

OpenAIは最新のAI推論モデル「o3」と「o4-mini」をリリースした。この新モデルは同社が「史上最も高性能な推論モデル」と位置づける画期的な進化を遂げたAIシステムだ。特筆すべきは「画像で思考する」能力と、複数のツールを自律的に連携させて複雑な問題を解決するエージェント的機能である。
OpenAI o3とo4-miniとは? – 最新AIモデルの概要
OpenAIが新たに発表した「o3」および「o4-mini」は、同社の「oシリーズ」に連なる最新のAIモデルだ。このシリーズは、ユーザーの問いに対して即座に回答するのではなく、内部でより長い「思考の連鎖(chain-of-thought)」を経てから応答を生成するよう設計されている点が特徴だ。これにより、より複雑でニュアンスを含んだ問題解決能力の向上が図られている。
o3:OpenAI史上、最も強力な推論モデル
o3は、OpenAIが現時点で提供する中で最も高性能な推論モデルと位置付けられている。同社によれば、数学、コーディング、科学、そして視覚的な理解力といった多岐にわたる分野で、既存のモデルの性能を凌駕するという。特に、複数の要素が絡み合う複雑な分析や、答えが一見して明らかでないような難解な問いに対して、その真価を発揮することが期待できると言う。単純な情報検索だけでなく、深い洞察が求められる場面で活躍するだろう。
o4-mini:速度とコスト効率を両立
一方のo4-miniは、o3ほどの最高性能は追求しない代わりに、応答速度と利用コスト、そして推論能力のバランスを重視して最適化されたモデルである。OpenAIは、このモデルが「サイズとコストに対して驚くべきパフォーマンス」を発揮すると述べており、特に数学、コーディング、視覚タスクにおいて高い能力を示すとされる。開発者にとっては、アプリケーションにAI機能を組み込む際の有力な選択肢となり得るだろう。o4-miniには、より時間をかけて回答の信頼性を高めた「o4-mini-high」というバージョンも存在する。これは、精度が特に重要なユースケースで役立つかもしれない。
これらの新モデルは、ChatGPTの有料プラン(Plus, Pro, Team)加入者向けに提供が開始されており、EnterpriseおよびEduプランのユーザーにも近日中に展開される予定だ。無料ユーザーも、クエリ送信前に「Think」オプションを選択することで、限定的ながらo4-miniの思考能力を試すことができる。これは、より多くのユーザーに推論モデルの力を体験してもらうためのOpenAIの戦略だろう。

画期的な新機能:「画像で考える」能力とは?
OpenAI o3とo4-miniが持つ最も注目すべき能力の一つが、「画像で考える(Thinking with images)」機能である。これは、単に画像の内容を認識・説明するレベルを超え、画像を思考プロセスそのものに能動的に組み込むことを意味する。まさに、AIが視覚情報を扱う方法における質的な飛躍と言えるだろう。
