OpenAIは、新世代AIモデル「GPT-4.1」シリーズを発表した。コーディング能力と指示追従性能が大幅に向上し、従来の8倍となる100万トークンの長文処理が可能になった新モデルは、API経由で即時利用可能となっている。同社はベンチマークスコアの大幅改善と共に、GPT-4oより26%安い価格設定で、Google、Anthropicなど競合他社との技術・価格競争を一層激化させる展開となった。
GPT-4.1ファミリー登場:開発者のニーズに応える新世代AI
OpenAIが発表したのは3つの新モデル—「GPT-4.1」「GPT-4.1 mini」、そして同社初となる“nano”を冠した「GPT-4.1 nano」だ。これらは、2024年7月に発表されたGPT-4oおよびGPT-4o miniの後継、あるいは上位版と位置づけられ、特に開発者コミュニティからのフィードバックを強く意識して設計されている点が特徴だ。

主な改善点として、OpenAIは以下の点を挙げている。
- コーディング能力の大幅向上: 実世界のソフトウェア開発タスクにおける性能向上、コード差分(diff)生成の信頼性向上など。
- 命令追従性の強化: より複雑な指示や指定されたフォーマットへの追従能力向上。
- 長文脈処理能力の飛躍的拡大: 最大100万トークン(GPT-4oの128kから8倍)のコンテキストウィンドウと、その長大な文脈を効果的に活用する能力の向上。
- 知識の更新: 2024年6月までの情報に基づいて学習。
- コスト効率の改善: 性能向上と同時に、いくつかのモデル・ユースケースでコスト削減を実現。
これらのモデルは現時点ではAPI経由でのみ提供され、ChatGPTのインターフェースで直接利用することはできない。ただし、OpenAIによれば、GPT-4.1で実現された命令追従性やコーディング、知能に関する改善点の多くは、既に最新版のGPT-4oに段階的に組み込まれており、今後も継続的に反映されていく予定とのことだ。
