

AMDのZen 5アーキテクチャ採用ノートPC向け「Ryzen AI 300」モバイルプロセッサは2つのSKUが発表されている。上位モデルの「Ryzen AI 9 370HX」については、いくつかのベンチマークテスト結果が流出しているが、下位モデルの「Ryzen AI 9 365」の性能はこれまで不明だった。今回David Huang氏によって初期のRyzen AI 9 365のエンジニアリング・サンプルを用いたノートPCの詳細なテスト結果が共有されている。エンジニアリング・サンプルと言うことで製品版とは異なる面もあるかも知れないが、Zen 5世代のモバイルチップの性能を垣間見ることが出来るという点では参考になるかも知れない。
Ryzen AI 9 365のエンジニアリング・サンプルを様々な側面からテスト
Huang氏は、Ryzen AI 9 365を搭載したノートPCでテストを行った。その他の構成としては、32GBのLPDDR5x-7500が搭載されている。
「Ryzen AI 9 HX 370」と「Ryzen AI 9 365」の違いは、最大ブーストクロック数、CPUコア数や統合GPUのCU(Compute Unit)数に違いがある。
| コア数 | ベースクロック | ブーストクロック | キャッシュ | グラフィック | NPU | TDP | |
|---|---|---|---|---|---|---|---|
| Ryzen AI 9 HX 370 | Zen 5 x 4 Zen 5c x 8 (24スレッド) | 2.0GHz | 5.1GHz | 24 MB | Radeon 890M 16 CU | XDNA 2 (50 TOPS) | 15-54W |
