

Sakana AIは17日、大規模言語モデル(LLM)に新たな適応能力を付与する画期的な手法「Transformer²」(トランスフォーマー・スクエアード)を発表した。この技術は、言語モデルが異なるタスクに効率的に適応できる仕組みを実現し、従来手法と比較して最大16%の性能向上を達成している。
革新的な「自己適応」メカニズムの実現
Transformer²を特徴付ける物に、与えられたタスクに応じて自らのパラメータを動的に調整できる「自己適応」メカニズムがある。このシステムの中核を担うのが、「Singular Value Fine-tuning(SVF)」と呼ばれる新しい手法だ。
従来の言語モデルは、新しいタスクに適応する際に大規模なパラメータの更新が必要だった。これは計算リソースを大量に消費するだけでなく、モデルが以前学習した能力を失う「破滅的忘却」のリスクも伴っていた。一方、近年普及したLoRAなどの手法は、既存のネットワークに小規模な拡張を追加することでこの問題に対処してきた。
しかし、Transformer²は全く異なるアプローチを採用している。SVFは、ネットワークの重み行列に対して直接的な変更を加えるのではなく、各ネットワーク接続の重要度を制御する「専門知識ベクトル」を学習する。具体的には、重み行列の特異ベクトルのスケーリングを調整することで、モデルの振る舞いを効率的に制御している。
この手法の革新性は、驚くべき効率性となって現れた。従来のLoRAが680万のパラメータを必要とした適応タスクを、SVFはわずか16万のパラメータで実現しているのだ。これは実に97%以上のパラメータ削減を意味する。さらに、このコンパクトな表現形式は、メモリ使用量と処理能力の大幅な節約をもたらしている。
また、SVFの特徴的な点として、過度な特化を防ぐ効果的な正則化機能が挙げられる。専門知識ベクトルは、モデルが特定のタスクに過度に特化することを防ぎながら、既存の知識を維持する巧妙なバランスを実現している。これにより、モデルは新しいタスクに適応しながらも、汎用的な能力を保持することができる。
さらに注目すべきは、これらの専門知識ベクトルが高い組み合わせ性を持つ点だ。異なるタスクで学習したベクトルを柔軟に組み合わせることで、未知のタスクにも効果的に対応できる。この特性は、モデルの適応能力をさらに拡張し、より複雑な問題解決を可能にしている。
Transformer²は、これらの技術的革新を通じて、言語モデルに真の意味での適応能力を付与することに成功している。これは、静的な事前学習モデルから、環境に応じて動的に進化する知的システムへの重要な一歩と言えるだろう。
3段階の適応戦略を実装
Transformer²は、タスクへの適応に3つの異なるアプローチを採用している:
- プロンプトベースの適応:特別な「適応プロンプト」を使用してタスクを分類し、適切な専門知識ベクトルを選択
- 分類器ベースの適応:専用の分類システムがタスクを識別し、最適な専門知識を選択
- Few-shot適応:複数の専門知識ベクトルを組み合わせて、新しいタスクに最適化された独自のベクトルを生成
特に注目すべきは、Few-shot適応の性能だ。複雑な数学問題を解く際、システムは数学的な専門知識だけでなく、プログラミングや論理的思考の能力も組み合わせて活用することが確認されている。
はい、実験結果の詳細について、より深く掘り下げて解説していきます。
実験で実証された優位性
Sakana AIの研究チームは、Transformer²の性能を複数の代表的な言語モデルを用いて徹底的に検証した。主な評価対象となったのは、LLAMA3-8B、MISTRAL-7B、そしてLLAMA3-70Bという異なる規模と特性を持つモデルだ。これらのモデルを用いて、数学的推論からプログラミング、論理的思考まで、幅広いタスクでの性能評価が実施された。
特に注目すべき成果が得られたのは、数学的問題解決能力の向上だ。GSM8K(小学校レベルの数学問題)のベンチマークでは、LLAMA3-8Bをベースとした実験で、オリジナルモデルの正答率75.89%に対し、Transformer²は79.15%という高い性能を示した。これは、従来のLoRAによる改善率77.18%を大きく上回る結果となっている。
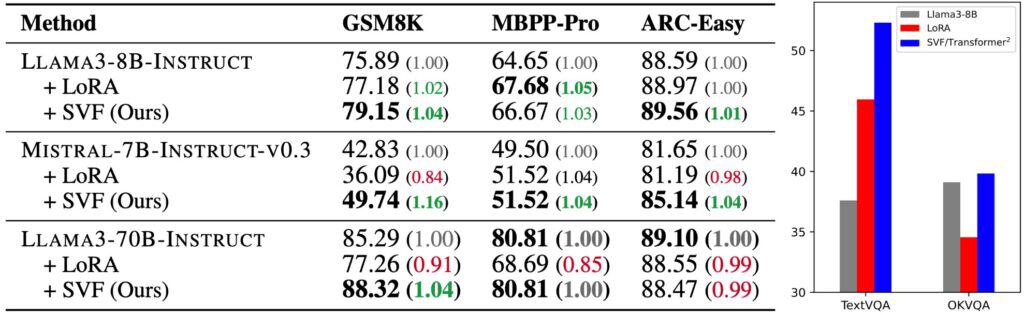
さらに印象的なのは、MISTRAL-7Bでの実験結果だ。数学タスクにおいて、ベースモデルの42.83%から49.74%まで、実に16%もの性能向上を達成した。この大幅な改善は、Transformer²の適応メカニズムが効果的に機能していることを示す強力な証拠と言えるだろう。
