

スタンフォード大学の研究者、Lvmin Zhang氏とManeesh Agrawala氏が、動画生成AIの常識を覆す技術「FramePack」を発表した。この革新的なニューラルネットワーク構造は、わずか6GBのビデオメモリ(VRAM)しか搭載しない一般的なゲーミングGPUでも、高品質な長時間動画の生成を可能にするものだ。これまで高性能な専用ハードウェアが必要とされてきた動画生成AIを取り巻く状況が大きく変わるかもしれない。
FramePackとは? 長時間動画生成の「忘却」と「劣化」に挑む新技術

(上)RTX 3060(6GB VRAM)搭載のノートPCで画像から動画を生成した例。
FramePackは、動画生成、特に「次のフレーム(またはフレームの区間)」を予測するモデルのために設計されたニューラルネットワーク構造である。これまで動画生成AI、特に拡散モデル(Diffusion Model)をベースとした次フレーム予測モデルには、大きく二つの課題が存在した。
- 忘却 (Forgetting): 動画が長くなるにつれて、モデルが初期のフレームの内容や文脈を「忘れ」、時間的な一貫性を保てなくなる問題。
- ドリフト (Drifting) / 劣化: フレームを逐次生成していく過程で、微細なエラーが蓄積・増幅し、時間経過とともに画質が徐々に劣化していく問題(Exposure Biasとも呼ばれる)。
従来のモデルでは、これらの問題を同時に解決しようとすると、「記憶力を強化すればエラーも記憶・増幅しやすくなりドリフトが悪化する」「エラー伝播を抑えようとすると記憶力が低下し忘却が進む」というジレンマに直面していた。
FramePackは、この根本的な課題に対し、「フレーム圧縮によるコンテキスト長の固定化」と「アンチドリフトサンプリング」という二つの独創的なアプローチで解決を図る。
なぜ「革命」なのか? 低VRAM動作の秘密:フレーム圧縮
FramePackが低VRAMで動作する最大の理由は、入力フレームの情報を圧縮し、Transformerモデル(多くのAIモデルで採用される基盤技術)が処理する「コンテキスト長」を、動画の長さに関わらず一定の上限に収束させる点にある。
従来の次フレーム予測モデルでは、予測のためにより多くの過去フレームを参照しようとすると、それに比例して必要な計算リソース(特にVRAM)が増大した。動画が長くなればなるほど、計算負荷は爆発的に増加し、高性能なGPUが不可欠だった。
FramePackでは、予測対象のフレームに近いフレームほど重要度が高いと考え、重要度の低い(時間的に遠い)フレームほど圧縮率を高める「プログレッシブ圧縮」を適用する。これは、Transformerの「パッチ化(Patchify)」と呼ばれる画像や動画を小さな断片(トークン)に分割する処理のカーネルサイズを、フレームの重要度に応じて変化させることで実現される。
