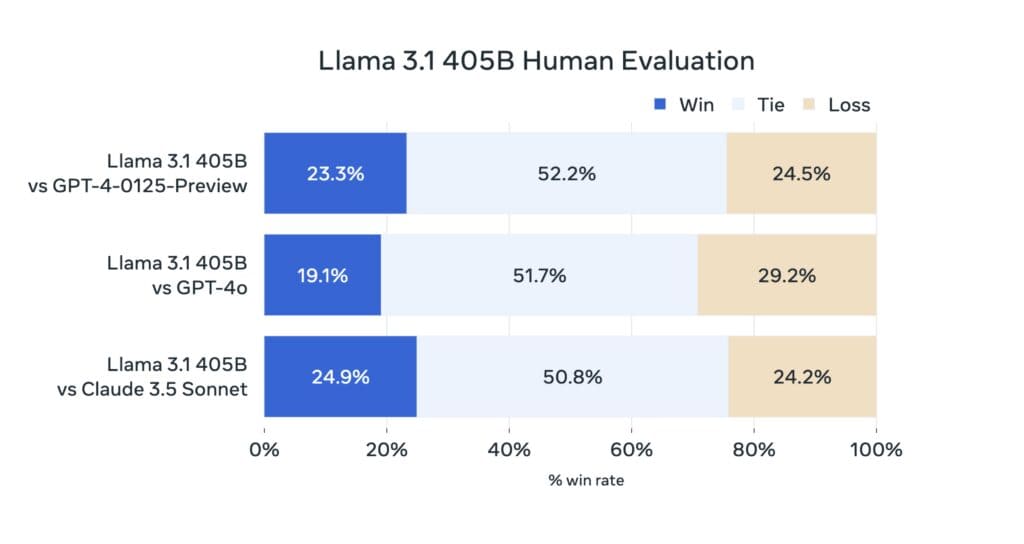
また、AI言語モデルとの対話の主観的な体験に通じるものとして適切とも言えなくなっており、チャットボット・アリーナ(Chatbot Arena)のようなA/Bリーダーボードで(「バイブマーキング(vibemarking)」と呼ばれるものによって)会話AIモデルを使用した主観的な経験を測定することが、新しいLLMを判断するためのより良い方法であると見られる様になってきている。今回Llama 3.1 405BはまだChatbot Arenaのデータがないため、Metaは405Bの出力に対する独自の人間による評価結果を提供しており、Metaの新しいモデルがGPT-4 TurboやClaude 3.5 Sonnetに対抗していることを示そうとしている。
Metaは今回のリリースに合わせて、AIの悪用や倫理的問題といった課題に対処するため、同時に新たなセキュリティツールもリリースした。Llama Guard 3、Prompt Guard、CyberSecEval 3といったツールは、AIの安全な利用を促進するための重要な取り組みだ。これらのツールは、AIモデルの入出力管理、プロンプトインジェクション攻撃からの保護、サイバーセキュリティリスクの評価など、AIの実用化に伴う様々な課題に対応することを目指している。
Metaは、「Llama 3.1 405Bは、一般知識、操縦性、数学、道具の使用、多言語翻訳における最先端の能力に関して、トップクラスのAIモデルに匹敵する、オープンに利用可能な最初のモデルです」と述べている。 MetaのMark Zuckerberg CEO、405Bを “最初のフロンティアレベルのオープンソースAIモデル”と呼んでいる。
AI業界では、「フロンティア・モデル」とは、現在の機能の限界を押し広げるために設計されたAIシステムを指す用語だ。この場合、Metaは405Bを、OpenAIのGPT-4o、Claudeの3.5 Sonnet、Google Gemini 1.5 Proなど、業界のトップAIモデルに比肩する物と位置づけている。
しかし、この「オープンソース」という言葉の使用には議論の余地がある。独立AIリサーチャーのSimon Willisonは、Zuckerberg氏の主張を概ね支持しつつも、「オープンソース」という用語の誤用を「小規模な文化的破壊行為」と批判している。Llama 3.1モデルは、確かにコードと重みが公開されているが、ダウンロードには連絡先情報の提供とライセンス同意が必要であり、厳密な意味でのオープンソースとは異なるからだ。最悪なケースとして、Meta はいつでも Llama 3.1 またはその出力の使用を法的に禁止できるということには注意が必要だろう。
Metaがこのような巨大モデルを無償で公開する背景には、複雑な戦略がある。一つは、独自の「AIエコシステム」を構築し、開発者を引き付けたいという狙いだ。さらに、コミュニティによるモデルの改善が、Metaの製品向上にも寄与するという相乗効果も期待できる。また、MicrosoftやGoogleなど、より優れたインフラと補完的なビジネスモデルを持つ企業がAI分野でMetaを追い越す可能性に対する牽制も含まれているだろう。
この発表はまた、MetaとNVIDIAのパートナーシップの拡大も強調している。 NVIDIAはMetaの重要なパートナーであり、Llamaの最新バージョンを含む同社のAIモデルの学習に役立つGPUと呼ばれるコンピューティング・チップをMetaに提供する事で、この開発に貢献している。
Llama 3.1 405Bの登場は、AIの未来に向けた重要な一歩であり、オープンソースモデルと商用モデルの競争を一層激化させるだろう。この発展が、AIの進歩と社会への貢献にどのようにつながっていくか、今後の動向が注目される。
論文
参考文献
- Meta: Introducing Llama 3.1: Our most capable models to date
- GitHub: meta-llama/llama-models
- Hugging Face: Llama 3.1







コメント
コメント一覧 (1件)
[…] Xenospectrumの報道 […]