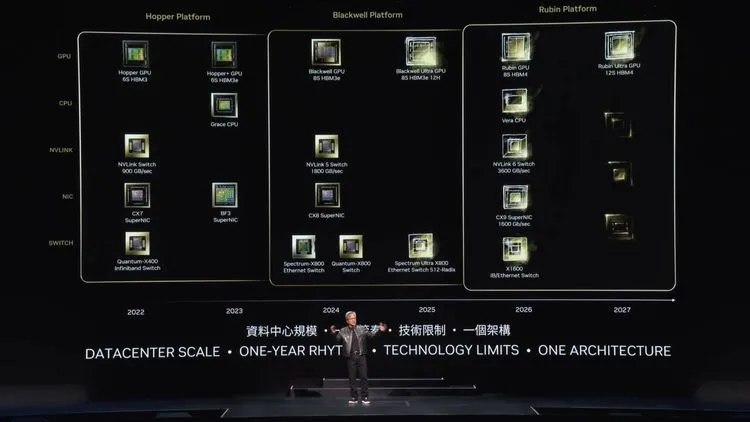
NVIDIAは年次開発者会議GTC 2025で、新世代のAIチップ「Blackwell Ultra」と将来のGPUアーキテクチャ「Vera Rubin」を発表した。Blackwell Ultraは2025年後半から出荷予定で、現行Blackwellと比較して最大50%高いメモリ容量と計算能力を提供。2026年後半に出荷予定のVera Rubinは現行チップの3.3倍、その後継「Rubin Ultra」は14倍の性能を実現し、NVIDIAの半導体市場における圧倒的地位をさらに強化する見込みだ。
Blackwell Ultra:推論AI時代のための強化されたチップ
Blackwell Ultraは既存のBlackwellアーキテクチャをベースにしながらもAI推論性能を大幅に向上させた新製品だ。具体的なスペックとしては、15ペタフロップスのFP4演算性能(B200比50%増)と288GB HBM3eメモリ(同じく50%増)を搭載している。

特筆すべきは推論処理の高速化だ。同社の説明によれば、DeepSeek-R1などの「推論」AIモデルを実行する場合、Hopperアーキテクチャ(H100)と比較して10倍のスループットを実現。これにより、以前なら1分30秒かかっていた質問応答が約10秒で完了する。毎秒1,000トークンを処理できるため、よりリアルタイムに近い対話体験が可能になる。
「AIは大きな飛躍を遂げました。推論型AIとエージェント型AIは桁違いの計算性能を要求します」とNVIDIA創業者兼CEOのJensen Huang氏は語る。「Blackwell Ultraはこの瞬間のために設計されました。事前学習、事後学習、推論AIインファレンスを簡単かつ効率的に行える単一の多目的プラットフォームです」
Blackwell Ultraは複数の形態で提供される:
- GB300 NVL72:72個のBlackwell Ultra GPUと36個のGrace CPUを一つの液冷ラックに統合
- HGX B300 NVL16:16個のGPUを搭載した伝統的なサーバー形態
- DGX Station:単一GB300チップを搭載したワークステーション
特にNVL72は20テラバイトのHBM3eメモリを実現し、より大規模なAIモデルのデプロイを可能にする。これをさらに拡張したSuperPODは576個のBlackwell Ultra GPUと288個のGrace CPUを組み合わせ、300テラバイトのメモリと11.5エクサフロップスのFP4計算能力を提供する。
Vera RubinとRubin Ultra:3年先を見据えた次世代アーキテクチャ
Blackwell Ultraの発表と同時に、NVIDIAは次世代GPUアーキテクチャ「Vera Rubin」も発表した。2026年後半に出荷予定のRubinは、以下の特徴を持つ:
- 50ペタフロップスのFP4性能(Blackwellの2.5倍)
- 288GB HBM4メモリ
- カスタム設計の88コアVera CPUを搭載
- 毎秒13テラバイトのメモリ帯域幅
- ダブルサイズのレティクルGPU設計

さらに2027年後半には「Rubin Ultra」が予定されており、以下の仕様が予告されている:
- 100ペタフロップスのFP4性能(Blackwell Ultraの約7倍)
- 1テラバイトのHBM4eメモリ
- 4レティクルサイズのGPU設計

Rubin Ultra NVL576システムは15エクサフロップスのFP4推論と5エクサフロップスのFP8トレーニング能力を持ち、現行のBlackwell Ultraラックと比較して14倍のパフォーマンスを実現する見込みだ。

さらにNVIDIAは2028年までのロードマップを更新し、次世代アーキテクチャ「Feynman」が2028年に予定されており、物理学者Richard Feynmanにちなんで命名されたことも明らかにされた。