具体的には、最も重要な直近のフレーム(F₀)は圧縮せず多くのトークン(例:480pで1536トークン)で表現し、時間的に離れたフレーム(F₁, F₂, …)になるにつれて、より大きなカーネルサイズを適用してトークン数を指数関数的に減らしていく(例:F₅で32トークン)。
これにより、入力するフレーム数がどれだけ増えても、モデルが処理する総トークン数(総コンテキスト長)は一定の値に収束する。論文では主に圧縮率λ=2の場合(フレームごとにトークン数が半減)が議論されているが、この仕組みにより、計算負荷のボトルネックが動画の長さに依存しなくなり、VRAM使用量を劇的に削減できる。その結果、130億パラメータを持つような巨大なモデルでも、6GBのVRAMで60秒(30fpsで1800フレーム)の動画生成が可能になった。これは画像生成AIと同程度のVRAM要件であり、まさに革命的と言える。
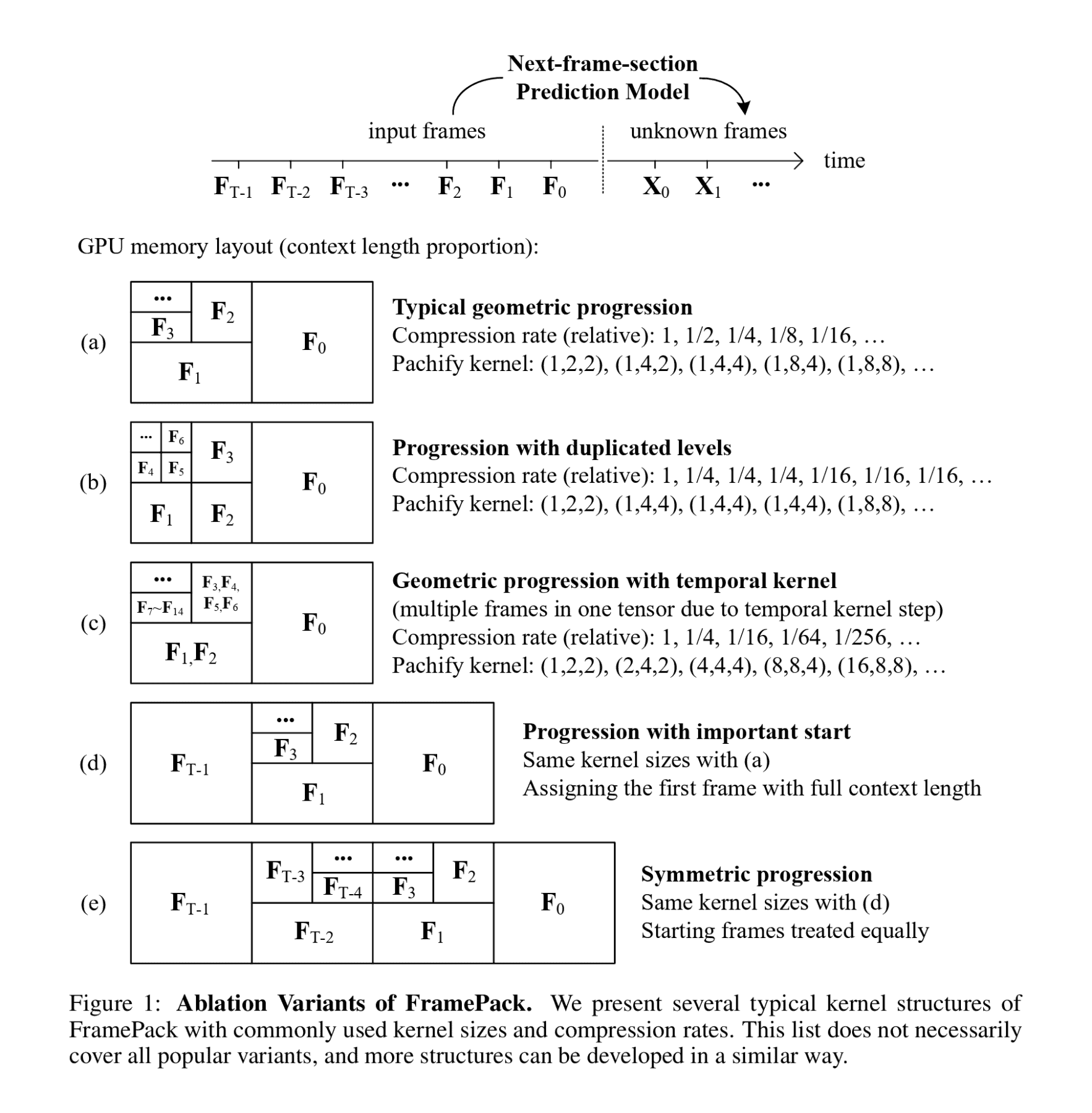
さらに、圧縮スケジュールは柔軟に変更可能で、例えば動画の最初のフレームを重要視したり(Figure 1(d))、最初と最後のフレームを同等に重要視したり(Figure 1(e))することもできる。これにより、画像から動画を生成するタスクなど、特定のフレームが重要な意味を持つ応用にも効果を発揮する。
画質劣化(ドリフト)を防ぐ新技術:アンチドリフトサンプリング
FramePackは、計算コストの問題だけでなく、画質劣化(ドリフト)の問題にも効果的な対策を導入している。研究チームは、ドリフトが主に過去のフレーム情報のみに依存して未来のフレームを予測する「因果的サンプリング」で発生することを発見した。
そこで提案されたのが、「アンチドリフトサンプリング」である。これは、未来のフレーム情報も考慮に入れる「双方向コンテキスト」を利用する手法だ。
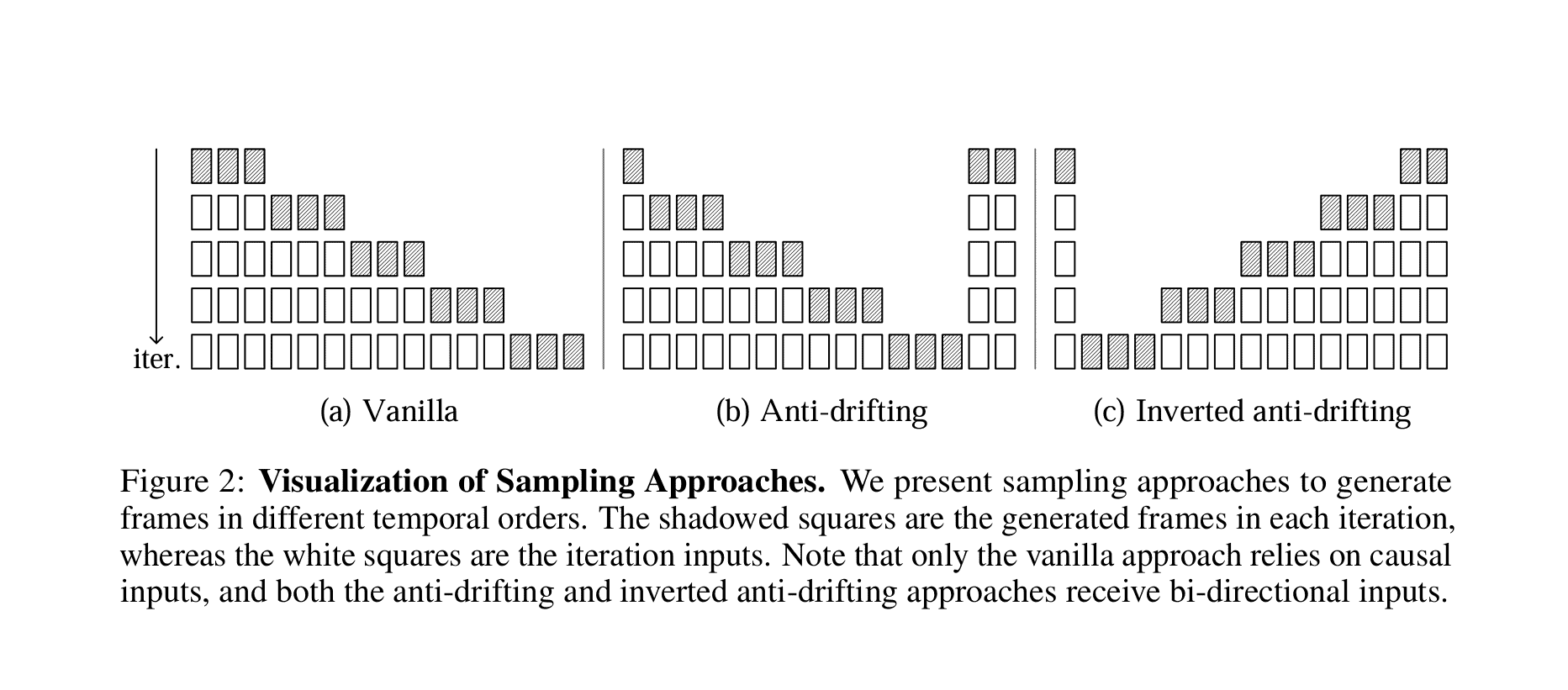
- アンチドリフトサンプリング(Figure 2(b)): 最初のステップで動画の開始部分と終了部分を同時に生成し、その後のステップで間のフレームを埋めていく。これにより、最終的な着地点(終了フレーム)が早期に定まるため、生成プロセス全体が安定し、ドリフトが抑制される。
- 反転アンチドリフトサンプリング(Figure 2(c)) : 特に画像から動画を生成する場合に有効な手法。ユーザーが提供した高品質な画像を最初のフレーム(基準点)とし、そこから時間を遡るように(逆順に)フレームを生成していく。各ステップで生成されるフレームは、常に高品質な基準フレームに近づくように最適化されるため、全体として高品質な動画が得られやすい。