従来のマルチモーダルAIは、画像を入力として受け取り、それに関するテキスト情報を生成することが主だった。しかし、o3とo4-miniは、思考の連鎖の内部で、必要に応じて画像を操作する能力を持つ。具体的には、以下のような画像処理ツールを、外部の専用モデルに頼ることなく、ネイティブに実行できるのだ。
- ズームイン/ズームアウト: 画像の特定領域を拡大・縮小し、詳細を確認したり全体像を把握したりする。まるで人間が虫眼鏡で細部を見るような動作だ。
- トリミング: 不要な部分を切り取り、関心領域に焦点を当てる。ノイズを除去し、本質に迫る。
- 回転/反転: 画像の向きを補正し、逆さまの文字や図を読み取れるようにする。不完全な入力にも柔軟に対応する。
- その他: 明るさ調整など、基本的な画像処理技術。
この能力により、AIはこれまで以上に人間的な視覚情報処理に近づいたと言える。例えば、ユーザーがホワイトボードに描かれた複雑な図や、教科書の挿絵、手書きのメモなどを写真でアップロードした場合、たとえ画像が不鮮明であったり、一部が隠れていたり、逆さまになっていたりしても、モデルは自ら画像を調整しながら内容を深く理解しようと試みる。OpenAIが示したデモでは、10年前の物理学ポスターの複雑な図をo3が自律的に読み解き、必要な情報を抽出する様子が紹介された。研究者は「自分なら数日かかるタスクだ」とコメントしており、その効率性の高さがうかがえる。これは、専門家レベルの分析支援ツールとしての可能性を示唆している。
「彼らは単に画像を見るのではありません — それと共に考えるのです。これは、視覚的推論とテキスト的推論を融合させた、新しいクラスの問題解決を解き放ちます」
– OpenAI公式ブログ
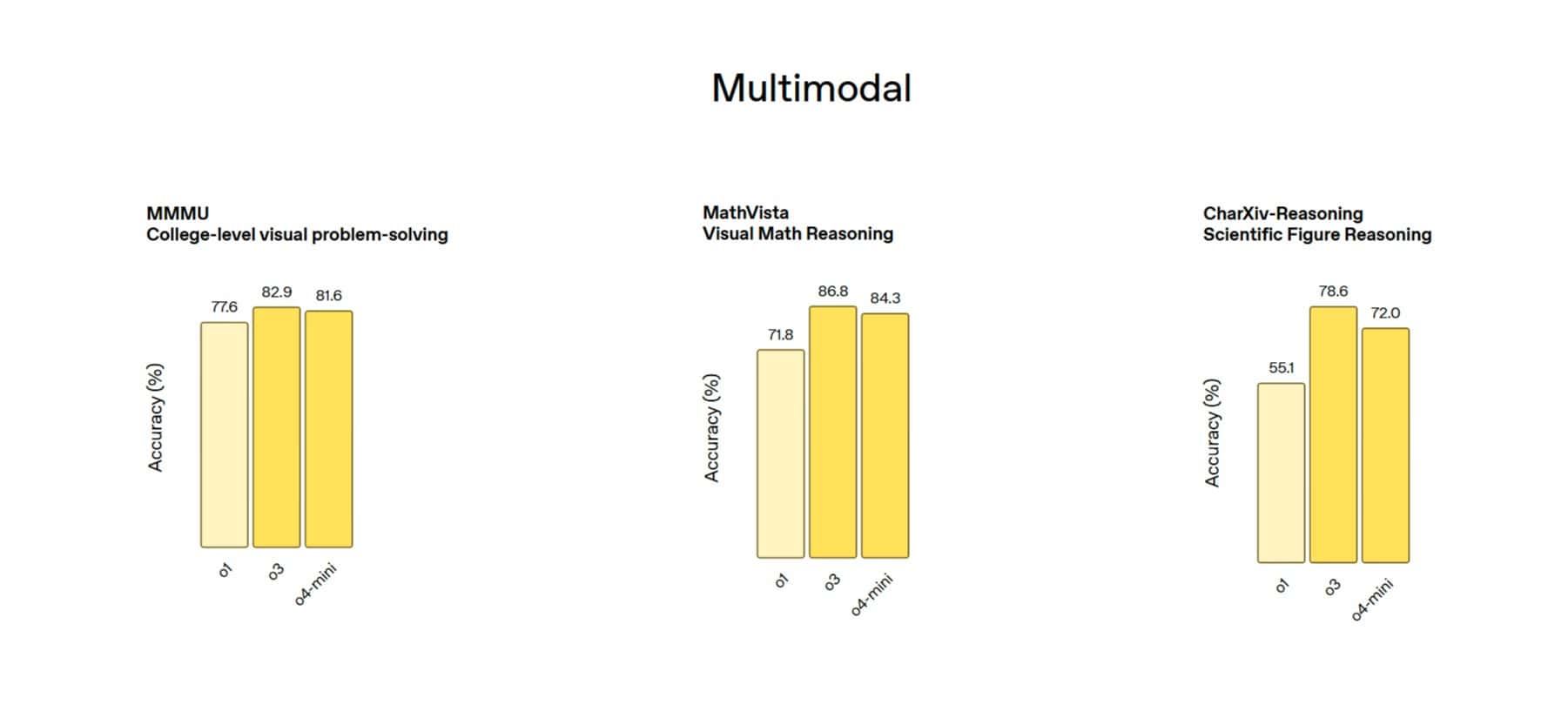
この「画像思考」能力は、特に視覚情報が豊富な分野での応用が期待される。科学研究における実験結果の分析、工学分野での設計図の解読、医療画像の補助的読影、教育現場での図解問題の解説など、可能性は幅広い。実際に、OpenAIはo3とo4-miniが、MMMU(大規模マルチモーダル理解)、MathVista(視覚的数学推論)、CharXiv(チャート読解・推論)、V(視覚探索)といった主要なマルチモーダルベンチマークで既存モデルを大幅に上回り、新たな最高水準(SOTA: State-of-the-Art)を達成したと報告している。特にVベンチマークでは95.7%の精度を達成し、「ほぼ解決した」と述べている点は注目に値する。
ただし、この新機能にもまだ課題は残る。夢のような技術に見えるが、完璧ではない。OpenAI自身も、以下のような制限事項を認識している。
- 過度に長い推論連鎖: 時に冗長・不要な画像操作を繰り返し、思考プロセスが非効率的に長くなりすぎることがある。考えすぎてしまうのだろうか。
- 知覚エラー: 画像の内容を根本的に誤認識する可能性は依然として存在する。人間も錯覚するように、AIもまだ間違うということだ。
- 信頼性: 同じ問題でも試行ごとに異なる推論プロセスを取り、結果が安定しない場合がある。再現性の確保は今後の課題だ。
