

Broadcomは、次世代AI処理ユニット(XPU)向けの画期的な3.5D eXtreme Dimension System in Package(XDSiP)プラットフォームを発表した。この新技術は、最大6000mm²の3D積層シリコンと12基のHBMメモリを1つのパッケージに統合可能とし、大規模AIワークロード向けの高効率・低消費電力コンピューティングを実現する。
革新的な Face-to-Face 技術がもたらす飛躍的な性能向上
Broadcomが開発した3.5D XDSiPプラットフォームの中核を成すFace-to-Face(F2F)スタッキング技術は、チップの設計と実装に根本的な革新をもたらしている。従来の積層技術では、シリコン貫通電極(TSV)を使用してチップを上下に重ねるFace-to-Back方式が主流であったが、F2F技術はこの常識を覆す設計思想を採用している。
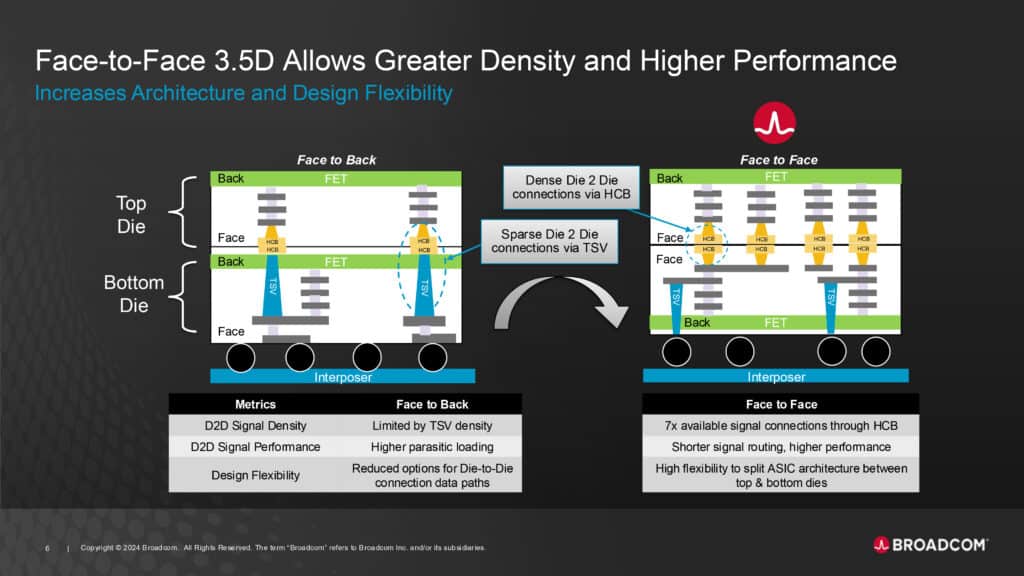
この新技術の最も重要な特徴は、上下のダイの金属層を直接接続するハイブリッド銅接合(HCB)の採用にある。これにより、チップ間の電気的な接続距離を極限まで短縮することが可能となった。その結果、従来のFace-to-Back方式と比較して、積層されたダイ間の信号密度は7倍という劇的な向上を実現している。さらに、この直接接続方式により、ダイ間インターフェースにおける消費電力を90%削減することにも成功した。

F2F技術の革新性は、電気的特性の向上だけにとどまらない。上下のダイを直接接合する構造により、優れた機械的強度と信頼性も実現している。また、電気的な干渉も最小限に抑えられることから、高密度実装における信号品質の維持も容易になっている。
Broadcomは、この3.5Dプラットフォームに独自の知的財産と設計フローを組み込んでおり、電力配分、クロック配信、信号相互接続などの3D積層に関する課題を、設計段階から最適化することを可能にしている。これは、単なる物理的な接続技術の革新を超えて、チップ設計の方法論そのものを変革する可能性を秘めている。
パッケージング技術の観点からも、F2F技術は大きな利点をもたらしている。インターポーザーとパッケージのサイズを縮小できることで、製造コストの削減とパッケージの反りの改善にも貢献している。これは、大規模な演算処理ユニットの製造における歩留まりと信頼性の向上に直接的な効果をもたらすものと期待されている。
AIトレーニング革新への対応
現代の生成AIモデルのトレーニングは、かつて想像もできなかったスケールの計算能力を必要としている。Broadcomの資料によると、現在のAIトレーニング施設では10万基規模のXPUクラスターが稼働しており、その規模は近い将来100万基にまで拡大すると予測されている。この急激な需要の拡大は、チップ設計における根本的なパラダイムシフトを必要としていた。
従来のチップ設計手法は、ムーアの法則に基づくプロセススケーリングに大きく依存してきた。しかし、この手法は物理的限界に直面しつつある。特に、大規模言語モデル(LLM)の複雑化に伴い、単純な微細化だけでは性能要求を満たすことが困難になってきている。これは、計算能力、メモリ帯域幅、そしてI/O性能の統合的な向上が必要とされる現代のAIワークロードにおいて、特に顕著な課題となっている。
この課題に対して、過去10年間にわたり2.5D統合技術が活用されてきた。この技術では、最大2500mm²のシリコンと8基までのHBMモジュールをインターポーザー上に配置することが可能であった。しかし、新世代のLLMトレーニングでは、さらなる性能向上とともに、サイズ、消費電力、コストの最適化が求められている。
Broadcomの3.5D XDSiPプラットフォームは、この要求に応えるために、3Dシリコン積層と2.5Dパッケージングを組み合わせた革新的なアプローチを採用している。同社の第一号となるF2F 3.5D XPUは、4つのコンピュートダイと1つのI/Oダイ、そして6基のHBMモジュールを統合している。これらのコンポーネントは、TSMCの最先端プロセスノードと2.5D CoWoSパッケージング技術を駆使して実現されている。
業界からの評価と今後の展開
TSMCのBusiness Development & Global Sales担当上級副社長兼Deputy Co-COOのDr. Kevin Zhangは、「TSMCとBroadcomは数年にわたり緊密に協力し、TSMCの最先端ロジックプロセスと3Dチップスタッキング技術をBroadcomの設計専門知識と組み合わせてきた」とコメントしている。

特筆すべき展開として、富士通の先端技術開発本部長である新庄 直樹氏は、同社の次世代2ナノメートルArmベースプロセッサ「FUJITSU-MONAKA」に本技術を採用することを発表。このプロセッサには、288個のArmコアが搭載され、5ナノメートルプロセスで製造されたキャッシュモジュール上に配置される予定である。Fujitsuは2027年の製品化を目指している。
Xenospectrum’s Take
Broadcomの3.5D XDSiPは、単なる技術革新を超えた戦略的な意味を持つ。現在のAI革命において、計算能力はボトルネックとなっており、従来のチップ設計手法では限界に達している。同社が実現したF2F技術による7倍の信号密度向上と90%の電力削減は、理論値としては印象的な数字である。しかし、実際の製品での性能向上がどの程度になるかは、2026年2月の出荷開始まで未知数だ。
特に注目すべきは、すでに5つの3.5D製品が開発中という点である。これは、市場がこの技術の潜在力を強く認識していることを示している。ただし、6000mm²という巨大な積層シリコンの熱管理と製造歩留まりは、今後の重要な課題となるだろう。また、富士通の採用決定は、この技術が汎用プロセッサ市場にも波及する可能性を示唆している点で興味深い。
Source










コメント