
Appleは、iPad Proの発表と共に、これに搭載される次世代Mシリーズチップ「M4」を発表した。この新たなチップの登場は多くのユーザーにとって予想外の事だったろう。なぜなら、M3チップファミリーが2023年11月にデビューしてから、わずか6か月しか経っていない中での新チップ発表だからだ。この動きは、AppleがMicrosoftやGoogleに対するAI分野での遅れを取り戻そうとする、これから発表されるであろう一連の大きな発表の先駆けとなる物と予想される。Appleは最新チップで、特に機械学習/AI性能に重点を置く説明を行い、加えてクラスをリードする性能と電力効率を約束している。
相変わらずAppleは自社チップの詳細をあまり多くは語っていない。以下の概要は現在判明している内容をまとめたものだ。
| M4 | M3 | M2 | |
|---|---|---|---|
| CPUパフォーマンスコア | 最高4コア | 4コア | 4 コア (Avalanche) 16MB 共有 L2 |
| CPU高効率コア | 6コア | 4コア | 4 コア (Blizzard) 4MB 共有 L2 |
| GPU | 10 コア M3 と同じアーキテクチャ | 10 コアの 新しいアーキテクチャ – メッシュ シェーダーとレイ トレーシング | 10コア 3.6 TFLOPS |
| ディスプレイコントローラー | 2 ディスプレイ? | 2 つのディスプレイ | 2 つのディスプレイ |
| ニューラルエンジン | 16 コア 38 TOPS (INT8?) | 16コア 18TOPS | 16コア 15.8TOPS |
| メモリ コントローラー | LPDDR5X-7700 8x 16 ビット CH 120GB/秒 合計帯域幅 (統合) | LPDDR5-6400 8x 16 ビット CH 100GB/秒 合計帯域幅 (統合) | LPDDR5-6400 8x 16 ビット CH 100GB/秒 合計帯域幅 (統合) |
| 最大メモリ容量 | 24GB? | 24GB | 24GB |
| エンコード/ デコード | 8K H.264、H.265、ProRes、ProRes RAW、AV1 (デコード) | 8K H.264、H.265、ProRes、ProRes RAW、AV1 (デコード) | 8K H.264、H.265、ProRes、ProRes RAW |
| USB | USB4/Thunderbolt 3 ポート数不明 | USB4/Thunderbolt 3 2x ポート | USB4/Thunderbolt 3 2x ポート |
| トランジスタ | 280億 | 250億 | 200億 |
| 製造プロセス | TSMC N3E | TSMC N3B | TSMC N5P |
M4はM3から新しいCPUコンプレックスに置き換わり、恐らくM3から大部分を引き継いだと思われるGPUを搭載している。Appleがここで大々的に宣伝しているのはニューラル・エンジン(NPU)で、16コア設計のまま、38TOPSの性能を発揮する。また、メモリ帯域幅も20%増加しているのも興味深いところだ。
これは確定した情報ではないが、Appleの言う「第2世代3nmプロセス」は、TSMCの第2世代3nmプロセス「N3E」とタイミングが完全に一致するため、恐らくこれを採用しているものと思われる。N3EはN3Bほど高密度ではないが、TSMCによればパフォーマンスと電力特性はわずかに優れているとのことだ。