| Ryzen AI 9 365 | Zen 5 x 4 Zen 5c x 6 (20スレッド) | 2.0GHz | 5.0GHz | 24 MB | Radeon 890M 12 CU | XDNA 2 (50 TOPS) | 15-54W |
恐らくユーザーとしては最も興味深いところとしてGeekbenchなどのベンチマークテスト結果が興味深いところだろう。
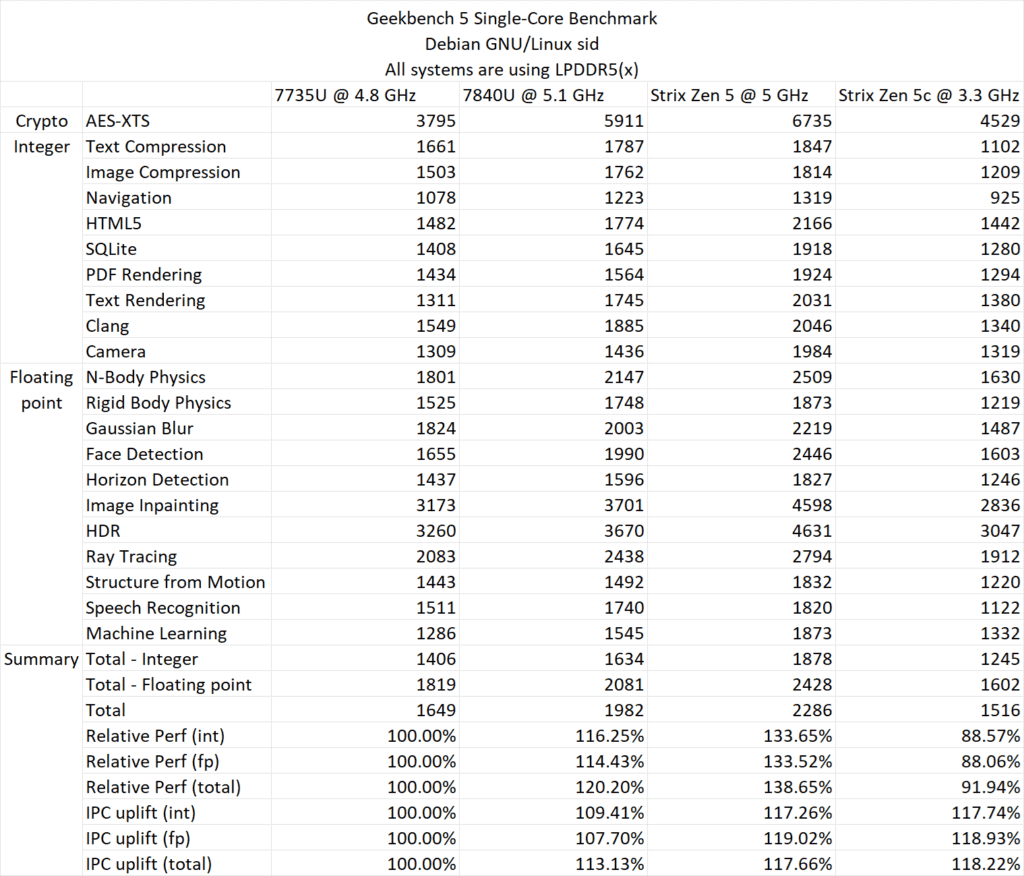
Ryzen AI 9 365チップの比較として、Ryzen 7 7735U(Zen 3)、Ryzen 7 7840U(Zen 4)が用いられた。Ryzen AI 9 365のZen 5Cコアはわずか3.30GHzとかなり低いクロックで動作し、Zen 5コアと他の2チップは4.8GHzの固定クロックに設定されている。
SPEC CPU 2017
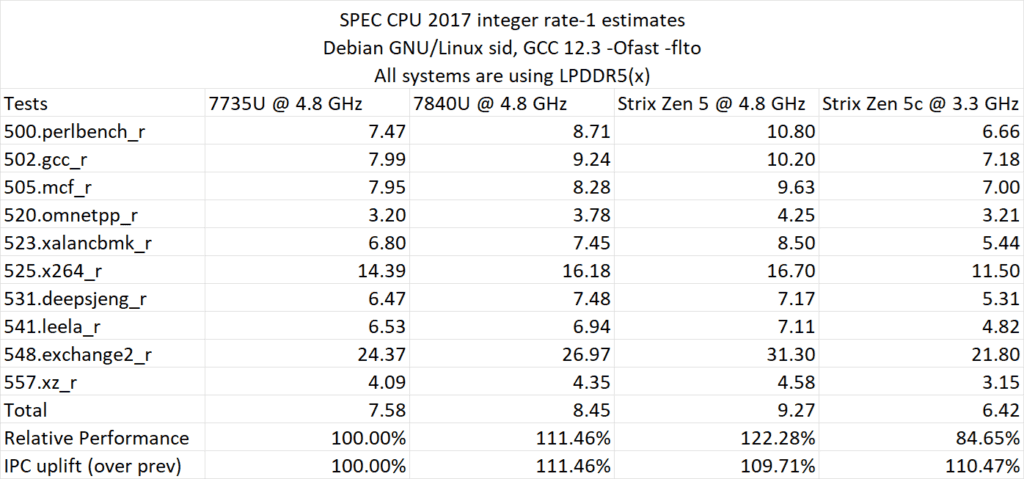
SPEC CPU 2017では、AMD Zen 5チップはZen 4に比べて+9.71%、Zen 3に比べて22.28%向上した。Zen 5Cコアは、低クロックでZen 4のIPCにほぼ匹敵する。
全体的なまとめとしては以下の通りだ:
- perlbenchはAMDの従来の弱点であり、その性能ボトルネックはL1キャッシュ容量およびロード/ストア能力の向上によって大幅に緩和された。また、perlbenchはILP(命令レベルの並列性)が高く、分岐命令の数も適度であり、新しいフロントエンドのスループット向上をうまく活用できた可能性がある。
