

NVIDIAはGTC 2025カンファレンスで、自律的なAIエージェント構築基盤となる「Llama Nemotron」推論モデルシリーズと関連技術を発表した。Metaの「Llama」をベースに強化されたこのオープンソースモデルは、従来の推論モデルと比較して最大20%の精度向上と5倍の処理速度を実現。Microsoft、SAP、Accentureなど主要テック企業が早くも採用を表明している。
Llama Nemotronモデル:3つのサイズで柔軟な推論能力を提供
NVIDIAのLlama Nemotronモデルシリーズは、Meta(旧Facebook)のオープンソースLlamaモデルをベースに大規模な後期訓練(ポスト・トレーニング)を施し、推論能力を大幅に強化したものだ。このモデルファミリーは、使用環境に応じた3つのサイズで提供される:
- Nano:8Bパラメータ、PC・エッジデバイス向けで最高精度を実現
- Super:49Bパラメータ、単一データセンターGPUでの最適な精度と高スループットを提供
- Ultra:253Bパラメータ、マルチGPUサーバー環境で最大限のエージェント精度を実現(近日公開予定)
Llama Nemotronの最大の特徴は「推論オン/オフ切り替え機能」だ。システムプロンプトを変更するだけで、高度な推論が必要な複雑タスクと、一般的な応答で済む単純タスクを同一モデルで効率的に処理できる。この機能はAnthropicのClaude 3.7やIBM Granite 3.2なども提供しているが、オープンソースモデルでは初の取り組みとなる。
開発過程では、NVIDIA DGX Cloudで600億トークンの高品質合成データを活用。36万時間のH100 GPU推論と4万5千時間の人間によるアノテーション作業を経て、数学問題解決、コーディング、複雑な意思決定など多様な能力を向上させている。GPQA Diamond、AIME、MATH 500、BFCLなどの業界標準ベンチマークで高いスコアを達成した。

モデル開発に使用したツール、データセット、最適化技術もオープンに公開されており、企業や開発者が独自の推論モデルを構築できる基盤となる。Llama NemotronはNVIDIA NIMマイクロサービスとして提供され、build.nvidia.comおよびHugging Faceからアクセス可能だ。NVIDIA Developer Programメンバーは開発・テスト・研究目的での無料利用ができる。
Dynamo:推論処理を革新するソフトウェア基盤