TSMCの新プロセス・ノードを最初に採用する企業は長年にわたりAppleであり、今回のN3EもAppleがまずは最初にそれを採用する事になったようだ。ただし、このN3Eは今後多くのハイエンドチップを製造する顧客に提供されると言われており、Appleのチップ製造における当面の優位性は、一時的なものに過ぎないだろう。
新チップのダイサイズは公表されていないが、総トランジスタ数は280億で、M3よりわずかに大きい程度であり、ここでAppleは大きくアーキテクチャを変更していない事も予想される。
M4:CPUコア
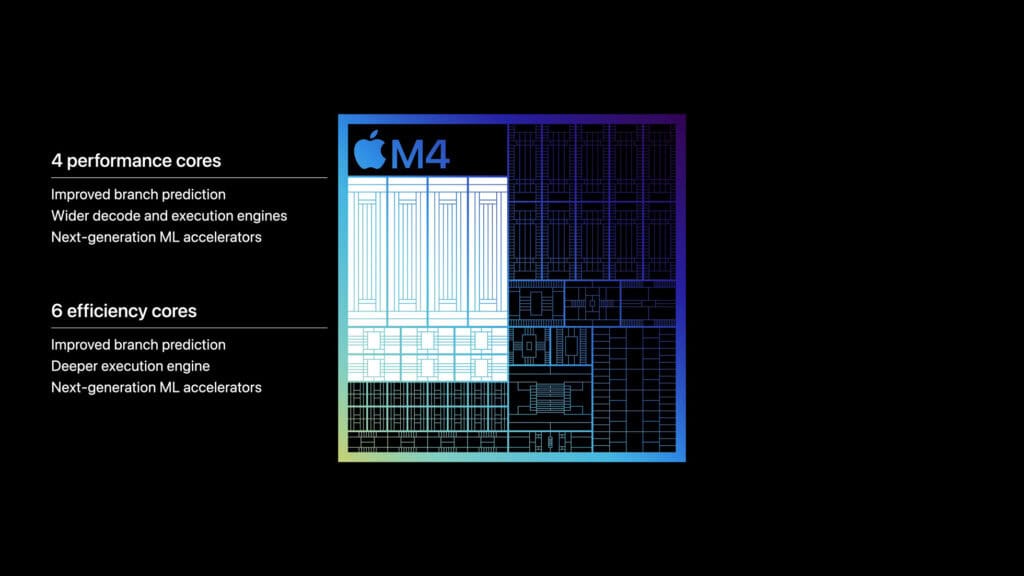
大きく変わった点の一つはCPUコア設計だ。だが、Appleはこれについて多くを語っておらず、M3との性能比較が行われていないこともあり、CPU設計については憶測の域を出ない。
発表で明らかになったのは、パフォーマンスコアと高効率コアの両方が、改善された分岐予測、パフォーマンスコアの場合はより広範なデコードと実行エンジンを実装している事が報告されている。しかし、これらはAppleがM3に対して行った改善と同じものであり、CPUアーキテクチャの変更はここからは確認出来ない。
M4 CPUコアの発表の中で興味深いところは、CPUコア全般での「次世代MLアクセラレーション」機能である。これは、AppleがM4でML/AI性能に幅広くフォーカスしていることと密接な関係があるが、同社はこれらのアクセラレータがどのようなものかを詳しくは説明していない。AI関連の処理はその多くがNPUに処理を任せることになるため、CPUコアのAI処理性能強化の目的は、総スループット/性能よりも、専用NPUを起動する時間とリソースを費やすことなく、より汎用的なワークロードの中に混在する軽量の推論ワークロードを処理することにある。
これは、Appleが、当初からMシリーズSoCの一部であった、文書化されていないAMXマトリックスユニットを更新した可能性に繋がる。しかし、最近のAMXバージョンはすでにFP16、BF16、INT8といった一般的なML数値フォーマットをサポートしているため、Appleがここに変更を加えたとすれば、(より一般的な)フォーマットを追加するといった単純明快なものではないだろう。そして、もしそれがAMXだとしたら、Appleはこれについて少なくともどこかで言及すると思われる。
他の予想としては、AppleがCPU内のSIMDユニットに変更を加え、一般的なMLナンバーフォーマットを追加したということだろう。しかし同時に、Appleは開発者に対し、より高レベルのフレームワークを使用するよう働きかけている。
いずれにせよ、M4を支えるCPUコアが何であれ、1つだけ確かなことがある。M4のフル構成は、4つのパフォーマンスコアと6つの高効率コアの組み合わせで、高効率コアはM3より2つ多い。iPad Proの256/512GBモデルでは3P+6E構成だが、上位モデルでは4P+6Eのフル構成となる。
ただし、この2つの高効率コアの追加は、M3の4P+4E構成に比べてCPU性能の大幅な向上を約束するものではないだろう。しかし、Appleの高効率コアは、アウトオブオーダー実行の使用により比較的強力であるため、その性能差は無視は出来ないものだ。特に、固定ワークロードを高効率で保持し、パフォーマンスコアに昇格させないことができれば、エネルギー効率を向上させる余地は大きいだろう。