- x264は主に実行ユニットのボトルネックが原因であり、コンパイラによる自動ベクトル化で大量のSIMD整数演算コードが生成される。前述の分析からわかるように、Strix PointのZen 5はこの点で全く進歩がなく、むしろかなりの後退が見られる。そのため、マイクロアーキテクチャの向上はこれらSIMDの削減によって相殺される可能性が高く、このテストで完全なZen 5の性能を引き出すにはデスクトップ版を待つしかないだろう。
- 以前のZen 4でSPECを実行した性能カウンター分析では、531項目は6.75Kのマクロオペレーションキャッシュを持つZen 4コアでさえ、非常に高いマクロオペレーションキャッシュMPKI(ミス数/キロ命令)を引き起こすことが示されている。Zen 5ではこの点がかなり削減されており、命中率がさらに低下することが予想され、IPC(命令あたりのサイクル数)の低下に関連していると推測される。
Geekbench
Geekbenchの結果を見る限りでは、Zen 5のIPC向上は公式の宣伝通りの結果だったという。
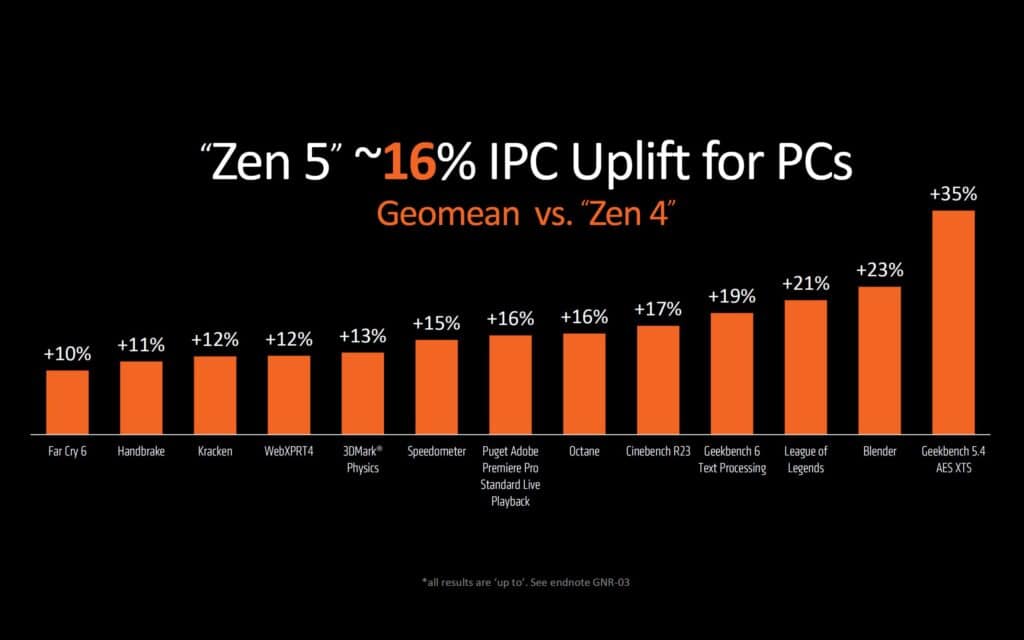
Geekbench 6の結果を見てみると、シングルコア・スコアに関しては、Zen 5のZen 3に対する相対的な性能向上は最大40.94%という結果が見られる。Zen 4からの性能向上は約13.1%だ。これはブーストクロックが5.0GHzと、Zen 4の5.1GHzよりも100MHz低いにもかかわらずの結果ということで注目すべきポイントだろう。