また、この発表に伴い、これまでプレビュー版として提供されていたGPT-4.5 Previewは、GPT-4.1がより低コスト・低遅延で同等以上の性能を発揮することから、2025年7月14日をもって廃止されることが決定した。OpenAIは、GPT-4.5で評価された創造性や文章品質、ユーモアといった特性は、将来のAPIモデルに引き継いでいくとしている。
性能徹底解剖:「GPT-4.1」の真価とは
今回の発表で最も注目されるのは、その性能向上だ。主要な改善点を詳細に見ていこう。
1. コーディング能力:開発現場の要求に応える進化
GPT-4.1は、ソフトウェア開発の現場で求められる実用的なコーディング能力において、大きく進歩を遂げている。
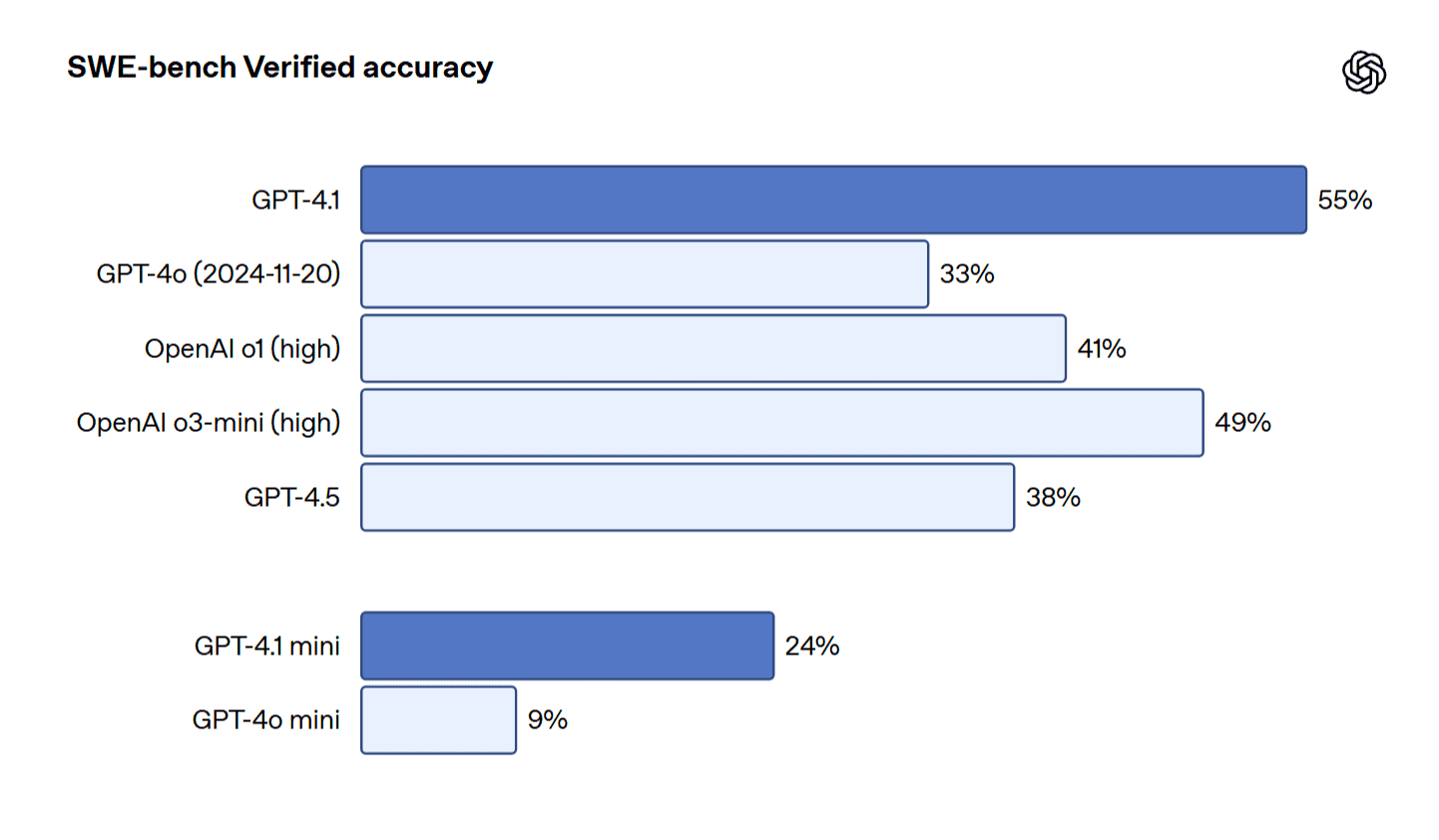
- SWE-bench Verified: 実世界のソフトウェアエンジニアリングスキルを測定するこのベンチマークにおいて、GPT-4.1は54.6%のスコアを記録。これはGPT-4o (2024-11-20版)の33.2%から21.4%(絶対ポイント差)、GPT-4.5の38.0%から26.6%の大幅な向上であり、コーディング支援AIとしての実力を示している。(注:OpenAIのインフラで実行できなかった23/500の問題を除外したスコア。これらを0点とすると52%となる)
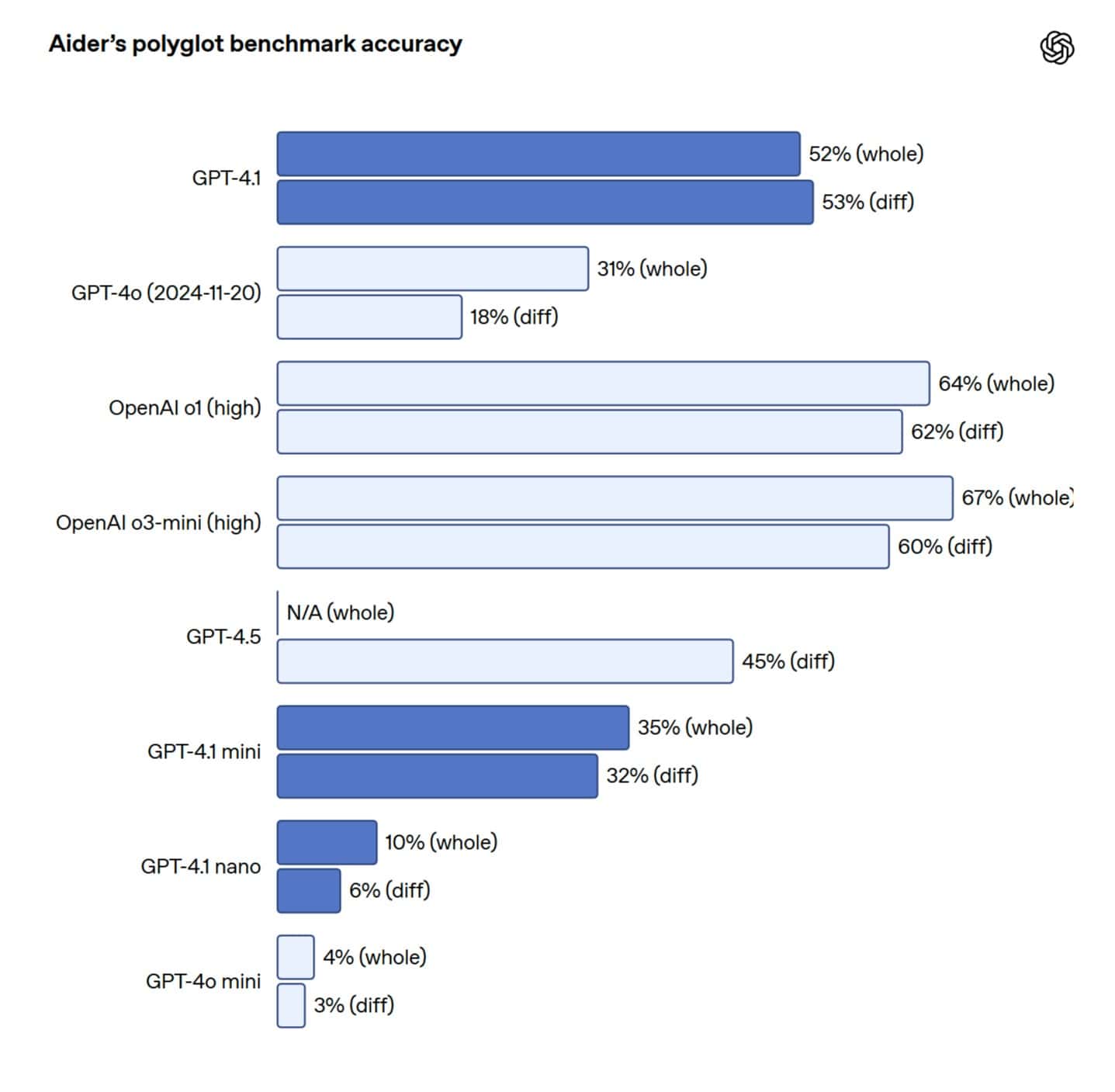
- コード差分(Diff)生成: 既存コードの一部だけを修正する「diffフォーマット」での出力信頼性が大幅に向上。Aiderの多言語diffベンチマークでは、GPT-4oの2倍以上のスコアを達成し、GPT-4.5をも8%上回った。これにより、開発者はファイル全体を書き換える必要がなくなり、コストと遅延を削減できる。なお、ファイル全体を書き換えるユースケースのために、GPT-4.1の最大出力トークン数は32,768トークン(GPT-4oの16,384から倍増)に拡張された。
- フロントエンド開発: Webアプリケーションの生成において、機能性とデザイン性の両面でGPT-4oを凌駕。OpenAIによる人間評価者の比較テストでは、80%のケースでGPT-4.1が生成したWebサイトの方が好まれたという。
