TikTokの親会社であるByteDanceが、新たな高性能推論AI「Seed-Thinking-v1.5」を発表した。MoEアーキテクチャと独自の強化学習技術を駆使し、主要ベンチマークでGoogleのGemini 2.5 ProやOpenAIのo3-mini-highに匹敵、一部では凌駕するという、驚きの性能を見せている。
推論AI競争にByteDanceが参入:Seed-Thinking-v1.5とは
2024年9月のOpenAI「o1」モデル発表、そして2025年1月のDeepSeek「R1」リリース以降、AI業界は新たな「推論(reasoning)」モデル開発競争に突入している。これらのモデルは、応答に多少時間を要するものの、より深く、網羅的で、論理的に「考え抜かれた」回答を生成することを目指す。その実現のために、「思考の連鎖(Chain-of-Thought: CoT)」を実行し、自身の結論を内省し、応答前にその正当性を検証するプロセスを経るのが特徴だ。
この潮流に、TikTokを運営する中国の巨大ソーシャルメディア企業ByteDanceが加わった。同社は、科学・技術・工学・数学(STEM)分野および汎用領域における推論性能の向上を目的とした大規模言語モデル(LLM)「Seed-Thinking-v1.5」を発表し、その技術論文を公開した。
記事執筆時点(2025年4月12日)では、Seed-Thinking-v1.5はダウンロードや利用はできない。ライセンス形態も、プロプライエタリ(非公開)かオープンソースか、あるいはその中間形態になるかは不明である。しかし、公開されたテクニカルペーパーには注目すべき詳細が含まれており、取り上げる価値のある物だ。
技術的特徴:効率性を追求したMoEアーキテクチャ
Seed-Thinking-v1.5は、MetaのLlama 4やMistralのMixtralと同様に、近年注目を集める「混合専門家(Mixture-of-Experts: MoE)」アーキテクチャを採用している。MoEは、複数の専門モデル(エキスパート)を一つに統合し、それぞれが異なる領域を担当することで、モデル全体の効率を高める設計思想である。
