

Metaの研究者らは、AI言語モデルの学習中に複数のトークンを予測することで、性能、一貫性、推論能力が向上することを実証した。これは、大規模言語モデルの“未来”の一つの形を提示する物になるかも知れない。
従来の大規模言語モデルとは一線を画する“マルチトークン予測”
OpenAIのGPT-4のような大規模言語モデル(LLM)は通常、“次のトークン予測”を使って学習される。つまり、現在のAIシステムは文中の“次の単語だけを予測する”ように学習するのだ。だがMeta AI、CERMICS (Ecole des Ponts ParisTech)、LISN (Université Paris-Saclay)の研究者らは、これを超え、“マルチトークン予測”と彼らが呼ぶ、一度に複数の単語を予測することを提案している。
具体的には、マルチトークン予測モデルは、共有モデルコンポーネント(トランク)と多数の独立した出力ヘッドを使用することにより、学習テキストの各ポイントで次の単語を並行して予測する。
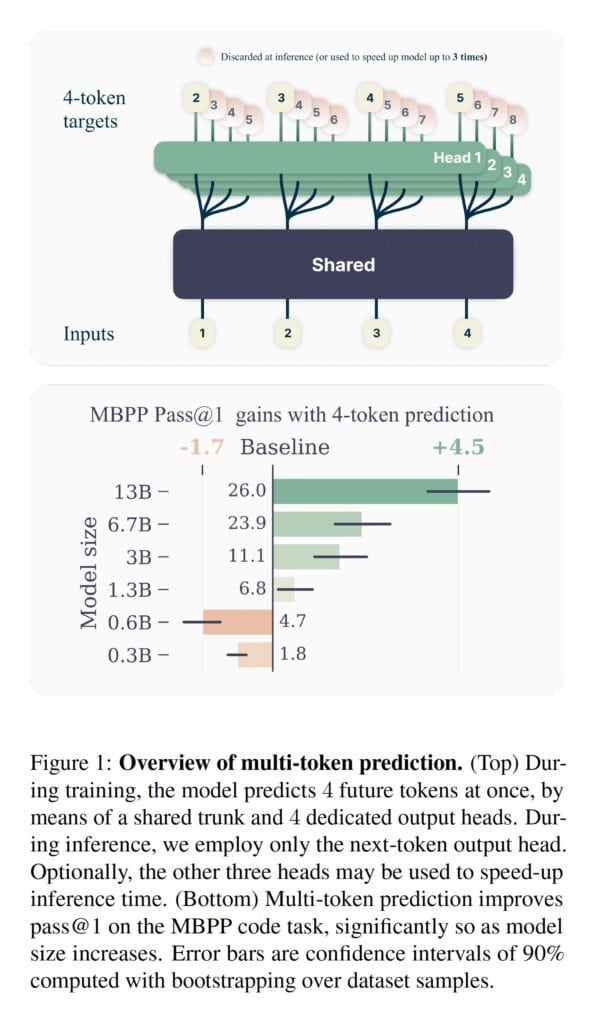
メモリ要件を低く保つため、出力ヘッドの計算は順次実行され、各ステップの後に中間結果が削除される。こうすることで、予測語数が増えてもメモリ要件が増加することはない。
実験によると、マルチトークン予測モデルの利点はモデルのサイズが大きくなるほど大きくなる。130億個のパラメータを持つモデルは、同等の次のトークンだけを予測するモデルと比較して、HumanEvalデータセットでは12%、MBPPデータセットでは17%多くプログラミングタスクを解決した。
マルチトークン予測モデルは実行速度の面でも優れており、追加された予測ヘッドを利用する投機的デコードにより、モデルの実行速度は最大3倍速くなるという。
では、なぜマルチトークン予測はこれほどうまくいくのだろうか?研究者らは、従来の次のトークンだけを予測するモデルは、即時予測に集中しすぎるのに対し、マルチトークン予測モデルはより長期的な依存関係も考慮するのではないかと考えている。
さらに、マルチトークン予測では、「選択ポイント」(テキストの残りの部分に大きな影響を与える決定)を表すトークンにより高い重みを暗黙的に割り当てる。学習中にこれらの重要な決定ポイントを強化することで、モデルはより良い選択をするように学習し、より首尾一貫した有用なテキスト生成につながる。さらに、情報理論的な分析によると、マルチトークン予測は、モデルが後続のテキストに関連性の高いトークンの予測に集中することを促し、より長期的な依存関係をより効果的に捉える可能性がある。
この結果は有望ではあるが、研究者たちはまだ改善の余地があることを認めている。今後の課題としては、タスクとデータ分布に基づいて、n個(予測する未来のトークンの数)の最適値を自動的に決定することである。さらに、語彙のサイズを調整し、別の補助的な予測損失を探索することで、圧縮されたシーケンス長と計算効率のトレードオフをさらに改善できる可能性も示唆している。
研究によれば、脳は言語を理解する際、現在のAIモデルよりもさらに先のことを考えているという。単に次の単語を予測するのではなく、一度に複数の単語を予測するのだ。さらに、より広範で抽象的な予測をするために、構文情報と一緒に意味情報も使用する。
研究チームは、言語モデルを訓練する際に、単なる次トークン予測だけでなく、新しい補助タスクに関心を持たせ、その性能、一貫性、推論能力を向上させたいと考えている。
論文
研究の要旨
GPTやLlamaのような大規模な言語モデルは、次のトークン予測損失で学習される。本研究では、一度に複数の未来のトークンを予測するように言語モデルを訓練することで、サンプルの効率が高くなることを提案する。より具体的には、訓練コーパスの各位置で、共有モデルトランクの上で動作するn個の独立した出力ヘッドを用いて、次のn個のトークンを予測するようモデルに求める。多トークンの予測を補助的な訓練タスクとみなすことで、コードモデルと自然言語モデルの両方において、訓練時間のオーバーヘッドなしに、ダウンストリーム能力の向上を測定する。この方法は、モデルサイズが大きくなるほど有用性が増し、複数エポックの訓練でもその魅力を維持する。特にコーディングのような生成的ベンチマークで顕著であり、我々のモデルは常に強力なベースラインを数%ポイント上回る。我々の13Bパラメータモデルは、HumanEvalでは同等のnext-tokenモデルよりも12%多く、MBPPでは17%多く問題を解く。小規模なアルゴリズムタスクの実験では、マルチトークン予測は帰納ヘッドとアルゴリズム推論能力の開発に有利であることが実証された。さらなる利点として、4トークン予測で学習したモデルは、バッチサイズが大きい場合でも推論が最大3倍高速になる。








コメント