- 不要な編集の削減: 内部評価では、コードに対する不要な編集がGPT-4oの9%からGPT-4.1では2%へと大幅に減少した。
これらの改善は、AIを活用した開発支援ツール(AI Agent)が、より現実に即した複雑なタスクを、より高い信頼性で実行できるようになったことを意味する。実際に、早期アクセスを行ったQodoのテストでは、GitHubのプルリクエストに対するコードレビュー生成において、GPT-4.1が他の主要モデル(具体名は挙げられていないが、文脈からClaude 3.7 Sonnet等が比較対象と推察される)に対し、55%のケースでより優れた提案を行ったと報告されている。特に、不必要な提案をしない「精度」と、必要な場合に徹底的な分析を行う「網羅性」のバランスに優れていたという。
ただし、SWE-bench Verifiedのスコアでは、GoogleのGemini 2.5 Pro (63.8%)やAnthropicのClaude 3.7 Sonnet (62.3%)には及ばない点も留意が必要である。とは言え、モデルの評価はベンチマークだけでなく、実タスクでの挙動やコストも含めて総合的に判断する必要があるだろう。
2. 命令追従性:意図を正確に汲み取る能力
AIモデルがユーザーの指示にいかに忠実に従えるかは、その実用性を左右する重要な要素である。GPT-4.1はこの点でも顕著な改善を見せた。
- MultiChallenge: 命令追従能力を測るこのベンチマークで、GPT-4.1は38.3%を記録し、GPT-4oの27.8%から10.5%向上した。
- IFEval: 検証可能な指示(文字数指定、特定用語の回避など)に対する追従性を測るIFEvalでは、GPT-4oの81.0%に対し、GPT-4.1は87.4%を達成。
- 内部評価: OpenAIは、開発者からのフィードバックに基づき、フォーマット追従、否定命令(すべきでないことの指示)、順序指定、内容要件、ランキング、過信抑制(知らない場合は「知らない」と言う)といった多様な側面から命令追従性を評価する内部ベンチマークを開発。特に困難なプロンプトにおいて、GPT-4.1はGPT-4oから大幅な改善を示したという。
