テキストプロンプトから音楽を生成するツールはこれまでにもいくつか登場しているが、Google DeepMindが披露した「Video-to-Audio (V2A)」技術は、それに加えて、マルチモーダルAIモデルが動画の内容を読み取り、サウンドトラックやセリフ、効果音までをも生成することが可能だという。
ビデオ生成モデルの出力に命を吹き込む
Google DeepmindのV2A技術は、ビデオのピクセルと自然言語の指示を組み合わせて、無声ビデオに対して詳細なオーディオトラックを生成するものだ。Google DeepMindによれば、ユーザーはこのツールを使って、“ドラマのスコア、リアルな効果音、または動画のキャラクターやトーンにマッチしたセリフ”を含むシーンを作成することができると言う。
GoogleのVeoやOpenAIのSora、KLING、Gen 3など、ビデオ生成モデルは動画を生成することは出来たが、それは映像のみであり、音声は別途用意する必要があった。Googleは、今回のV2Aを、それらビデオ生成モデルと組み合わせて使用することで、劇的な音楽、リアルな音響効果、キャラクターやビデオの雰囲気に合わせたセリフを追加することができるとしている。生成した動画だけではなく、アーカイブ映像や無声映画のような伝統的な映像に音を追加するためにも使用できる。
また、AIに動画の解析を全て任せるだけでは結果が自分の望んだとおりに得られないこともあるだろう。そうした場合のために、テキストプロンプトによって望ましい音を再現したり、不要な音を削除したり、変更する様な指示を与えることも可能だ。
このDeepMindのV2AモデルはDiffusionベースで構築されており、チームによればビデオとオーディオを同期させるために最も現実的で説得力のある結果を提供するとされている。
V2Aシステムはまず、ビデオ入力を圧縮表現にエンコードする。その後、Diffusionモデルが視覚的入力とテキストプロンプトに導かれながら、ランダムなノイズから徐々にオーディオを精錬していく。最後に、オーディオ出力がデコードされ、オーディオ波形に変換され、ビデオデータと組み合わされる。
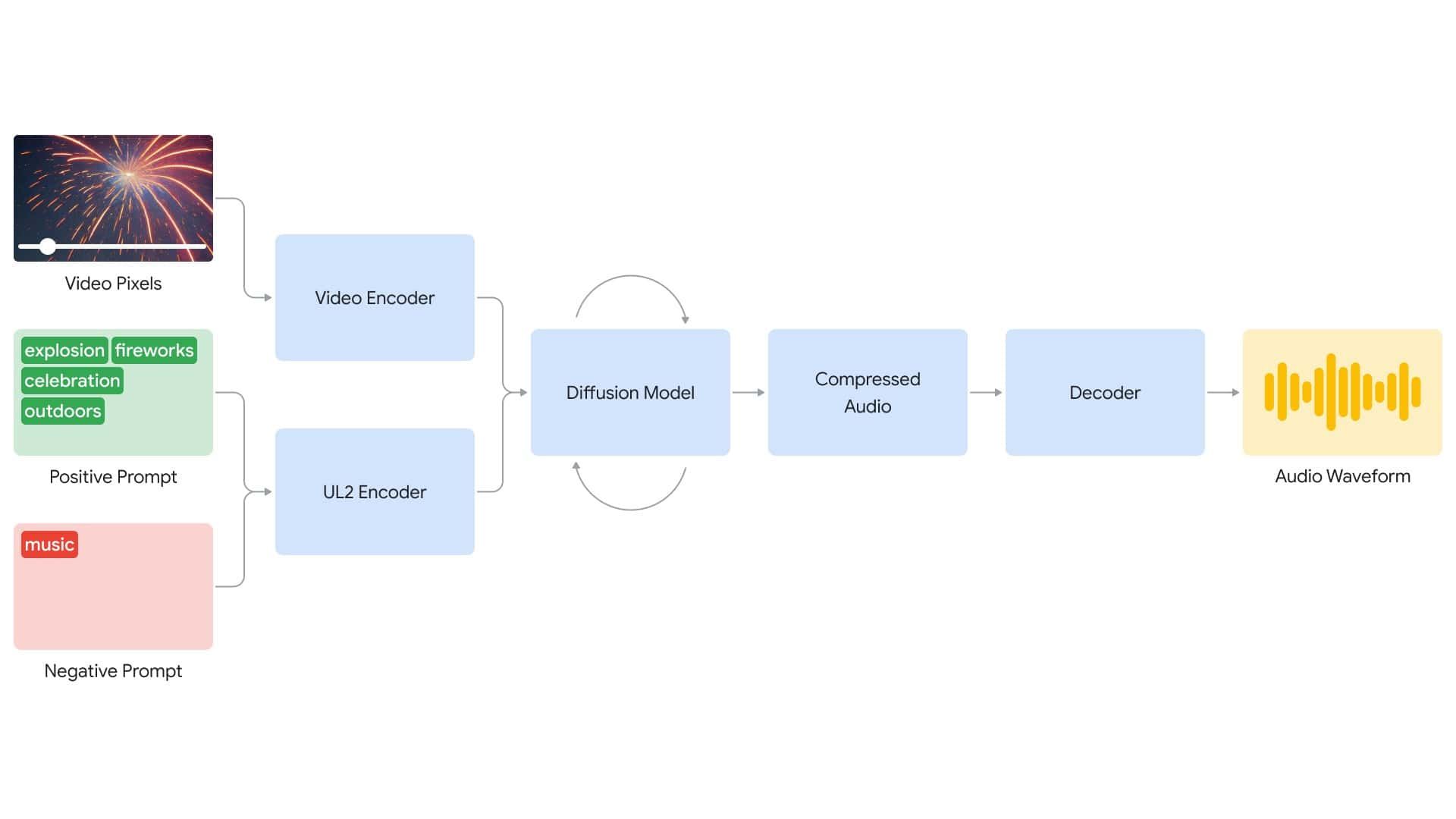
オーディオ品質を向上させるために、DeepMindはトレーニングプロセスにAI生成の音の説明や話された対話の書き起こしを追加した。このようにして、V2Aは特定の視覚的なシーンに対するオーディオイベントを学習し、説明や書き起こしに含まれる情報に対応するようになった。
しかし、V2Aにはいくつかの制約もある。例えば、オーディオ出力の品質はビデオ入力の品質に依存する。モデルのトレーニング分布外のアーティファクトや歪みがビデオに含まれると、オーディオ品質が大幅に低下することがある。また、話し言葉を含むビデオのリップシンクはまだまだ不安定だ。
また、V2Aはまだ一般では利用できない。DeepMindは「クリエイティブコミュニティにプラスの影響を与えることができる」ことを確認するために、主要なクリエイターや映画制作者からフィードバックを収集している。広範なアクセスが考慮される前に、V2Aは厳格な安全評価とテストを受ける予定であると同社は述べている。
Sources
- Google DeepMind: Generating audio for video