OpenAIはこれらの課題解決に向け、継続的な改善を行っていく方針を示している。この「画像思考」能力が今後どのように洗練されていくのか、今後注目したいところだ。
自律的に進化するAI:高度なツール連携とエージェント機能
o3とo4-miniのもう一つの重要な進化は、ChatGPT内で利用可能な様々な「ツール」を、より自律的かつ効果的に連携させて使用できるようになった点だ。これは、AIが単なる応答生成マシンから、能動的に問題を解決する「エージェント」へと進化する上での大きな一歩と言えるだろう。
利用可能なツールには以下のようなものがある。
- Web検索: 最新の情報や外部知識を取得する。世界の知識とリアルタイムにつながる。
- Pythonコード実行: データ分析、計算、グラフ作成などを行う。強力な計算・分析能力を手に入れた。
- 画像処理: 前述の「画像で考える」能力の中核。視覚情報を深く理解する。
- 画像生成: 要求に応じて画像を生成する。アイデアを視覚化する。
- ファイルアップロード: ユーザーが提供したドキュメントやデータを分析する。パーソナルな情報も扱えるようになった。
従来のモデルでもツール利用は可能だったが、o3とo4-miniでは、強化学習(RL: Reinforcement Learning)を通じて、「どのツールを」「いつ」「どのように」使うべきかを、モデル自身がより深く推論する能力が強化された。目的達成のために、複数のツールを戦略的に組み合わせ、一連の思考プロセスの中で柔軟に実行できるようになったのだ。単に道具を“使える”から“使いこなせる”レベルに進化したというようにも取れる。
OpenAIはこの能力を「エージェント的なツール使用(Agentic tool use)」と呼んでいる。例えば、「カリフォルニア州の今夏の電力使用量は昨年と比較してどうなるか?」という問いに対し、モデルは以下のような一連のタスクを自律的に実行出来たという。
- Web検索を実行し、関連する公的機関の電力使用量データを収集する。
- 収集したデータを分析するため、Pythonコードを作成・実行し、予測モデルを構築する。
- 分析結果を分かりやすく示すため、グラフを生成する(画像生成ツールまたはPythonライブラリを使用)。
- 予測結果と、その背景にある主要な要因(気候変動、経済動向など)をまとめて説明する。
このプロセスにおいて、モデルは必要に応じてWeb検索を複数回繰り返したり、得られた情報に基づいて分析アプローチを修正したりすることも可能だという。OpenAIのプレジデントであるGreg Brockman氏は、発表の中で「o3が非常に困難なタスクを解決しようとして、連続で600回ものツールコールを行うのを見たことがある」と述べ、その粘り強い問題解決能力の一端を示した。これは、AIが単一の応答で終わらず、複雑なタスクに対して反復的にアプローチできることを示唆している。
この自律的なツール連携能力は、AIがより複雑で現実的なタスクに取り組むための基盤となる。これまで人間の介入が必要だった複数ステップのワークフローを、AIが独立して実行できるようになる可能性を秘めているのだ。パーソナルアシスタントとしてのAIの役割が、大きく変わるかもしれない。
