

AIスタートアップHyperWrite社が、開発したオープンソース大規模言語モデル「Reflection 70B」が、既存のオープンソースモデルのみならず、GPT-4oやClaude 3.5 Sonnetすらをも凌駕する性能を示し、AI業界に新たな衝撃を与えている。
既存の商用モデルすらも上回る性能を示すReflection 70B
Reflection 70Bは、MetaのLlama 3.1-70B Instructをベースに開発された最新の言語モデルだ。HyperWriteの共同創業者兼CEOであるMatt Shumer氏は、このモデルが「現在入手可能な最も優れたオープンソースモデル」であると主張している。
特筆すべきは、Reflection 70Bが複数の重要なベンチマークテストにおいて、OpenAIのGPT-4oやAnthropicのClaude 3.5 Sonnetといった最先端の商用モデルと互角以上の性能を発揮していることだ。具体的には、MMLU、MATH、IFEval、GSM8Kなどのテストで、GPT-4oを上回る結果を示したという。
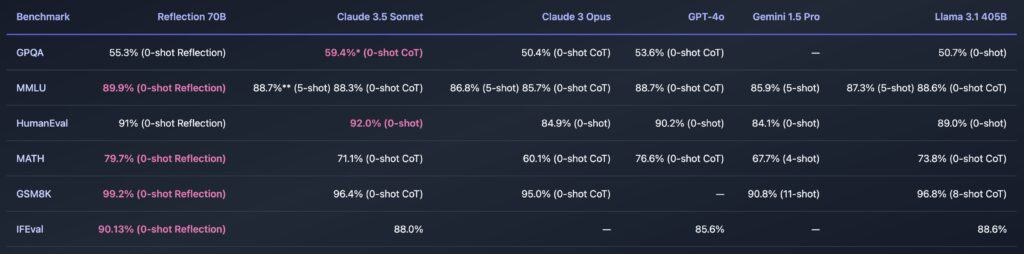
これらの成果は、AI開発における新たな可能性を示唆している。オープンソースモデルが商用モデルと肩を並べる、あるいはそれを超える性能を達成したことは、AI技術の民主化に向けた大きな一歩と言えるだろう。
さらに、Reflection 70Bの登場は、AIモデルの性能向上における新たなアプローチの有効性を示している。従来のモデルとは異なる独自の技術を採用することで、比較的小規模なスタートアップであっても、大手企業に匹敵する性能を持つAIモデルを開発できる可能性が示されたのだ。
Reflection 70Bの革新的技術「Reflection Tuning」
Reflection 70Bの卓越した性能の背景には、「Reflection Tuning」と呼ばれる革新的な技術がある。この手法は、モデルに自己修正能力を付与するもので、2段階のプロセスを経て実現されている。
まず、モデルは初期の回答を生成する。次に、その回答を「反省」し、潜在的な誤りや矛盾を特定した上で、修正版を作成する。この過程により、AIモデルが自身の出力を評価し、必要に応じて修正を加えることが可能になる。
Shumer氏は、この技術について次のように説明している。「数ヶ月前から、このアイデアについて考えていました。LLMは幻覚を見ますが、自己修正はできません。もしLLMに自身の間違いを認識し、修正する方法を教えたらどうなるだろう、と考えたんです」。
この「Reflection Tuning」技術により、Reflection 70Bは推論と誤り訂正のための特殊なトークンを導入している。これにより、ユーザーはより構造化された方法でモデルとやり取りすることが可能になる。推論過程は特殊なタグ内に出力され、モデルが誤りを検出した場合はリアルタイムで修正を行うことができる。
さらに、Reflection 70Bの開発には、Glaive AIが提供する合成データ生成技術が大きく貢献している。Glaive AIのプラットフォームは、特定のユースケースに最適化された高品質なデータセットを迅速に生成することができ、これによりReflection 70Bの学習プロセスが大幅に効率化された。
Shumer氏は、「GlaiveAIこそが、これほどうまくいった理由です。彼らが提供する合成データ生成のコントロール能力は驚異的です」と述べ、データ生成に要する時間が週単位から数時間に短縮されたことを明かしている。
これらの革新的技術の組み合わせにより、Reflection 70Bは高い精度と柔軟性を兼ね備えたAIモデルとなった。特に、複雑な推論や正確性が求められるタスクにおいて、その真価を発揮することが期待されている。
700億パラメータ・モデルのウェイトは現在Hugging Faceで利用可能で、Hyperbolic LabsのAPIも近日公開される予定だ。
また、Shumer氏は来週、より大規模なReflection 405Bモデルを、そのプロセスと結果に関する詳細なレポートとともに発表する予定だ。 Shumer氏は、Reflection 405BがSonnetやGPT-4oを大幅に上回ることを期待していると述べていると共に、Reflection 70Bが「おもちゃのように見える」レベルの、さらに高度な言語モデルを開発するアイデアがあると主張している。
Source






コメント