それ以外の点では、Appleは新しいSoC/CPUコアの詳細な性能グラフを公表していないため、数字の比較などは困難だ。しかし同社は、M4はM2よりも50%高速なCPU性能、M2の半分の消費電力でM2の性能を実現できると主張している。パフォーマンスに関してはM4のCPUコア数の優位性を活用できるマルチスレッドワークロードの場合だと思われる。また、電力効率に関しても、プロセスノードの改善、アーキテクチャの改善、CPUコア数の増加の組み合わせとして、妥当な主張のように思える。
あとは、実際の製品のベンチマークテストが到着するのを期待したい所だ。
M4:GPUコア
AppleはM3で新しいGPUアーキテクチャを導入したばかりであり、M4のGPUもM3と同じアーキテクチャであることがほぼ確定している。
GPUコアは10個で、それ以外の構成はM3と同じだ。様々なブロックやキャッシュが本当にM3と同じかどうかはまだわからないが、AppleはM4のGPU性能について、M3のGPUより優れているととれる様な発言もしていない。実際、iPadのフォームファクターが小さく、冷却機能が限られているということは、そもそもGPUが持続的な作業負荷の下で熱的制約を受けることを意味する。

いずれにせよ、これはM4がM3のGPUで導入された主要な新アーキテクチャ機能(レイトレーシング、メッシュシェーディング、ダイナミックキャッシュ)をすべて搭載していることを意味する。レイトレーシングは現時点でほとんど紹介する必要がないが、メッシュシェーディングは重要な次世代ジオメトリ処理手段である。一方、ダイナミック・キャッシングとは、Apple用語であり、Mシリーズチップの洗練されたメモリ割り当て技術のことで、Appleの統一されたメモリプールからGPUにメモリを過剰に割り当てることを回避する。
GPUレンダリングはさておき、M4はM3のメディアエンジンブロックもアップデートしている。最も注目すべきは、M3/M4のメディアエンジンブロックが、次世代のオープンビデオコーデックであるAV1ビデオデコーディングをサポートしたことだ。AppleはHEVC/H.265のロイヤリティを支払うことでエコシステム内での利用を可能にしているが、ロイヤリティフリーのAV1コーデックは今後数年のうちに多くの重要性と利用が見込まれており、iPad Proは最新のコーデックを利用しやすい(少なくとも、ソフトウェアでAV1を非効率にデコードする必要がない)立場にある。
しかし、M4に新しく搭載された新しいディスプレイエンジンは重要な点だ。画像を合成し、デバイスに接続されたディスプレイを駆動するブロックであるこのブロックに、Appleが特に大きな注意を払うことはないが、アップデートを行う場合は、通常、すぐに機能改善が行われる。
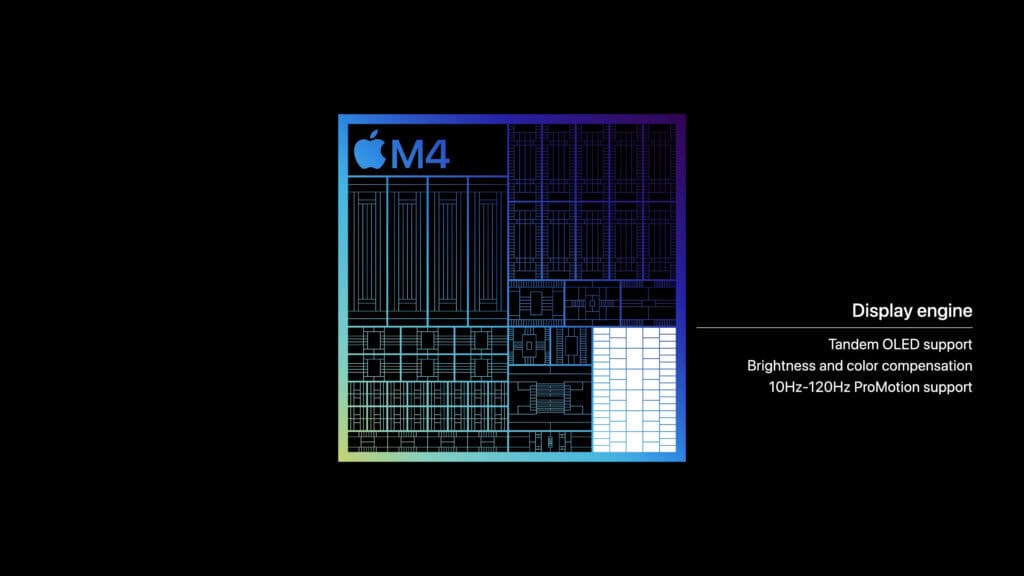
ここでの重要な変更は、iPad Proで初公開されたAppleの新しいサンドイッチ型「タンデム」OLEDパネル構成を可能にすることだと思われる。iPadのUltra Retina XDRディスプレイは、2枚のOLEDパネルを直接重ね合わせることで、Appleの輝度目標である1600ニトを達成できるディスプレイを実現している。そのためには、単にミラーリングされたディスプレイを駆動するだけでなく、1つのパネルが別のパネルの下にあることによる性能低下を考慮し、パネルを操作する方法を知っているディスプレイコントローラーが必要になる。
また、iPad Proとすぐに関係があるわけではないが、標準のMシリーズSoCは通常2台のディスプレイに制限されており、MacBookユーザーを困惑させてきたため、Appleがこの機会を利用してM4が駆動できるディスプレイの総数を増やすかどうかは興味深い。M4がタンデムOLEDパネルとその上の外付け6Kディスプレイを駆動できるという事実は有望だが、M4がMacに搭載された場合に、これがMacのエコシステムにどのように反映されるかは興味深いところだ。