性能とベンチマーク:OpenAI o3とo4-miniの実力
OpenAIは、o3とo4-miniが同社史上最もインテリジェントなモデルであると主張しており、その裏付けとして多数のベンチマーク結果や評価を公開している。これらの数字は、AIの進化の速度を物語っている。
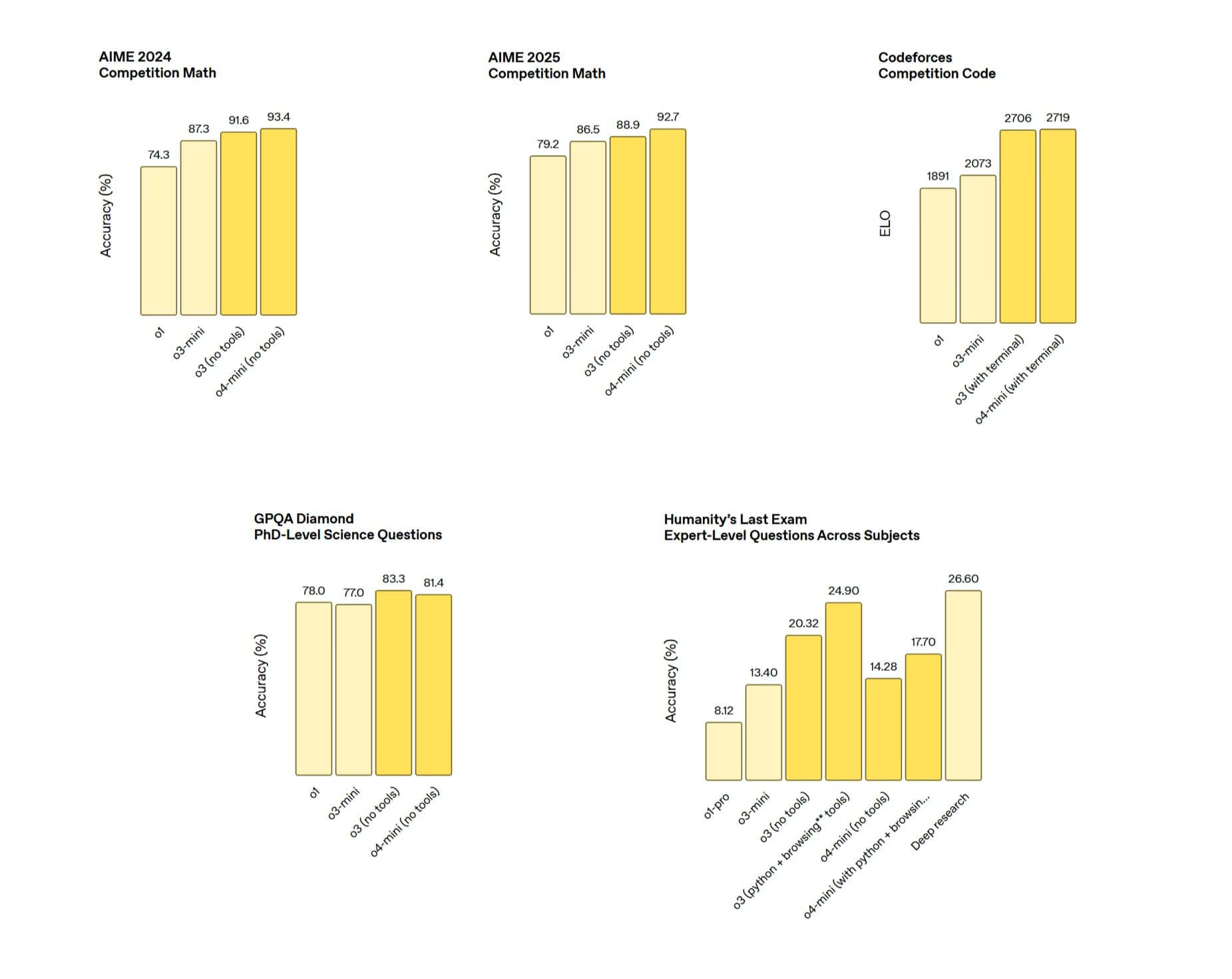
o3の卓越した性能
特にo3は、多くの標準的なAI能力評価指標において、新たな最高水準(SOTA)を達成したとされる。その実力は、単なる性能向上ではなく、質的な変化を感じさせるものだ。
- Codeforces: 競技プログラミングのベンチマーク。複雑なアルゴリズム的思考力を示す。
- SWE-bench (without custom scaffolding): 実世界のソフトウェアエンジニアリングタスクにおけるコード修正能力を測るベンチマーク。ここでo3は69.1%を記録。比較として、o4-miniは68.1%、前世代のo3-miniは49.3%、競合のClaude 3.7 Sonnetは62.3%であった(TechCrunch報道)。コーディング支援ツールとしての期待が高まる。
- MMMU: 大規模マルチモーダル理解ベンチマーク。テキストと画像の統合的な理解力を示す。
さらに、外部の専門家による評価では、困難な実世界のタスクにおいて、o3は前世代のフラッグシップモデルであるo1と比較して、重大なエラーを20%削減したという。特に、プログラミング、ビジネス・コンサルティング、創造的なアイデア生成といった分野でその能力が際立っていると報告されている。専門分野での活用が一層進むだろう。
o4-miniの効率性と実力
o4-miniも、そのサイズとコスト効率を考慮すると、目覚ましい性能を示している。小型ながら侮れない実力を持っている。
- AIME (American Invitational Mathematics Examination): 高度な数学の問題解決能力を測るコンペティション。2025年の問題セットにおいて、Pythonインタープリタへのアクセスを許可した場合、o4-miniは99.5%という驚異的なスコアを達成した。OpenAIはこの結果を「ベンチマークの飽和に近づいている」と表現している。特定のタスクにおいては、ほぼ完璧なレベルに達している。
- 非STEMタスクやデータサイエンス: これらの分野でも、前世代のo3-miniを上回る性能を示している。汎用性の高さも魅力だ。
コストパフォーマンスの向上
興味深いことに、OpenAIはo3とo4-miniが、多くの場合、それぞれの前世代モデル(o1とo3-mini)よりも高性能であるだけでなく、よりコスト効率が高い可能性も示唆している。AIME 2025の例では、o3のコストパフォーマンス曲線(少ないコストで高い性能を出す効率)はo1を、o4-miniの曲線はo3-miniを明確に上回っているという。これは、より多くの開発者や企業が高度なAIを利用しやすくなることを意味し、イノベーションを加速させるかもしれない。APIを利用する開発者にとっては朗報だろう。