産業への影響とエコシステム
NVIDIAの新チップはすでに業界全体から大きな注目を集めている。同社によれば、Blackwellシリーズはすでに110億ドルの売上を記録。上位4社だけで2025年前半までに180万個のBlackwellチップを購入したという。
主要サーバーベンダーのCisco、Dell、HPE、Lenovo、Supermicroをはじめとする多数のメーカーがBlackwell Ultra製品を採用予定。クラウドプロバイダーではAWS、Google Cloud、Microsoft Azure、Oracle Cloud Infrastructureなどが新チップを搭載したインスタンスを提供する見込みだ。
ソフトウェア面では新たに「NVIDIA Dynamo」と呼ばれるオープンソース推論フレームワークも発表された。このフレームワークは何千ものGPUにわたる推論通信をオーケストレーションし、大規模言語モデルの処理と生成フェーズを異なるGPUに分離することで、各フェーズを独立して最適化できる。
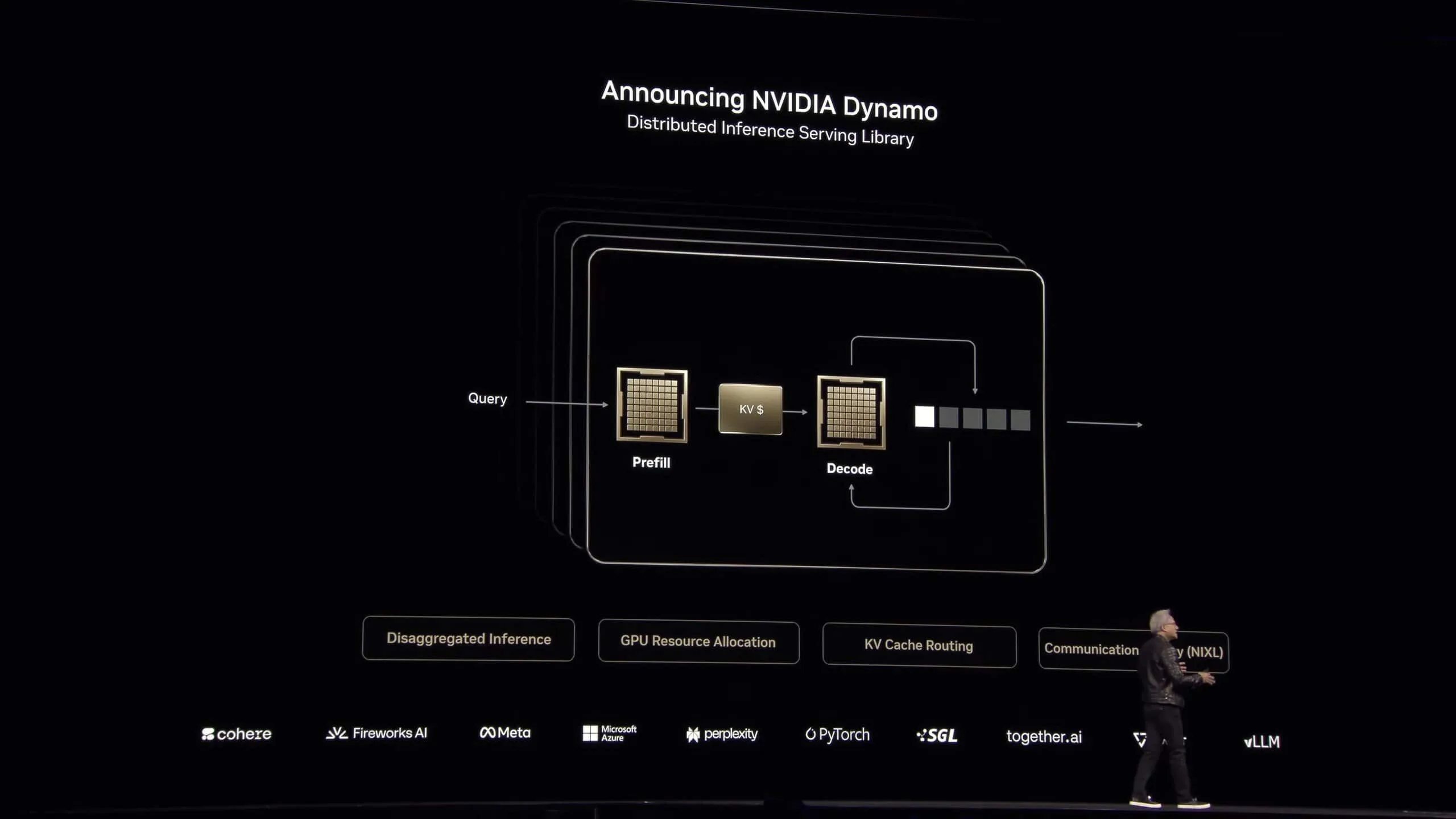
これにより推論型AI時代の高効率な運用が可能になり、NVIDIAのAI市場における支配的地位がさらに強化されると見られている。AMDなど競合他社の動向も注目されるが、現状ではNVIDIAのロードマップに追いつくのは容易ではないと分析されている。
Sources