この命令追従性の向上は、特に複数回のやり取り(マルチターン)が必要な対話型アプリケーションや、自律的にタスクを実行するAIエージェントの開発において、信頼性と安定性の向上に直結する。Blue Jの税務シナリオ分析では精度が53%向上、HexのSQLクエリ生成では成功率が約2倍になるなど、実用面での効果が報告されている。
ただし、OpenAIはGPT-4.1がGPT-4oよりも「文字通り」に指示を解釈する傾向があるため、より明確で具体的なプロンプトが必要になる場合があると指摘している。
3. 長文脈処理:100万トークン時代の到来とその課題
GPT-4.1ファミリーのもう一つの目玉は、最大100万トークンという広大なコンテキストウィンドウだ。これは約75万語に相当し、例えばReactのコードベース全体を8つ以上読み込める計算になる。これにより、大量の文書やコードベース全体を一度に処理するような、従来では考えられなかった応用が可能になる。
- 長文脈理解: OpenAIは、100万トークン全域にわたって情報を確実に参照できるようモデルを訓練したと主張。マルチモーダルな長文脈理解を測るVideo-MMEベンチマーク(字幕なし長尺動画カテゴリ)では、72.0%という新記録を達成し、GPT-4oの65.3%から6.7%向上した。
- Needle-in-a-Haystack (NIHA) テスト: 長大な文脈の中に隠された特定の情報(針)を見つけ出すNIHAテストでは、100万トークンまでの全てのコンテキスト長、全ての位置で、GPT-4.1は安定して正確に情報を抽出できたとしている。
- 新評価指標 OpenAI-MRCR: より現実的な課題として、文脈中に散りばめられた類似する複数の情報(複数の針)を区別し、特定のものを抽出する能力を測るOpenAI-MRCR (Multi-Round Coreference Resolution)を開発・公開。GPT-4.1は128kトークンまではGPT-4oを上回り、100万トークンまで強力な性能を維持するものの、精度は8,000トークンでの約84%から100万トークンでは50%まで低下することが示された。これは、超長文脈の処理が依然として困難な課題であることを示唆している。