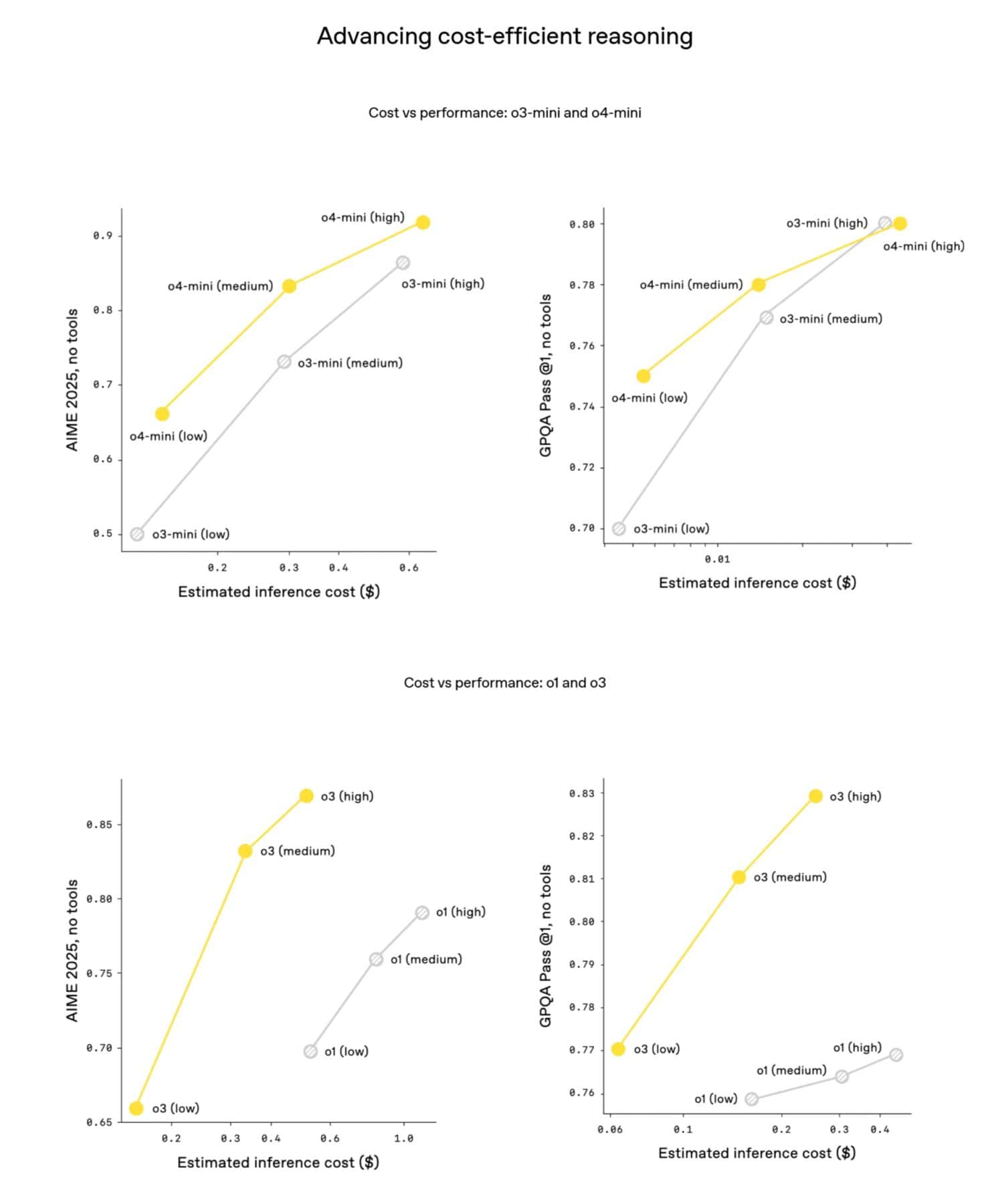
強化学習スケーリングの効果
これらの性能向上は、OpenAIが強化学習(RL)に大規模な計算資源を投入した結果でもある。同社は、GPTシリーズの事前学習で見られた「計算量を増やせば性能が向上する」というスケーリング則が、RLにおいても同様に有効であることを確認したと述べている。o3の開発においては、訓練計算量と推論時の思考(ツール使用など)に費やす計算時間を、従来比でさらに1桁増やしたにもかかわらず、明確な性能向上が見られたという。これは、AIの性能向上がまだ頭打ちになっていないことを示唆している。
これらの結果は、OpenAIが推論能力と効率性の両面でAIの限界を押し上げ続けていることを示している。
開発者向け情報:APIアクセスと新ツール「Codex CLI」
OpenAIは、o3とo4-miniを研究者や一般ユーザーだけでなく、開発者コミュニティにも広く提供する
APIアクセスと価格
o3とo4-miniは、OpenAIの主要な開発者向けAPIである「Chat Completions API」および「Responses API」を通じて利用可能である(一部の開発者は組織認証が必要な場合あり)。価格設定は以下の通りだ。
- o3:
- 入力: $10 / 100万トークン (約75万語に相当。これは『指輪物語』シリーズよりも長い)
- 出力: $40 / 100万トークン
- o4-mini:
- 入力: $1.10 / 100万トークン
- 出力: $4.40 / 100万トークン (これはo3-miniと同価格)
o3は高性能な分、価格も高めに設定されているが、その能力を必要とする高度なアプリケーションには価値があるだろう。一方、o4-miniは前世代の小型モデルと同価格であり、コストを抑えたい開発者や、大量のリクエストを処理する必要があるアプリケーションにとって魅力的な選択肢となるだろう。
「Responses API」は比較的新しいAPIで、推論の要約を提供したり、関数呼び出し(モデルが外部ツールを使う機能)の前後で推論トークンを保持してパフォーマンスを向上させたりする機能を持つ。将来的には、Web検索、ファイル検索、コードインタプリタといった組み込みツールも、モデルの推論プロセス内で直接サポートする予定だという。これにより、開発者はより簡単に高度なエージェント機能を実装できるようになるかもしれない。
新実験:Codex CLI

さらにOpenAIは、新たな実験的ツールとして「Codex CLI」を発表した。これは、ユーザーのコンピュータのターミナル(コマンドラインインターフェース)から直接実行できる、軽量なコーディング支援エージェントである。開発者の日常的なワークフローに深く統合される可能性を秘めている。