| Ryzen 7 7735U (Zen 3) @4.8GHz | Ryzen 7 7840U (Zen 4) @5.1GHz | Ryzen AI 9 365 (Zen 5) @5GHz | Ryzen AI 9 365 (Zen 5c) @3.3GHz | |
|---|---|---|---|---|
| Geekbench 6 シングルコア・スコア | 2125 | 2650 | 2995 | 2012 |
| Geekbench 5 シングルコア・スコア | 1649 | 1982 | 2286 | 1516 |
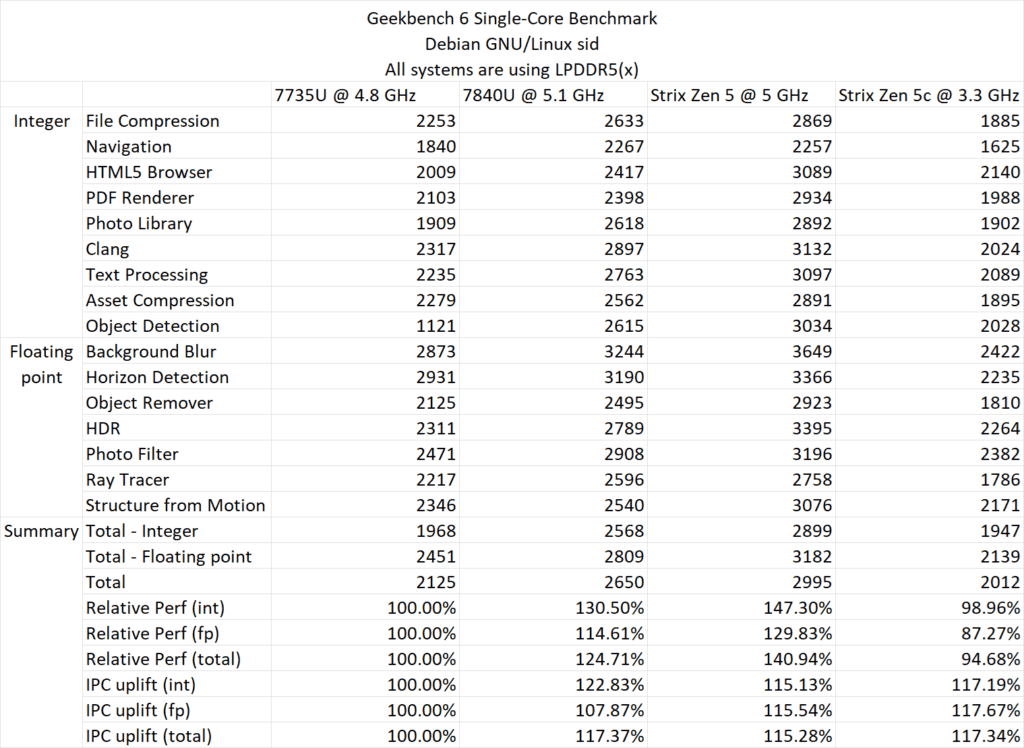
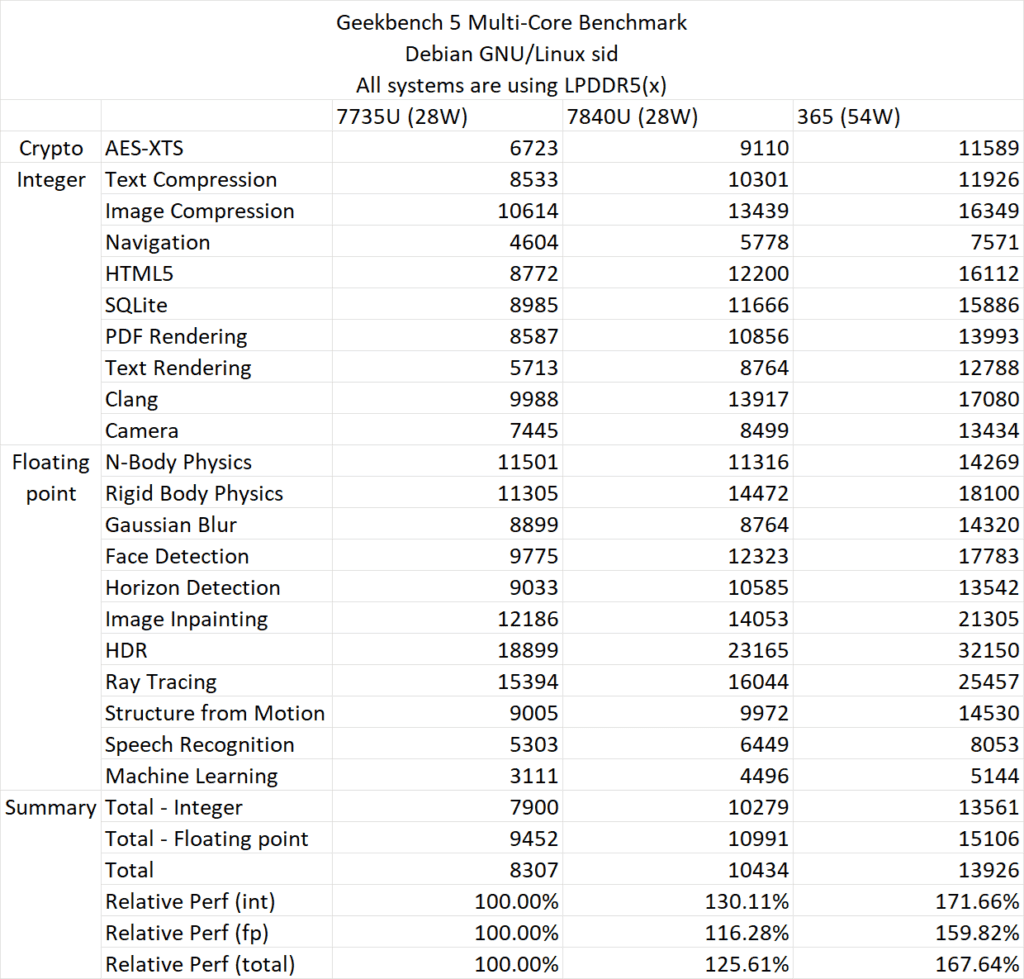
また、マルチコア・スコアでは、Zen 5はZen 3に対して55.45%、Zen 4に対して24.3%向上している。ただしこの点に関しては、Zen 3とZen 4チップがTDP28Wであるのに対し、Ryzen AI 9 365 APUのTDPは54Wであるため、その点には注意する必要がある。
| Ryzen 7 7735U (Zen 3) @28W | Ryzen 7 7840U (Zen 4) @28W | Ryzen AI 9 365 (Zen 5) @54W | |
|---|---|---|---|
| Geekbench 6 マルチコア・スコア | 9571 | 11690 | 14530 |
| Geekbench 5 マルチコア・スコア | 8307 | 10434 | 13926 |
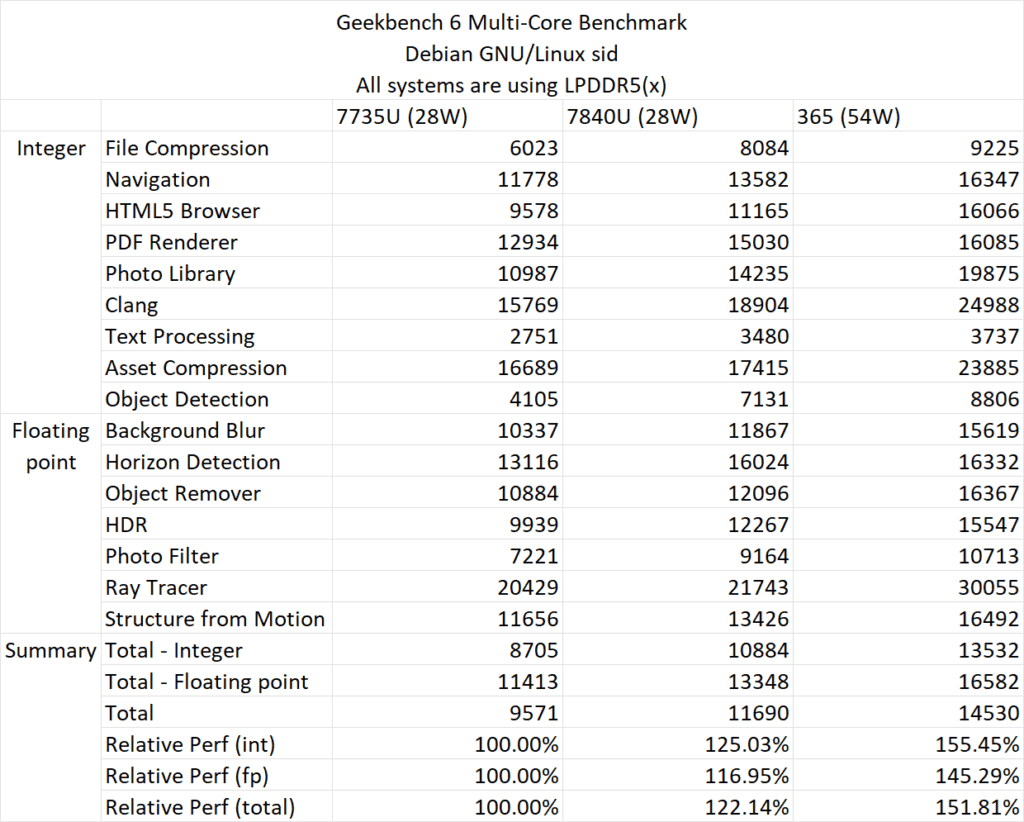