- 新評価指標 Graphwalks: 文書間の参照関係を追うような、文脈内の複数箇所にわたる論理的な推論(マルチホップ推論)能力を評価するGraphwalksも公開。GPT-4.1は128kトークン未満の文脈長で61.7%の精度を達成し、GPT-4o (41.7%)を大きく上回った。しかし、128kトークンを超える文脈長では精度は19%まで低下し、ここでも長文脈における推論能力の限界が示された。
実用例としては、Thomson ReutersがリーガルAIアシスタントCoCounselでGPT-4.1をテストし、複数文書レビューの精度がGPT-4o比で17%向上したと報告。特に、文書間の複雑な関係性(矛盾する条項や依存関係など)の特定において高い信頼性を示したという。また、Carlyleは、PDFやExcelを含む長大な金融文書からのデータ抽出において、GPT-4.1が従来モデル比で50%優れた性能を発揮し、「干し草の中の針」探しや文書途中での情報欠落、複数文書をまたぐ推論といった課題を初めて克服できたと評価している。
4. 画像理解 (Vision):miniモデルの躍進
GPT-4.1ファミリーは画像理解能力も強化されており、特にGPT-4.1 miniの性能向上が著しい。
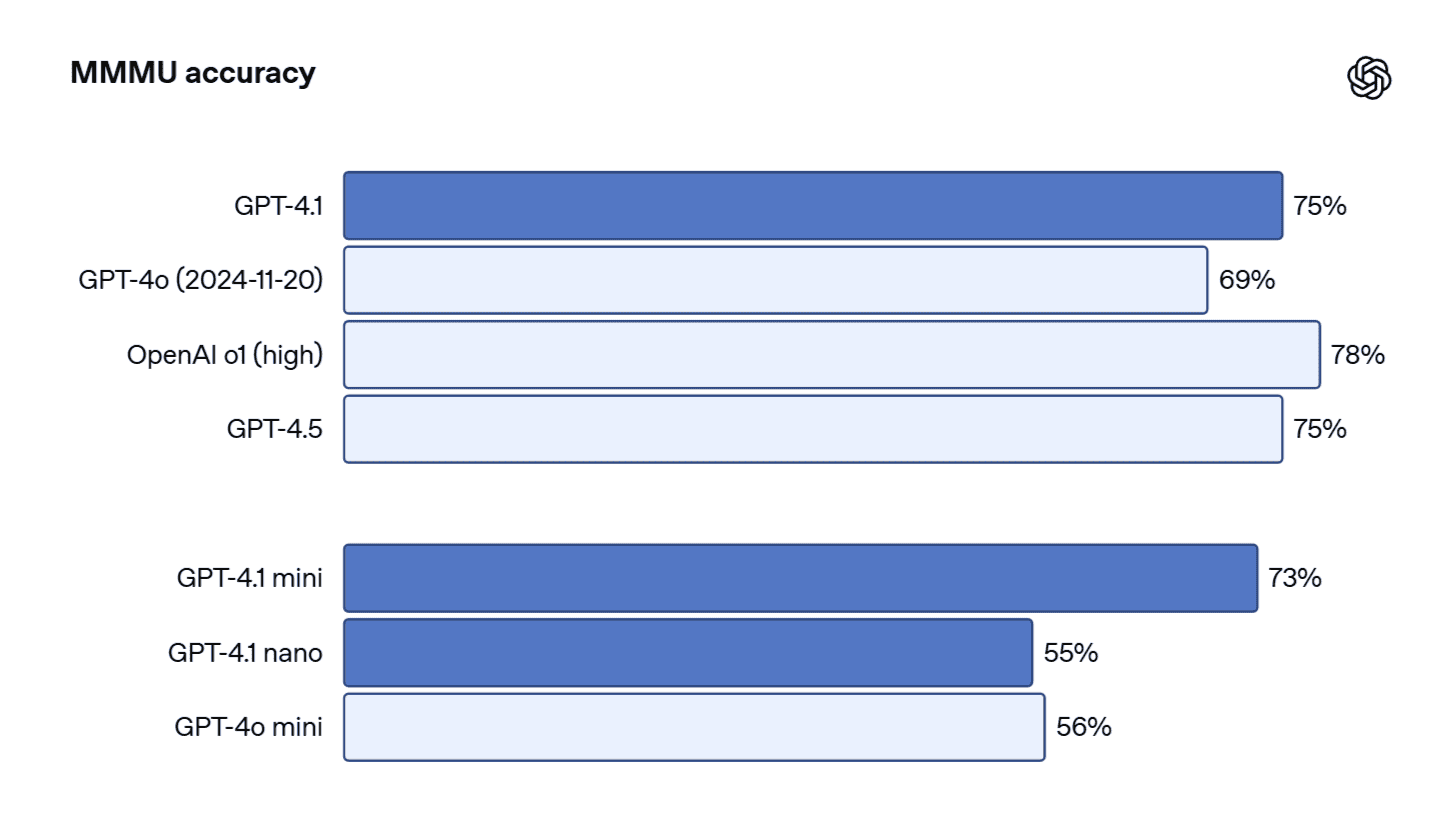
- MMMU: 図表や地図などを含む質問応答ベンチマークで、GPT-4.1 miniは73%を記録。これはGPT-4.5 (75.2%)に匹敵し、GPT-4o mini (56.3%)を大きく上回る。
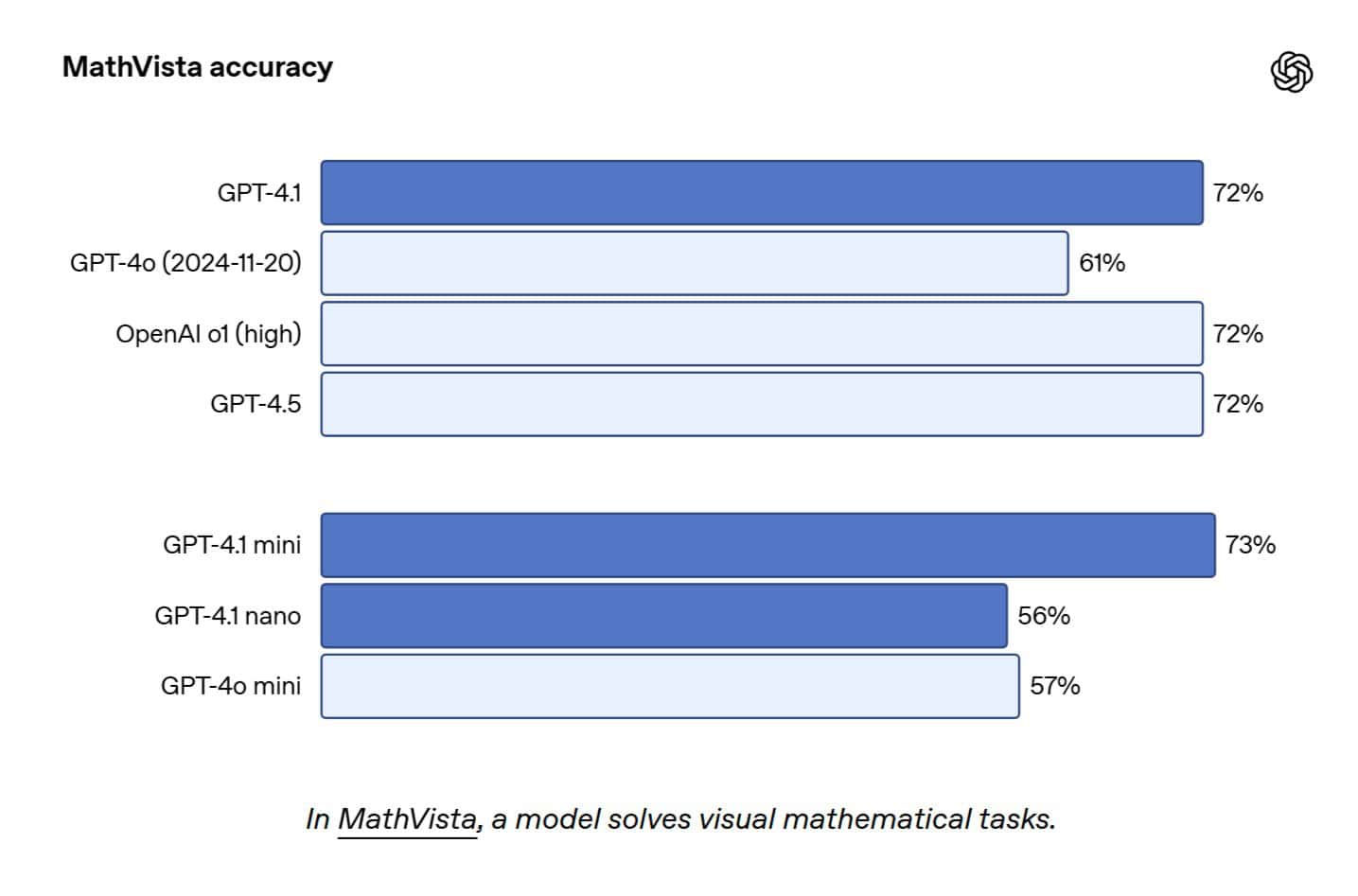
- MathVista: 視覚的な数学問題を解くベンチマークで、GPT-4.1とGPT-4.1 miniは共に57%に達し、GPT-4o mini (36.8%)を圧倒した。
5. 速度と応答性
性能だけでなく、応答速度も実用上重要である。
- GPT-4.1: 128,000トークンのコンテキスト処理時、最初のトークンが出力されるまでの時間(Time to First Token, TTFT)のp95レイテンシ(95パーセンタイル値)は約15秒。100万トークンでは最大30秒程度。