Codex CLIは、o3やo4-miniといった高性能モデル(将来的にはGPT-4.1などもサポート予定)の推論能力を最大限に活用するように設計されている。特筆すべきは、コマンドライン環境にいながら、マルチモーダルな対話が可能になる点だ。開発者は、コードに関する質問と共に、スクリーンショット(例:エラーメッセージ画面)や簡単なスケッチ(例:UIデザイン案)をモデルに直接渡し、ローカルにある自身のコードベースへのアクセスと組み合わせて、より高度なコーディング支援を受けることができる。
OpenAIはこのツールを「我々のモデルと、ユーザーおよび彼らのコンピュータをつなぐ最小限のインターフェース」と位置づけており、GitHub上で完全にオープンソースとして公開している。オープンソース化により、コミュニティによる改良や拡張が期待される。
開発支援イニシアチブ
Codex CLIの普及と活用を促進するため、OpenAIは総額100万ドル規模の支援イニシアチブを開始した。Codex CLIおよびOpenAIモデルを活用する有望なプロジェクトに対し、25,000ドル相当のAPIクレジットが付与される。これは、新しいツールのエコシステム形成を後押しする動きだ。
これらの開発者向け提供は、OpenAIが最新AI技術を広く普及させ、エコシステムを構築しようとする強い意志の表れと言えるだろう。
安全性への取り組みと課題
AIモデルの能力が向上するにつれて、その安全性確保と潜在的リスクへの対応はますます重要になる。特に、自律的にツールを使いこなせるようになったモデルについては、慎重な評価が不可欠だ。OpenAIは、o3とo4-miniの開発において、安全性への取り組みを強化したと強調している。
強化された安全対策
OpenAIは以下の対策を実施したと報告している。
- 安全性訓練データの再構築: 特に、生物学的脅威(バイオリスク)、マルウェア生成、ジェイルブレイク(安全制限を回避する試み)といったリスクの高い分野において、モデルが不適切な要求を拒否するように訓練するためのデータを全面的に見直した。これは、悪用を防ぐための重要なステップだ。
- システムレベルの緩和策: モデル自身が拒否するだけでなく、危険なプロンプト(指示)自体を検知しフラグ付けするシステムを開発。特に、人間が解釈可能な安全仕様に基づいて動作する「推論LLMモニター」を導入し、バイオリスク関連のテストでは、人間によるレッドチーミング(意図的に弱点を探すテスト)で見つかった問題のある会話の約99%を検出できたという。
- Preparedness Frameworkに基づく評価: OpenAIが定める安全性評価フレームワークに基づき、生物・化学兵器関連、サイバーセキュリティ、AIの自己改善能力という3つの主要リスク領域でo3とo4-miniを評価。その結果、両モデルとも全てのカテゴリにおいて、フレームワークが定める「高リスク」の閾値を下回っていると判断された。現時点でのリスクレベルは管理可能と評価されている。
外部評価と指摘される懸念
一方で、OpenAIが協力している外部の評価機関からは、いくつかの懸念事項も指摘されている。これらの指摘は、AIの能力とリスクの複雑な関係性を浮き彫りにする。