Geekbench 6のObject DetectionサブセクションはAVX512-VNNIまたはAVX-VNNIを使用して高速化されるため、Zen 4はこのテストでZen 3に比べて2倍以上の性能を発揮し、大きな成長を見せている。逆にモバイルZen 5は、Zen 4とAVX512のスコアに関しては向上はほとんど見られない。
命令スループット
Huagn氏はまずInstructionRateツールでZen 3、Zen 4、Zen 5アーキテクチャを含む3世代のZen CPUの命令スループット/レイテンシを測定した。
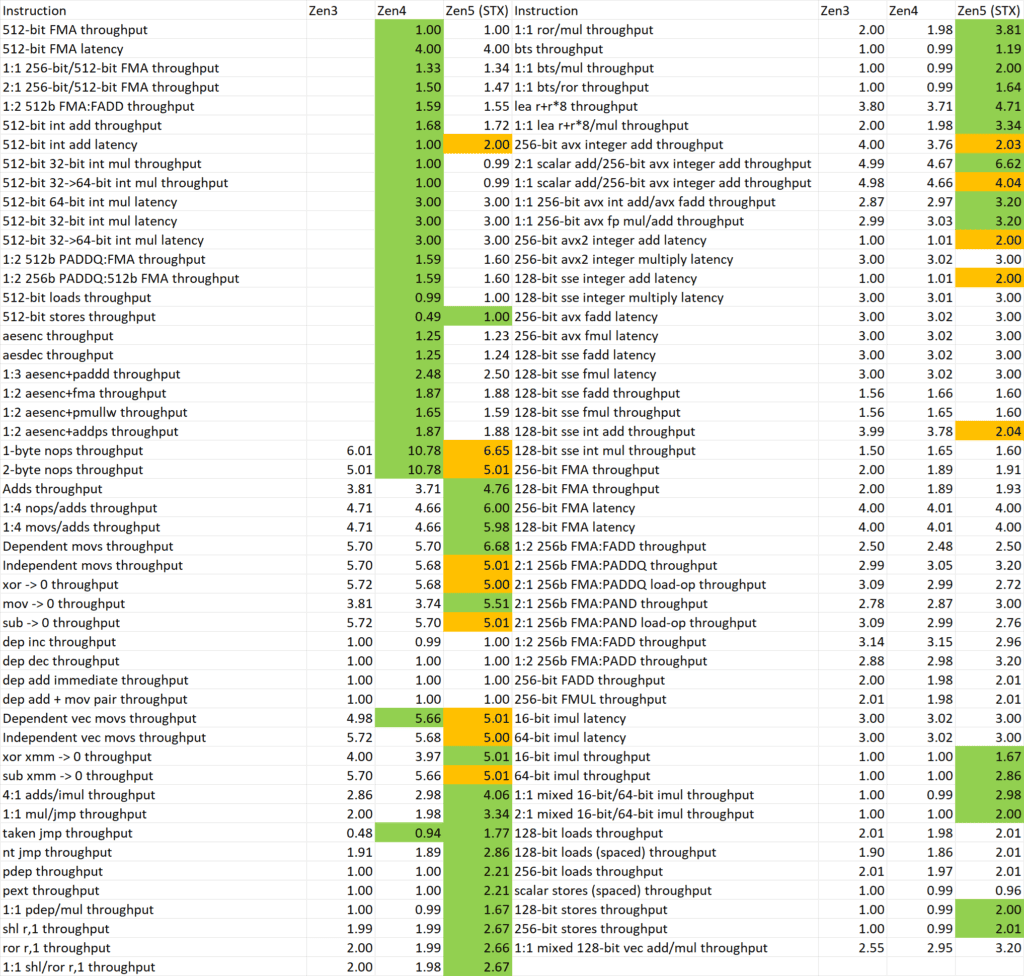
David氏はZen 5が0から設計し直されたことで改善された点がある一方で、いくつかの欠点もあることも指摘している:
- 様々なスカラALU命令のスループットは大幅に向上しているが、モバイル版のZen 5ではデスクトップやサーバーと比べてベクトルユニットの数が半分になっているため、このテストにおけるSIMDスループットはZen 4と変わらない。ベクトルユニットが半分になったZen 5コアでも、全ての幅のSIMDストア操作は前世代に比べて倍増しており、SIMDロードストアスループットは1:1に達している。
- 分岐処理能力は大幅に強化され、サイクル当たり処理可能な未実行分岐の数は2から3に増加し、2つの実行分岐もサイクル当たり処理できるようになった。これは新しいフロントエンド設計に関連していると思われる。
- 128/256/512ビットのSSE/AVX/AVX512 SIMD整数加算計算のレイテンシは全て2サイクルに増加している。この変更は高周波数を維持しやすくするためのものである可能性がある。