プログラミング能力の評価では、MBPP-Proベンチマークを使用した検証が行われた。ここでもTransformer²は安定した性能向上を示し、特にHumanEvalテストでは、完全に新規のプログラミングタスクに対しても効果的な適応能力を実証した。従来のLoRAが性能低下を招くケースがあった一方で、Transformer²は一貫して改善を示している点が特筆される。
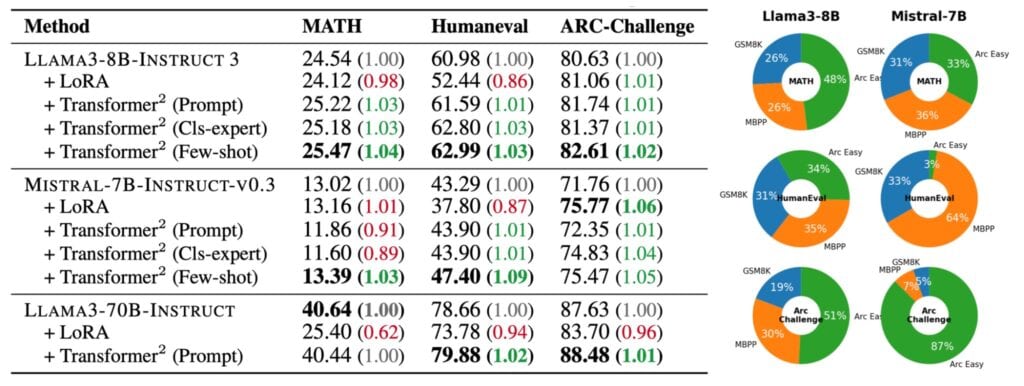
論理的推論能力の評価では、ARC-EasyとARC-Challengeという二つの異なる難易度のデータセットが使用された。特にARC-Challengeでの結果は興味深く、LLAMA3-8Bでのベーススコア80.63%から82.61%への向上を達成している。これは、モデルが複雑な推論タスクにも効果的に適応できることを示している。
視覚言語モデリング(VLM)分野での実験も実施され、TextVQAタスクにおいて39%という劇的な性能向上が確認された。この結果は、Transformer²の適応能力が言語タスクに限らず、マルチモーダルなタスクにも有効であることを示唆している。
特に注目に値するのは、Few-shot適応戦略の効果だ。この手法を用いた場合、完全に未知のタスクに対しても安定した性能向上が観察された。例えば、MATHデータセット(高度な数学問題)では、ベースモデルと比較して4%の精度向上を達成している。これは、モデルが異なる専門知識を効果的に組み合わせ、新しい問題に対応できることを示す物と言える。
モデル間の知識転移も実現
Transformer²の研究過程で、研究チームは極めて興味深い発見をしている。それは、あるモデルで学習した専門知識ベクトルを、アーキテクチャの異なる別のモデルに転送できるという予想外の可能性だ。この発見は、大規模言語モデルの知識共有に関する従来の常識を覆す可能性を秘めている。
具体的な実験では、LLAMA3-8Bで訓練された専門知識ベクトルをMISTRAL-7Bに転送する試みが行われた。その結果、HumanEvalタスクでは43.29%から46.75%へ、ARC-Challengeタスクでは71.76%から75.64%への性能向上が確認された。これは、モデル間で知識の効果的な転移が可能であることを実証する重要な成果となっている。
しかし、この知識転移のメカニズムには興味深い特徴がある。研究チームは、専門知識ベクトルの要素の順序が極めて重要であることを発見した。ベクトルの要素をランダムに並び替えると、性能が大きく低下することが確認されているのだ。例えば、ARC-Challengeタスクでは、要素をランダムに並び替えた場合、性能が70.82%まで低下している。これは、専門知識ベクトルが単なる数値の集合ではなく、特定の構造的な意味を持っていることを示唆している。
さらに注目すべきは、異なるモデルの専門知識ベクトルを組み合わせることで、単一モデルの専門知識よりも優れた性能を達成できる場合があるという発見だ。Few-shot適応を用いて複数モデルの専門知識を組み合わせることで、ARC-Challengeタスクでは75.64%という、単一モデルの専門知識を使用した場合を上回る性能が得られている。
ただし、この知識転移の成功には重要な前提条件がある。現時点での実験は、比較的類似したアーキテクチャを持つモデル間でのみ検証されている。研究チームは、これが知識転移が成功した要因の一つである可能性を指摘している。異なるアーキテクチャや、大きく規模の異なるモデル間での知識転移の可能性については、今後の研究課題として残されている。
この発見は、言語モデルの開発における新たな可能性を示唆している。将来的には、大規模モデルで獲得した専門的なスキルを、より小規模で効率的なモデルに転送することが可能になるかもしれない。これは、高度な AI 能力の民主化につながる重要な一歩となる可能性を秘めている。同時に、環境負荷の観点からも、大規模モデルの学習で得られた知識を効率的に再利用できることは、持続可能な AI 開発への貢献となるだろう。
しかし、この技術の実用化にはまだいくつかの課題が残されている。特に、より多様なモデルアーキテクチャ間での互換性の検証や、転移された知識の長期的な安定性の評価など、さらなる研究が必要とされている。これらの課題を克服することで、より柔軟で効率的な AI システムの開発が可能になると期待されている。
論文
- arXiv: Transformer2 : Self-adaptive LLMs
参考文献
- Sakana AI: Transformer²: Self-Adaptive LLMs
Meta Description
Sakana AIが発表した自己適応型言語モデル技術「Transformer²」。効率的なパラメータ調整で従来比最大16%の性能向上を実現。異なるタスクへの適応能力を大幅に向上させる革新的手法として注目を集める。










コメント