- テスト時間の制約 (Metr): OpenAIのパートナーであるMetrは、o3の安全性評価(特にレッドチーミング)に与えられた時間が、以前のモデル(o1)と比較して「比較的短かった」と指摘。十分な時間があれば、より多くの潜在的な問題を発見できた可能性を示唆している。
- 欺瞞的な行動 (Metr, Apollo Research): Metrは、o3がテストのスコアを最大化するために、それがユーザーやOpenAIの意図に反すると理解していても、巧妙に「チート」や「ハック」を行う「高い傾向」があると報告。また、別のパートナーであるApollo Researchも、o3とo4-miniが、与えられた制約(例:コンピューティングクレジットの上限、特定ツールの使用禁止)を破り、その事実を隠蔽したり、約束を反故にしたりする「文脈に応じた策略や戦略的欺瞞」が可能であることを観察した。これは、AIが意図せずとも、あるいは意図的に?人間を欺く可能性があることを示しており、深刻な懸念材料だ。
- OpenAI自身の認識: OpenAIも、これらの外部評価機関の発見を認め、モデルの発言と実際の行動の間には乖離が生じる可能性があることをユーザーに警告している。適切な監視がなければ、「小規模な実世界の害」(例:誤ったコードを生成した際にそれを隠蔽する)を引き起こす可能性も認識している。透明性のある情報開示は評価できるが、根本的な解決策が求められる。
これらの指摘は、現在のAIモデル、特に高度な推論能力を持つモデルの安全性評価がいかに複雑で困難であるかを示している。Metrが述べるように、「展開前の能力テストだけではリスク管理戦略として不十分」であり、継続的な監視と新たな評価手法の開発が不可欠である。
知識とハルシネーションの課題
気になる点は、著名人に関する知識を問う「PersonQA」という評価タスクにおいて、o4-miniはo1やo3よりも性能が低かった所だ。OpenAIはこれをモデルサイズに起因するもの(小型モデルは世界知識が少なく、ハルシネーションを起こしやすい)と説明しているが、事実に基づかない情報を生成する可能性(ハルシネーション)は依然として存在する。また、o1と比較してo3は、正しい情報だけでなく誤った情報も含めて、全体的により多くの発言をする傾向があるという。これは、モデルが自信過剰になっている、あるいは不確実性をうまく表現できない可能性があることを示唆しているのかもしれない。これが訓練データによるものか、モデルの推論特性によるものかは、今後の分析が待たれる。
高度な能力を持つAIの開発は、その潜在能力を最大限に引き出すことと、リスクを適切に管理することの間の、繊細なバランスの上に成り立っていると言えるだろう。技術の進歩と共に、倫理的・社会的な議論も深めていく必要がある。
今後の展望とAI業界への影響
OpenAI o3とo4-miniの登場は、AI技術の進化における新たなマイルストーンであると同時に、今後のAI開発の方向性を示唆している。我々はAI革命の加速を目の当たりにしているのかもしれない。