- 128/256ビットのSIMD整数加算操作のスループットはZen 4と比べて半減しているが、512ビットでは変わらない。この問題はSIMDが半分になったZen 5コアにのみ存在し、ポート割り当てに関連していると推測される。
- Zen 4で導入されたnop融合機能が削除された。同じマクロオペレーションでnop命令と他の命令を結合することはできなくなった。
- いくつかの論理レジスタ操作のスループットが調整され、いくつかのmov操作といくつかのレジスタゼロ化操作のスループットが5に統一され、これはZen 4と比較して増減がある。
命令フェッチ、デコード、マクロオペレーションキャッシュ
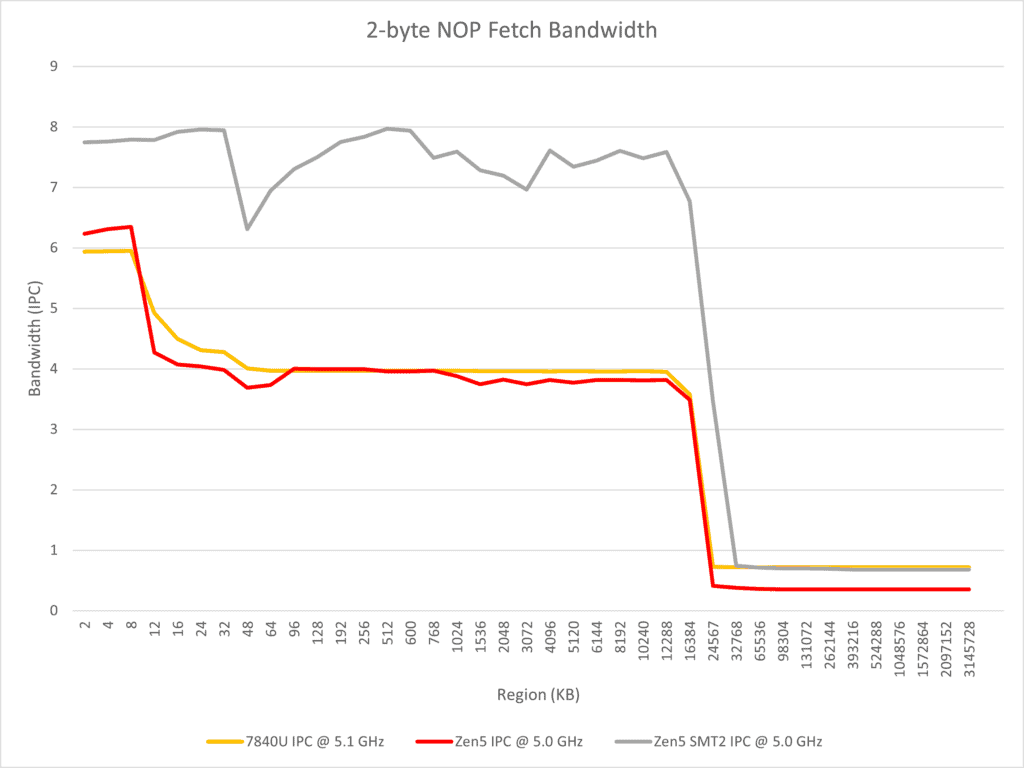
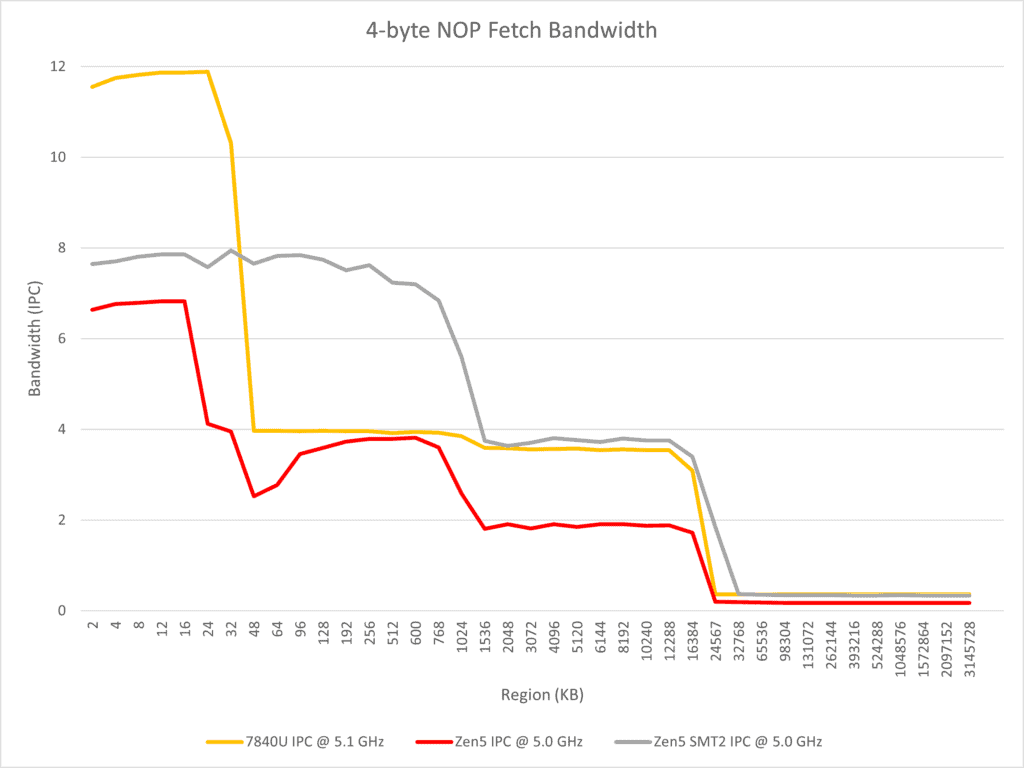
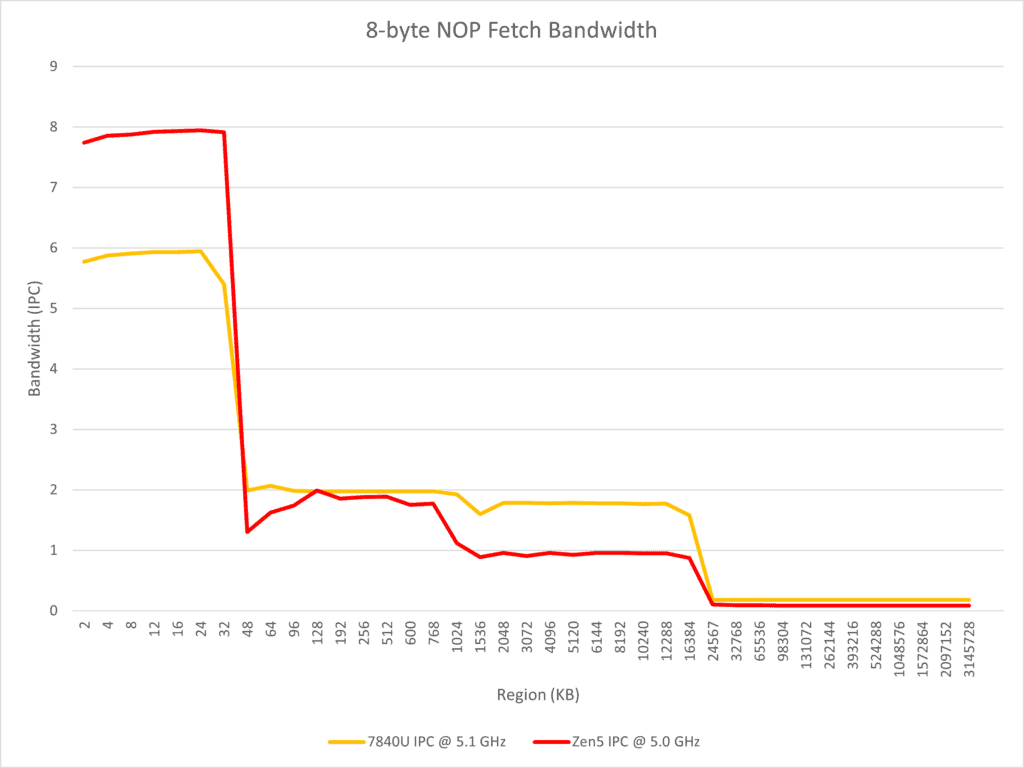
テストでは、命令のフェッチ、デコード、およびマクロオペレーションキャッシュに影響を与えるParallel dual pipeフロントエンドにも焦点を当てている。異なる長さと数のNOP命令を実行することで、Zen 4とZen 5の違いが観察される。その観察結果は以下の通りである。
- Zen 5はTremontに似たマルチフロントエンド設計を採用しているが、より広く、2つの4ワイドx86デコーダと少なくとも8ワイドのマクロオペレーションキャッシュを使用して8ワイドリネームを実現している。
- 次の現象を考慮すること:
- Zen 5は連続したNOP命令を単一スレッドで実行するときにx86デコード帯域幅を4以上にすることができない。
- 命令スループットセクションでは、2つの実行分岐が単一サイクルで処理できることがテストされている。
- Zen 5がGracemontに似たプリデコードILDキャッシュソリューションを使用していないと推測するのは合理的であるが、分岐予測器が実行分岐を予測したときに2つのデコーダが同時に動作する必要があり、つまり、1つのデコーダが次の分岐ターゲットアドレスからデコードを開始するように直接する必要がある。この観点から、AMDはスパースな分岐があるシナリオで高スループットを達成するためにマクロオペレーションキャッシュに依存し続ける必要がある。
- Zen 5は同一サイクル内で2つの場所からx86命令をデコードするだけでなく、同一サイクル内でマクロオペレーションキャッシュから2つの場所から命令をフェッチすることもサポートしており、マクロオペレーションキャッシュのカバレッジ内でサイクル当たり2つの実行分岐を達成することができる。
- コアが2つのSMTスレッドを実行するとき、それぞれがデコーダを独占できるため、ほとんどの場合、コア全体のx86デコードスループット制限は8に達する。
メモリアクセスレイテンシと帯域幅
Zen 5はキャッシュ容量とコアトポロジには大きな変更がなく、この点でもZen 4と比較して大きな差はないようだ。
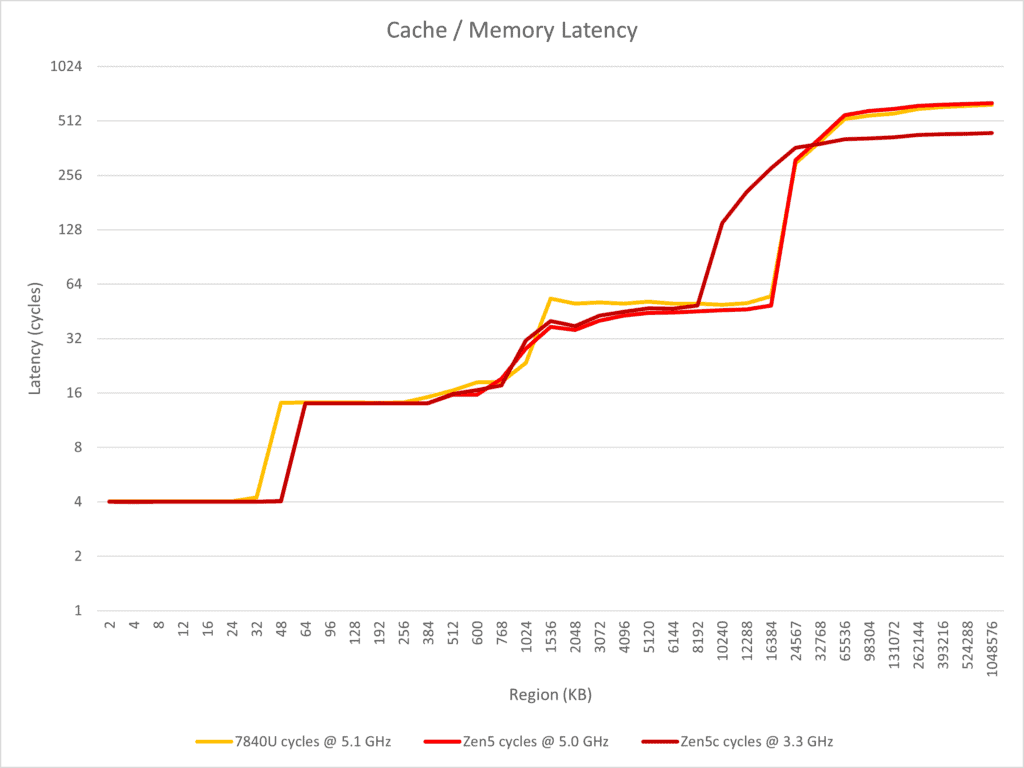
- Zen 5はL1キャッシュを48 KBに増加し、レイテンシは4サイクルのままである。