NVIDIAは推論モデルの性能を飛躍的に向上させる新たなオープンソースソフトウェア「NVIDIA Dynamo」も発表した。Triton Inference Serverの後継となるこのソフトウェアは、AIサービスのトークンスループットを最大化するために特別設計されている。
Dynamoの中核は「Disaggregated Serving(分離サービング)」と呼ばれる手法だ。この技術はLLMの処理と生成フェーズを異なるGPUに分散させ、それぞれのフェーズを独立して最適化する。これにより単一クエリを最大1,000個のGPUで拡張処理できるようになり、同じGPU数でも処理量を2倍に向上させる。
さらに、NVIDIAの最新GPU通信技術「NYリンク」と組み合わせると、DeepSeek-R1のような大規模モデルをGB200 NVL72ラックの大規模クラスタで実行した場合、GPU当たりのトークン生成数を最大30倍に増加させる効果がある。これはAIサービスの収益性向上と運用コスト削減に直結する。
Dynamoは負荷変動に応じてGPUの追加・削除・再割り当てを動的に行える機能も備えており、PerplexityAIなど複数企業がすでに導入を計画している。
AI-Q Blueprint:エージェント開発のための統合フレームワーク
NVIDIA AI-Q Blueprintは、企業がAIエージェントを効率的に構築・連携させるためのフレームワークだ。2025年4月から提供予定のこの技術は、AIエージェントを企業の知識ベースに接続し、自律的な判断・行動を可能にする。
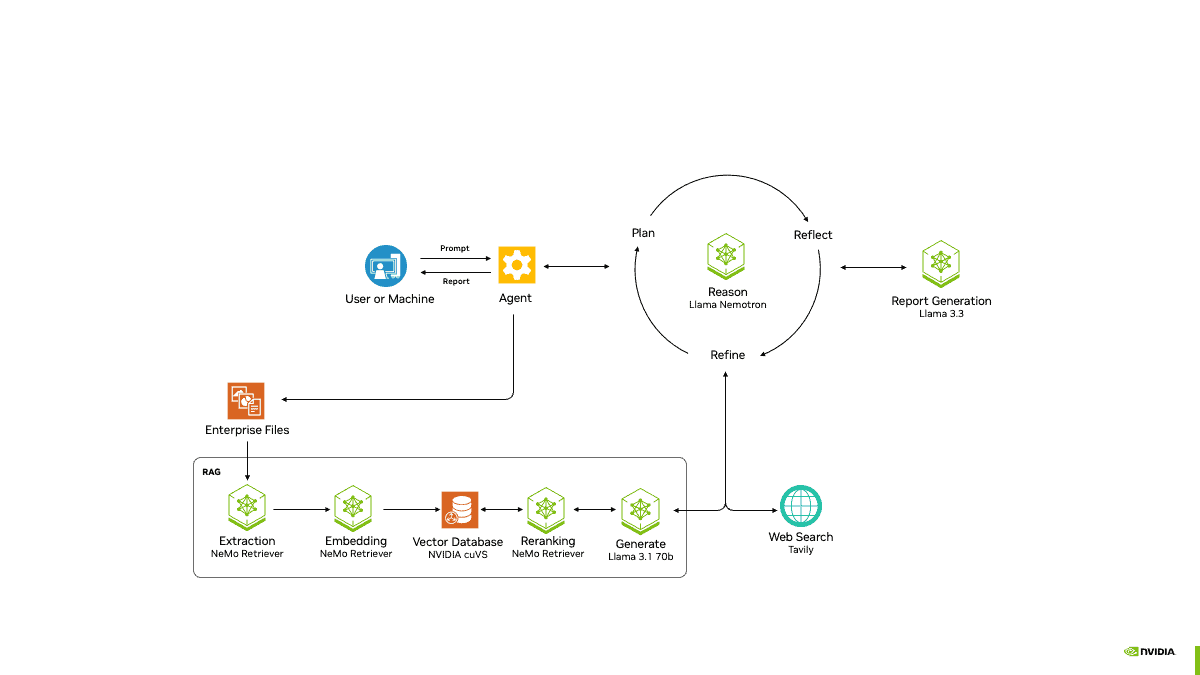
AI-Q Blueprintは、テキスト、画像、動画など多様なデータ形式からの情報検索を実現する「NVIDIA NeMo Retriever」と統合されている。オープンソースの「NVIDIA AgentIQ」ツールキットと組み合わせることで、エージェントとデータの接続・最適化・透明性を確保できる。
補完技術として「NVIDIA AI Data Platform」も発表された。これはDell、HPE、IBM、NetAppなど主要ストレージプロバイダー向けのカスタマイズ可能な参照設計で、AIエージェントのデータ活用効率を高める。NVIDIAの加速コンピューティングハードウェアと最適化されたストレージリソースを組み合わせることで、AI推論における情報フローをスムーズにする。
主要企業との協力体制が広がる
NVIDIAのLlama Nemotronモデルは、すでに多くの主要企業で採用が進んでいる:
- Microsoft:Llama NemotronモデルとNIMマイクロサービスをAzure AI Foundryに統合し、Azure AI Agent Service for Microsoft 365のオプションとして提供
- SAP:SAP Business AIソリューションとAIコパイロット「Joule」強化に活用。ユーザークエリの洗練と書き換えを通じて、よりスマートなAI体験を提供
- ServiceNow:産業横断的な企業生産性向上のためにモデルを活用
- Accenture:AI Refineryプラットフォームでモデルを利用可能に。業界特有の課題に対応したカスタムAIエージェント開発を支援
- Deloitte:最近発表したZora AIエージェントプラットフォームへの統合を計画
このような広範な採用は、NVIDIAのAIエージェント技術が実ビジネス環境での実用段階に達していることを示している。
エージェントAI市場での競争力強化を図る
今回のLlama Nemotronシリーズ発表は、オープンソース推論モデル市場におけるNVIDIAの競争力強化を明確に示すものだ。特に、今年初めにDeepSeek R1が発表された際にNVIDIAの株価が影響を受けたことを考えると、同社が推論モデル分野での主導権確立を重視していることが伺える。
NVIDIAは従来のGPUハードウェア提供だけでなく、推論モデル、エージェント構築フレームワーク、データプラットフォームまで一貫したエコシステムを提供する戦略を鮮明にしている。特にオープンソースアプローチを採用することで、企業がデータ主権やプライバシー要件を満たしながら社内システムに推論AIを組み込みやすくなる。
これらの技術は、2026年半ばに発表予定の次世代GPU「Vera Rubin」をはじめとする将来のハードウェアロードマップとも連動しており、NVIDIAがAIエージェント技術の長期的リーダーシップを目指していることが明らかだ。
Sources