- GPT-4.1 mini / nano: より高速。特にnanoは、128,000トークンの入力を含むクエリで、通常5秒未満で最初のトークンを返す。
さらに、プロンプトキャッシュ(繰り返し使用されるコンテキスト部分をキャッシュする機能)を利用することで、遅延を削減し、コストも節約できる。
戦略的価格設定:AIコスト競争の新局面へ
OpenAIはGPT-4.1ファミリーで、性能向上だけでなく、価格面でも攻勢をかけている。
| モデル | 入力 (1Mトークンあたり) | キャッシュされた入力 (1Mトークンあたり) | 出力 (1Mトークンあたり) | ブレンド価格* (1Mトークンあたり) |
| gpt-4.1 | $2.00 | $0.50 | $8.00 | $1.84 |
| gpt-4.1-mini | $0.40 | $0.10 | $1.60 | $0.42 |
| gpt-4.1-nano | $0.10 | $0.025 | $0.40 | $0.12 |
*一般的な入出力比率とキャッシュ比率に基づく概算
注目すべき点をいくつか挙げる。
- GPT-4.1のコスト効率: 中央値程度のクエリにおいては、GPT-4oよりも26%安価になる。
- nanoの圧倒的な低価格: GPT-4.1 nanoは入力
0.10/Mtok、出力0.10/Mtok、出力0.10/Mtok、出力0.40/Mtokと、OpenAI史上最も安価なモデルとなった。分類や自動補完など、低遅延・低コストが求められるタスクに適している。 - プロンプトキャッシュ割引の強化: 繰り返し利用されるコンテキストに対する割引率が、従来の50%から75%へと大幅に引き上げられた。これは、会話型AIや反復的な処理を行うエージェントにおいて、コスト削減効果が大きい。
- Batch API割引: 非同期・バッチ処理用のBatch APIを利用する場合、さらに50%の価格割引が適用される。
- 長文脈の追加料金なし: 最大100万トークンまでのコンテキスト利用に追加料金は発生しない。