M4:NPUコア
今回のM4チップでAppleが最も力を入れているのは、ニューラルネットワークエンジンとして知られるNPUだろう。AppleはM1以来、16コアの設計を維持しており、世代が進むごとに性能は少しずつ向上してきた。しかし、M4世代では、Appleによると、性能ははるかに飛躍しているという。
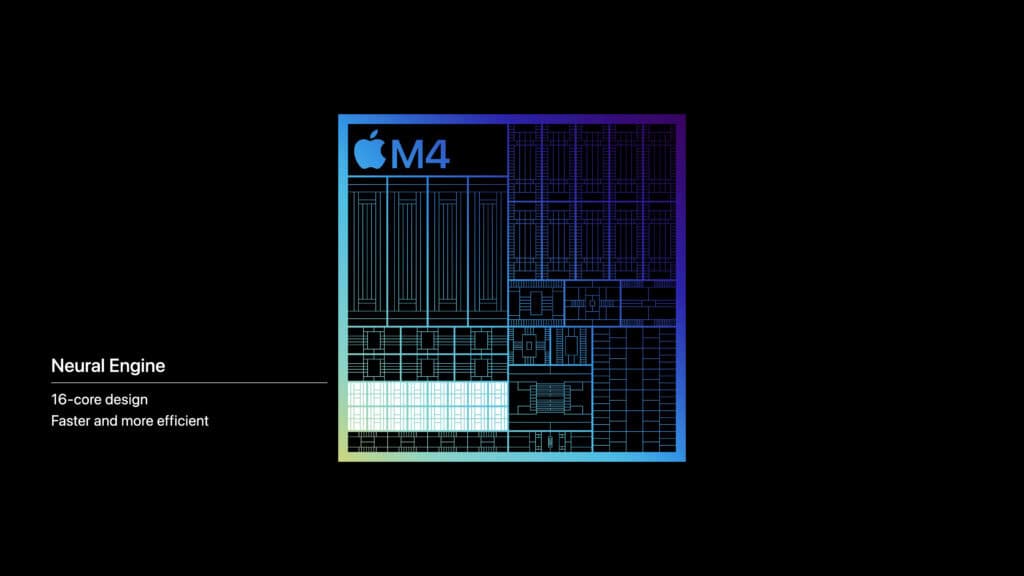
16コア設計のM4 NPUは38TOPSで、M3の18TOPSとされているNerural Engineの2倍強である。A17 ProのNerural Engineが実現する35TOPSより少し高い。これまであまりAI性能が主張されてこなかったMチップにおいて、Appleは、M4のNPUではM3や、以前のiPadに搭載されていたM2よりもかなりパワフルにしたと主張している。同社は、“A11のNPUよりも60倍高速である”と主張している。
ただし残念ながら、Appleはこの数字がINT16精度なのか、INT8精度なのか、はたまたINT4精度なのか、といった重要な精度情報を記載していない。現在のML推論の精度としては、INT8が最も可能性の高い選択肢である。ここら辺を明らかにせず、内部で混在させているのは見かけ上の性能向上を掲げるための意図的なものだろうが、スペックの比較が困難になるため改めてもらいたいところだ。
いずれにせよ、この性能向上のほとんどがINT8サポートによるもので、INT16/FP16サポートによるものではないとしても、M4のNPUコアが、AI性能に大幅な性能向上をもたらす事には間違いないだろう。そしてAppleは自社で完全なハードウェア/ソフトウェア・エコシステムを握っており、キラーアプリの登場を待つ必要もなく、自社のNPUを使用してそれに最適化したソフトウェアを作成できるという利点がある事も見逃せない。
ただ、ライバルとなるQualcommのSnapdragon Xが全てのラインナップでNPUが45TOPSの性能を発揮すると主張しており、後発という点もあるが、依然としてAppleに対して優位に立っている点は、これまでのAppleとの立場の逆転を感じさせるものであり、感慨深くもある。
M4:メモリ性能
細かいところでは、M4でメモリ性能が大幅に向上している点は歓迎すべき所だ。Apple自身が明らかにしているM4チップのメモリ帯域幅が120GB/sであるという仕様から、恐らくLPDDR5Xを採用することを示している。
LPDDR5規格の中間世代アップデートであるLPDDR5Xは、最高6400MT/秒のLPDDR5よりも高いメモリクロック速度を可能にする。LPDDR5Xは現在8533MT/秒までの速度で利用可能だが(今後さらに高速化される予定)、AppleのM4の120GB/秒という数字に基づくと、メモリのクロック速度はおよそLPDDR5X-7700となる。
M4はまずiPadに搭載されるため、現時点では最大メモリ容量について詳しい情報は不明だ。iPad Proはモデルによって8GBまたは16GBのRAMを搭載する。M3は最大24GBのメモリを搭載可能であったため、Appleがここで後退した可能性は低いが、32GBまで拡張可能かどうかも不明だ。
Source
- Apple: Apple、M4チップを発表








コメント