

NVIDIAは次世代AIプラットフォームBlackwellの稼働開始を発表し、遅延に関する噂を一蹴した。Hot Chips 2024カンファレンスを前に、同社はBlackwellサーバーの設置と構成の様子を公開すると共に、さらに、革新的な液冷技術や新たな量子化システムなど、AIと高性能コンピューティングの未来を形作る先進技術の詳細も明らかにした。
NVIDIAのBlackwell:AIの新時代を切り拓く総合プラットフォーム
NVIDIAのBlackwellは、単なるGPUの枠を超えた包括的なエコシステムとして設計されている。Dave Salvator氏(NVIDIAのアクセラレーテッドコンピューティング製品部門ディレクター)は「NVIDIA Blackwellはプラットフォームであり、GPUはその始まりに過ぎません」と述べ、Blackwellの全体像を示唆している。

Blackwellプラットフォームは、複数のNVIDIAチップで構成される総合的なソリューションだ。BlackwellGPU、GraceCPU、BluefieldDPU、ConnextXネットワークインターフェースカード、NVLinkスイッチ、SpectrumEthernetスイッチ、QuantumInfiniBandスイッチなど、各コンポーネントが緊密に連携することで、大規模言語モデル(LLM)の推論と加速コンピューティングを可能にしている。
Blackwellの中核を成すGPUは、TSMCの4NPプロセスを採用した2080億トランジスタの巨大チップだ。20ペタFLOPSのFP4 AI性能、8TB/秒のメモリ帯域幅、8サイトのHBM3eメモリを特徴とし、1.8TB/秒の双方向NVLINKバンド幅を提供する。これらの仕様は、AIワークロードに対する圧倒的なパフォーマンスを示唆している。

特筆すべきは、NVIDIAが従来のH100 GPUと比較して、Blackwellが1兆パラメータのLLMをリアルタイムで実行できる能力を持ち、コストと消費電力を25分の1に抑えられると主張している点だ。この飛躍的な性能向上は、AIの応用範囲を大きく広げる可能性を秘めている。
NVIDIAはBlackwellの能力をさらに引き出すために、NVLinkスイッチも強化した。新しいNVLinkスイッチは、ファブリック帯域幅を1.8TB/秒に倍増させ、GB200 NVL72ラックで最大72個のGPUをサポートする。この800mm²のダイは、72ポートを介して7.2TB/秒の双方向帯域幅を提供し、3.6TFLOPSのネットワーク内コンピュート能力を持つ。この強化されたインターコネクトは、複数のGPUを効率的に連携させ、より大規模で複雑なAIモデルの処理を可能にする。




冷却技術の革新も、Blackwellプラットフォームの重要な特徴だ。Ali Heydari氏(NVIDIAのデータセンター冷却およびインフラストラクチャ部門ディレクター)は、温水直接チップ冷却アプローチについて発表する予定だ。この技術は、データセンターの消費電力を最大28%削減できる可能性がある。従来のチラーを使用せず、温水を直接利用することで、エネルギー効率を大幅に向上させている。これは、急増するAIワークロードに伴う電力需要の課題に対する、NVIDIAの革新的な解決策と言える。

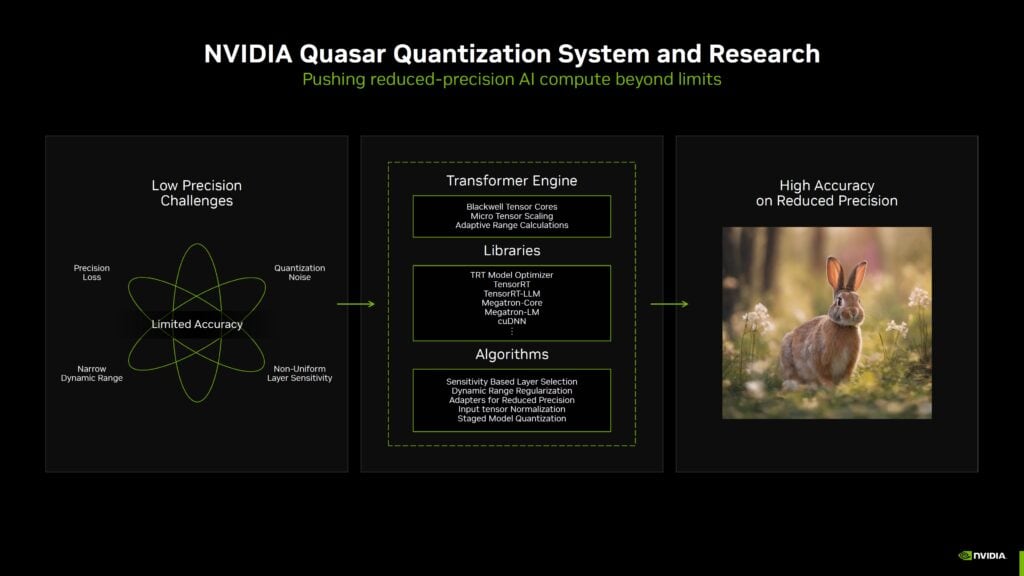
さらに、NVIDIAは新しいQuasar Quantization Systemを発表した。このソフトウェアは、BlackwellのTransformer Engineを利用して、低精度モデルでも高い精度を実現する。FP4(4ビットの浮動小数点精度)技術により、モデルのメモリ使用量を削減しながら、パフォーマンスと精度を向上させることができる。NVIDIAは、FP4を使用したStable Diffusionモデルで生成された画像を公開し、FP16モデルと遜色ない品質を示している。この技術は、AIモデルの効率性と実用性を大きく向上させる可能性を秘めている。

NVIDIAは、AIを活用してチップ設計プロセスを改善する取り組みも行っている。Mark Ren氏(NVIDIAの設計・自動化部門ディレクター)は、質問応答、コード生成、設計問題のデバッグを支援するAIモデルについて発表する予定だ。特に注目すべきは、NVIDIAが開発したVerilogコードの生成を加速するLLMだ。このAIは、208億トランジスタを持つBlackwell B200 GPUの設計に貢献し、次世代のRubin GPUの開発にも活用される予定だ。これは、AIが自身の進化を加速させるという、興味深い循環を生み出している。

NVIDIAのBlackwellプラットフォームは、AIと高性能コンピューティングの未来を形作る革新的な技術の集大成と言える。Hot Chips 2024カンファレンスでは、Blackwellアーキテクチャの詳細、コンピュータ支援設計における生成AIの活用、そして液冷技術について、さらに詳細な情報が公開される予定だ。また、NVIDIAは既にBlackwell Ultraを2025年に、Vera CPUとRubin GPUを2026年に、そしてVera Ultraを2027年に発表する計画を示しており、継続的な技術革新への強いコミットメントを示している。

この一連の発表は、AIと高性能コンピューティングの分野におけるNVIDIAの主導的立場を強化するものであり、今後のテクノロジー業界の動向に大きな影響を与えることが予想される。
Sources







コメント