この価格設定は、競合他社、特にAnthropicのClaudeファミリーやGoogleのGeminiファミリーに対する明確な挑戦状と受け止められている。他社モデルとの比較は以下の通りだ:
- Anthropic Claude: Claude 3.7 Sonnet (入力
3.00,出力3.00, 出力3.00,出力15.00) と比較して、GPT-4.1は大幅に安価。HaikuやOpusを含めても、GPT-4.1ファミリーは価格競争力を持つ。 - Google Gemini: Gemini 2.5 Proはコンテキスト長によって価格が変わる段階的料金設定(≤200k: 入力
1.25,出力1.25, 出力1.25,出力10.00 / >200k: 入力2.50,出力2.50, 出力2.50,出力15.00)であり、複雑さが指摘されている。また、自動請求停止機能の欠如による「Denial-of-Wallet攻撃」のリスクも懸念されている。GPT-4.1のシンプルで予測可能な価格設定は、こうした懸念に対するアドバンテージとなりうる。 - xAI Grok: Grok-3 (入力
3.00,出力3.00, 出力3.00,出力15.00) と同等の価格帯だが、Grokは発表された100万トークンのコンテキスト長がAPIではまだ131kトークンに制限されている点が指摘されており、GPT-4.1は発表通りのスペックを提供している点で優位性がある。
OpenAIのこの価格戦略は、AIモデルの利用コストに対する開発者の懸念に応え、より広範な導入を促進することを狙っていると考えられる。特にスタートアップや中小規模のチームにとって、高性能なモデルをより手頃な価格で利用できる道が開かれたと言えるだろう。
開発者と企業へのインパクト:実用性とコスト効率の両立
GPT-4.1ファミリーの登場は、AIを活用する開発者や企業にとって、多くのメリットをもたらす可能性がある。
- 開発効率の向上: 向上したコーディング能力、特にコード差分生成やフロントエンド開発支援は、開発者の生産性を高めるだろう。Windsurfの報告では、GPT-4.1は不要なファイルの読み込みを40%削減し、不要なファイル変更を70%削減、冗長な出力を50%削減したとされ、開発サイクルの高速化に貢献している。
