

NVIDIAは先日GTC 2024において次世代AI GPUアーキテクチャ「Blackwell」と共に、B200 GPUやGB200 スーパーチップを発表したが、仕様以外ではあまり細かな数字は明らかにされず、性能指標なども大雑把なものであった。AI需要が高止まりしている中、人々のこのチップへの期待は高まっているが、実際にこのGPUが市場に現れるのは今年の後半だ。それまでは徐々に明らかになる情報に食いつくほかないが、今回NVIDIAはBlackwell GPUが、量子コンピューティング、創薬、核融合エネルギー、物理学ベースのシミュレーション、科学的コンピューティングなどを含む研究分野でどのような性能を発揮するのか、いくつかの詳細な性能数値を明らかにしている。
アプリケーションによっては桁違いの性能向上をもたらす
NVIDIAはBlackwell GPUアーキテクチャの採用により、計算スピードの向上が見込まれることと共に、コストとエネルギー要件に大きなメリットがもたらされるとしている。
NVIDIAは従来の科学計算および物理ベースのシミュレーションにおいて用いられる、FP64(浮動小数点)性能でHopper GPUに比べて30%の性能向上が見込まれるとのことだ。シングルBlackwell B100 GPUは約45 TFLOPsの演算性能を提供する。Blackwellの大半はGB200 Superchipで、Grace CPUとともに2つのGPUを搭載しているため、約90TFLOPsのFP64演算能力が見込まれる。
この演算能力がもたらすメリットとして、集積回路設計の場において、Cadence SpectreXシミュレーターのパフォーマンスが、NVIDIAのGB200スーパーチップを用いれば、従来のCPUに比べて13倍もの速さで回路シミュレーションを実行できる事を報告している。
計算流体力学(CFD)シミュレーションソフトウェアのCadence Fidelityや、デジタルツインソフトウェアのCadence Realityにおいてもそれぞれ22倍、30倍という驚異的なパフォーマンス向上が見込まれるという。
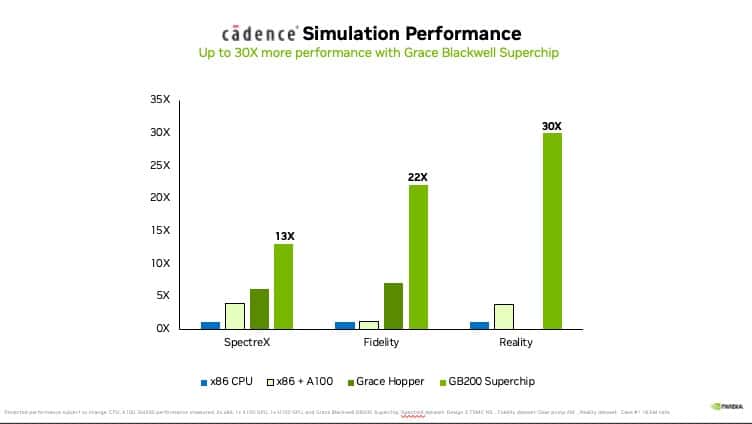
時間の節約だけではなく、大きなエネルギー効率の向上が見込まれる。
Blackwellアーキテクチャでは第2世代のTransfomer Engineが搭載されているが、これによって1.8兆パラメータのGPT-MoE(Generative Pretrained Transformer-Mixture of Experts)モデルでは、H100の30倍ものスピードアップを果たすと述べている。GB200 NVL72プラットフォームは、25倍高いエネルギー効率と25倍低いTCO(総運用コスト)を達成しながら、最大30倍高いスループットを可能にするということだ。GB200 NVL72システムを72個のx86 CPUと比較しただけでも、Blackwellシステムは18倍、GH200 NVL72システムはデータベース・ジョイン・クエリーにおいて3.27倍の利得を得ている。
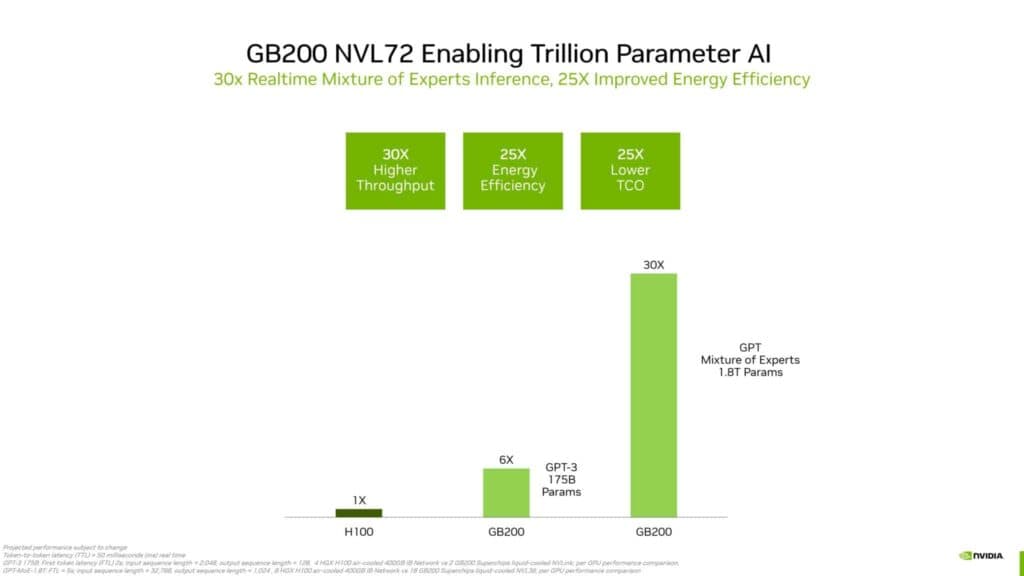
性能の飛躍と電力効率は、科学計算のワークロード完了時間とエネルギー消費の大幅な削減を意味する物であり、十分にBlackwellの導入の動機となりうるだろう。
Source








コメント