- L1レイテンシ性能はIce Lake以降に実装された48 KB L1のマイクロアーキテクチャよりも優れており、近日発売予定のArrow Lake (Lion Cove) と同じである。
- L2レイテンシ特性は全体的に変わらず(1MB 14サイクル)。
- L3レイテンシは50サイクルから約46サイクルに減少している。
- Zen 5の周波数が大きく低下していないことを考えると、L3レイテンシが小幅ながら改善されたと考えられる。
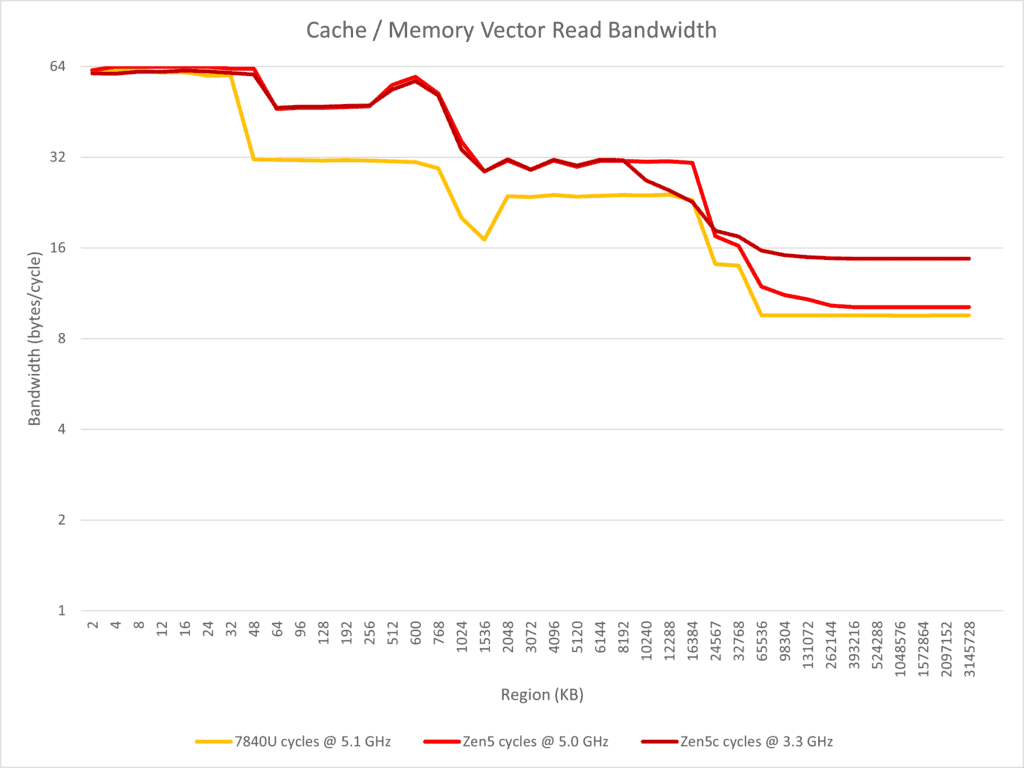
次にSIMD読み取り帯域幅のテストを行った結果は以下の通りだ:
- SIMD仕様が半減されたZen 5のL1読み取り帯域幅はZen 4とほぼ同じで、どちらも毎サイクル64バイトである。
- L1とは異なり、L2帯域幅の倍増特性は保持されている。
- シングルスレッドでのL3読み取り帯域幅は理論的な毎サイクル32バイトに近く、Zen 4の毎サイクル約24バイトよりも優れている。
Huang氏は、コードネーム「Strix Point」ことRyzen AI 300がモバイルについて、キャッシュが半減しているのはいつものことながら、これまでになかったSIMDユニットの半減、そして前モデルよりも低い周波数により、Zen 5モバイルプラットフォームとデスクトップ版との総合的な性能差は過去最大の物になると予想している。
AMDのZen 5シリーズは、モバイル向けStrix Point「Ryzen AI 300」シリーズが7月15日頃に、デスクトップ向け「Ryzen 9000」シリーズが7月31日に登場すると言われている。
Sources







コメント