
NVIDIAがIEDM 2024カンファレンスにおいて、シリコンフォトニクスと3D積層技術を組み合わせた次世代AIアクセラレータの構想を発表した (via Ian Cutress) 。この革新的なアプローチは、増大するAIコンピューティング需要に応えるべく、従来の半導体パッケージング技術の限界を超えることを目指している。
革新的なアーキテクチャの詳細
NVIDIAが提案する次世代AIアクセラレータの中核となるのが、シリコンフォトニクス(SiPh)技術の採用である。従来の半導体チップ間の通信は銅配線による電気信号で行われてきたが、この新しいアーキテクチャでは光を用いた相互接続を実現する。光による通信は電気信号と比較して、より高速でエネルギー損失が少ないという特徴を持つ。
具体的な実装としては、1つのGPUタイルに対して3本、システム全体で計12本のSiPh接続を配置する設計となっている。これらの光学的な相互接続は、チップ内の異なるコンポーネント間(intrachip)の通信と、複数のチップ間(interchip)の通信の両方に活用される。この接続方式により、データの転送速度と電力効率を大幅に向上させることが可能となる。
さらに注目すべきは、「GPUティア」と呼ばれる革新的な3次元積層構造の採用だ。この構造では、4つのGPUタイルを垂直方向に積み重ねることで、チップ面積あたりの演算密度を飛躍的に高めている。各GPUタイルは垂直配向で配置され、これによりインターコネクトの遅延を最小限に抑えることが可能となる。加えて、この構造は効率的な電力制御(パワーゲーティング)の実装も容易にする。
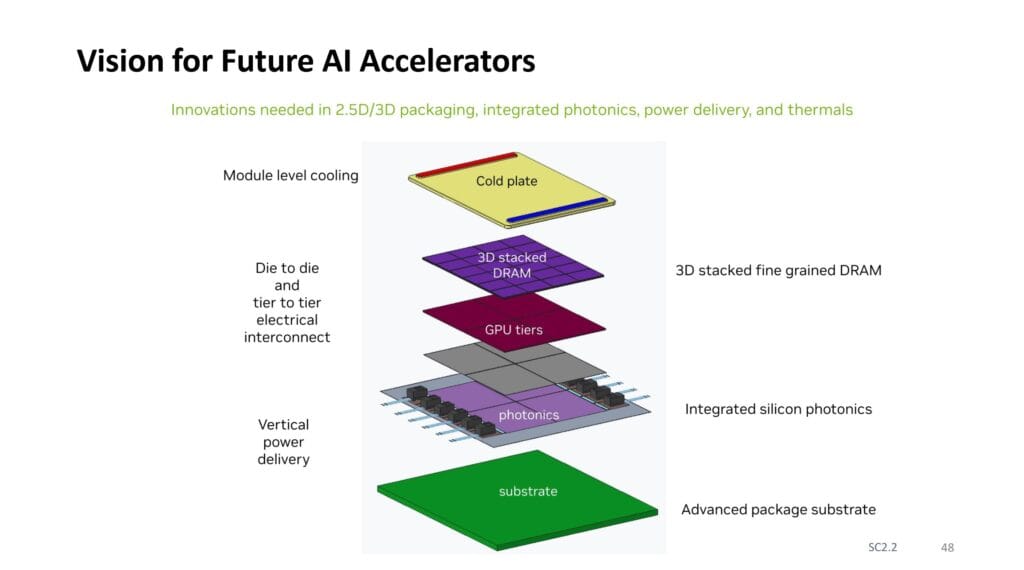
DRAMの実装にも大きな革新が見られる。各GPUタイルの上部には6枚のDRAMチップが3次元積層される設計となっており、これはAMDが採用している3D V-Cache技術を大規模に発展させたものと見ることができる。GPUとDRAMを密接に配置することで、メモリアクセスの遅延を最小限に抑え、帯域幅を大幅に向上させることが可能となる。

このアーキテクチャ設計の真価は、単なる個別技術の組み合わせを超えた、システム全体としての統合的な最適化にある。シリコンフォトニクスによる高速な通信経路、GPUの3次元積層による高密度化、そしてDRAMの密接な統合により、次世代のAIワークロードが要求する膨大な演算処理とデータ転送を、効率的に処理することが可能となるのである。
実現に向けた課題
しかし、この革新的な設計の実現には複数の技術的ハードルが存在する。最も重要な課題の一つは、シリコンフォトニクス技術の量産化だ。NVIDIAの構想を実現するには、月間100万個以上のSiPh接続を製造する能力が必要となる。
また、垂直積層構造による熱管理の問題も深刻だ。NVIDIAは専用のコールドプレートを使用したモジュールレベルの冷却など、革新的な冷却ソリューションの開発を進めているが、「ロジック上にロジック、その上にDRAM」という積層構造の実現には、材料科学の更なる進歩が不可欠とされている。
Xenospectrum’s Take
この野心的な構想は、半導体業界に新たなパラダイムシフトをもたらす可能性を秘めている。特筆すべきは、NVIDIAがLightmatterへの投資を通じてフォトニックパッケージの開発を既に進めているという点だ。とはいえ、Ian Cutress氏が指摘するように、実用化までには2028年から2030年程度を要するだろう。
シリコンフォトニクスという「若い技術」に全面的に依存する戦略には、いささか無謀さも感じられる。しかし、増大するAI需要に応えるには、こうした大胆な技術的賭けも必要なのかもしれない。業界の闇雲な熱狂に水を差すようで恐縮だが、実用化までの道のりは、発表された構想以上に険しいものとなるだろう。
Sources








コメント