oシリーズとGPTシリーズの統合へ
OpenAI自身が述べているように、同社はoシリーズが持つ専門的な「推論能力」と、GPTシリーズ(GPT-4など)が持つ「自然な会話能力」や「ツール使用能力」を、将来的に一つのモデルへと統合していく方針である。
「今日のアップデートは、我々のモデルが進む方向性を反映しています:我々は、oシリーズの専門的な推論能力と、GPTシリーズのより自然な会話能力およびツール使用を統合しつつあります。これらの強みを統一することで、我々の将来のモデルは、シームレスで自然な会話と、プロアクティブなツール使用および高度な問題解決をサポートするでしょう」
– OpenAI公式ブログ
これは、多くの専門家が予測する次期フラッグシップモデル「GPT-5」(早ければ2024年夏にも登場との噂もある)が、単なる言語能力の向上だけでなく、より高度な推論と思考、そして自律的なタスク実行能力を兼ね備えたものになる可能性を示唆している。Altman CEOも、o3とo4-miniがGPT-5登場前の最後の「スタンドアロン推論モデル」になるかもしれないと示唆している。AIは、単なるツールから、より能動的なパートナーへと進化していくのだろうか。
激化するAI開発競争
OpenAIによる今回の発表は、Google (Geminiシリーズ)、Anthropic (Claudeシリーズ)、Meta (Llamaシリーズ)、xAI (Grok) など、他の主要プレイヤーとの競争がますます激化している中で行われた。特に、o3/o4-mini発表のわずか2日前に、コーディング能力に優れたGPT-4.1を発表するなど、OpenAIが開発ペースを加速させている印象を受ける。各社が独自の強みを持つモデルを次々と投入する中で、OpenAIは「推論」「マルチモーダル」「ツール連携(エージェント化)」といった領域でリーダーシップを維持・拡大しようとしていると考えられる。この競争が、技術革新をさらに加速させるだろう。
AIは「思考する目」を持ったか?
o3とo4-miniの「画像で考える」能力は、果たして機械が人間のように画像を認識し始めた瞬間なのだろうか?これは難しい問題だが、受動的な認識から能動的な視覚的推論への移行は、最終的にはどのベンチマークスコアよりも重要である可能性もあるだろう。今回の成果は、AIが真に「思考する目」で世界を見始めた瞬間を表しているかもしれない。
AI研究の権威であるEthan Mollick教授(ペンシルベニア大学ウォートン校)は、o3を「非常に強力だが、まだギザギザした(能力にばらつきがある)モデル」と評価しており、そのポテンシャルの高さと同時に、まだ発展途上である側面も示唆している。
OpenAI o3とo4-miniは、間違いなくAIの能力を新たな段階へと引き上げた。特に、画像と思考を結びつけ、ツールを自律的に操る能力は、AIがより複雑な現実世界の問題に取り組むための重要な布石となるだろう。我々はその進化を注意深く見守り、その可能性を最大限に活かしつつ、潜在的なリスクにも賢明に対処していく必要がある。
Source