実験結果では、この反転アンチドリフトサンプリングが、客観的な評価指標(特にドリフト関連指標)および人間による主観評価(ELOスコア)の両方で最も優れた結果を示している。
性能、要件、そして応用可能性
FramePackは、その効率性と品質により、幅広い応用が期待される。
- 性能: RTX 4090を使用した場合、最適化なしで1フレームあたり約2.5秒、teacacheなどの最適化を用いれば約1.5秒で生成可能と報告されている。RTX 30シリーズのラップトップGPUではその4~8倍程度の時間がかかるが、それでも生成中のフレームをリアルタイムで確認できる速度だ。
- モデル: HunyuanVideoやWanといった既存の動画拡散モデルをFramePack構造でファインチューニング(再学習)できる。130億パラメータモデルのファインチューニングが、画像拡散モデル並みのバッチサイズ64で、単一の8x A100/H100ノードで可能であり、個人や研究室レベルでの実験も現実的だ。
- 要件: 現時点では、NVIDIA RTX 30/40/50シリーズGPU(FP16およびBF16データ形式をサポート)が必要とされる。Linux OSもサポートされている。AMDやIntelのGPUへの対応は未確認。
- 使いやすさ: 開発者のLvmin Zhang氏は、画像をアップロードしプロンプトを入力するだけで動画生成を試せるGUI(グラフィカルユーザーインターフェース)も公開しており、技術者でなくとも利用しやすい環境を提供している。
- 応用: 個人クリエイターがYouTubeやTikTok向けの長尺動画を制作したり、企業が広告やプロモーションビデオのプロトタイプを迅速に作成したりするなど、これまで専門的な環境や高額なクラウドサービスが必要だった動画制作のハードルを大幅に下げる可能性がある。GIFやミーム動画のような気軽なコンテンツ作成にも活用できるだろう。
開発者と今後の展望
FramePackの開発者の一人であるLvmin Zhang氏は、画像生成AIの分野で絶大な影響力を持つ「ControlNet」の開発者としても知られる人物だ。ControlNetが画像生成の制御性を飛躍的に向上させたように、FramePackは動画生成のアクセシビリティと品質に大きなブレークスルーをもたらす可能性を秘めている。
わずか6GBのVRAMで、数分に及ぶ高画質な動画を生成できるようになったことは、動画生成AIが研究室の技術から、誰もが手軽に利用できるツールへと進化する大きな一歩である。今後、さらなる最適化や対応ハードウェアの拡大が進めば、映像制作のあり方そのものを変えていくかもしれない。
論文
参考文献