- アプリケーションの信頼性向上: 命令追従性の向上により、より複雑な指示にも安定して従うことができ、AIアプリケーションの信頼性が増す。これは、顧客サポート自動化やデータ分析など、精度が求められる業務への適用を後押しする。
- 新たなユースケースの開拓: 100万トークンという広大なコンテキストウィンドウは、従来は不可能だった大規模な文書分析、複数ソースからの情報統合、コードベース全体の理解などを可能にする。法務(Thomson Reuters)、金融(Carlyle)、研究開発など、専門分野での活用が期待される。
- コスト削減: 戦略的な価格設定とプロンプトキャッシュ割引により、AIの運用コストを削減できる可能性がある。特にnanoモデルは、コスト制約の厳しいアプリケーションにも高性能AIを導入する道を開く。
- AIエージェントの進化: 向上した命令追従性、長文脈理解、コーディング能力は、自律的にタスクを実行するAIエージェントの開発を加速させるだろう。ソフトウェアエンジニアリング、大規模文書からの洞察抽出、顧客対応など、より複雑なタスクを最小限の介入でこなせるエージェントの実現が近づいている。
一方で、OpenAI自身も認めるように、超長文脈利用時の精度低下や、より具体的なプロンプトの必要性など、留意すべき点も存在する。開発者はこれらの特性を理解し、適切なモデル選択とプロンプティング戦略を立てる必要がある。
OpenAIは、開発者がGPT-4.1を最大限に活用できるよう、更新されたプロンプティングガイドや、新しい評価データセット(OpenAI-MRCR, Graphwalks)を公開しており、コミュニティとの連携を重視する姿勢を示している。
GPT-4.1ファミリーは、単なる性能向上に留まらず、価格設定や開発者支援においても大きな一歩を踏み出した。これがAI市場全体の価格競争を激化させ、さらなる技術革新と普及を促す起爆剤となるか、今後の動向が注目される。

Sources
- OpenAI: Introducing GPT-4.1 in the API