Seed-Thinking-v1.5の場合、総パラメータ数は2000億に達するが、MoEアーキテクチャにより、推論時にはその一部である200億パラメータのみを活性化させる。これにより、比較的小規模な計算リソースで高い性能を発揮することを目指している。ByteDanceの技術論文によれば、このモデルは構造化された推論と思慮深い応答生成を優先しているという。
驚異的な性能:主要ベンチマークでの結果
Seed-Thinking-v1.5の性能は、第三者機関によるベンチマーク評価の結果によって裏付けられている。
テクニカルペーパーによれば、主な結果は以下の通りだ。
- AIME 2024(数学コンテスト): 86.7%を達成。これはOpenAIのo3-mini-high(87.3%)に匹敵し、DeepSeek R1(79.8%)を大幅に上回る。
- Codeforces(競技プログラミング)pass@8: 55.0%を達成。DeepSeek R1(45.0%)を上回り、Google Gemini 2.5 Pro(56.3%)に迫る。pass@8は、8回の試行で問題を解決できるかを示す指標で、実際のユーザーの提出パターンに近いとされる。
- GPQA Diamond(科学分野): 77.3%を達成。o3-mini-high(79.7%)、Gemini 2.5 Pro(84.0%)には及ばないものの、DeepSeek R1(71.5%)を上回る高スコアである。論文によれば、この性能向上は、ドメイン固有の科学データ増加よりも、数学トレーニングからの汎化能力向上によるところが大きいという。
- ARC-AGI(汎用人工知能への進捗指標): 39.9%を達成。これはDeepSeek R1(18.3%)、o3-mini-high(25.8%)、Gemini 2.5 Pro(27.6%)を上回る結果であり、特に注目に値する。OpenAIの定義によれば、AGI(汎用人工知能)は「ほとんどの経済的に価値のあるタスクで人間を上回るモデル」であり、ARC-AGIはその進捗を測る指標の一つとされる。
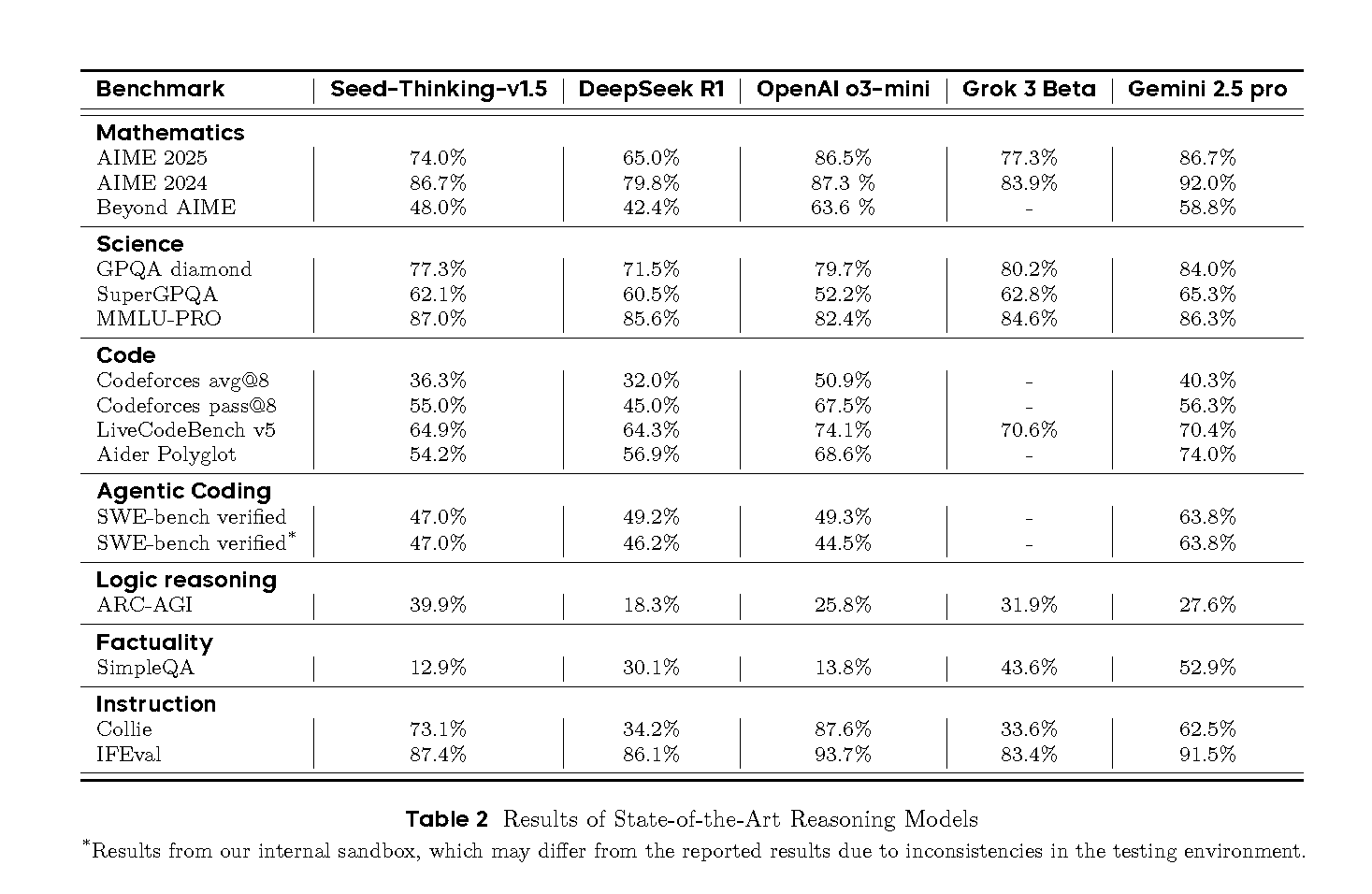
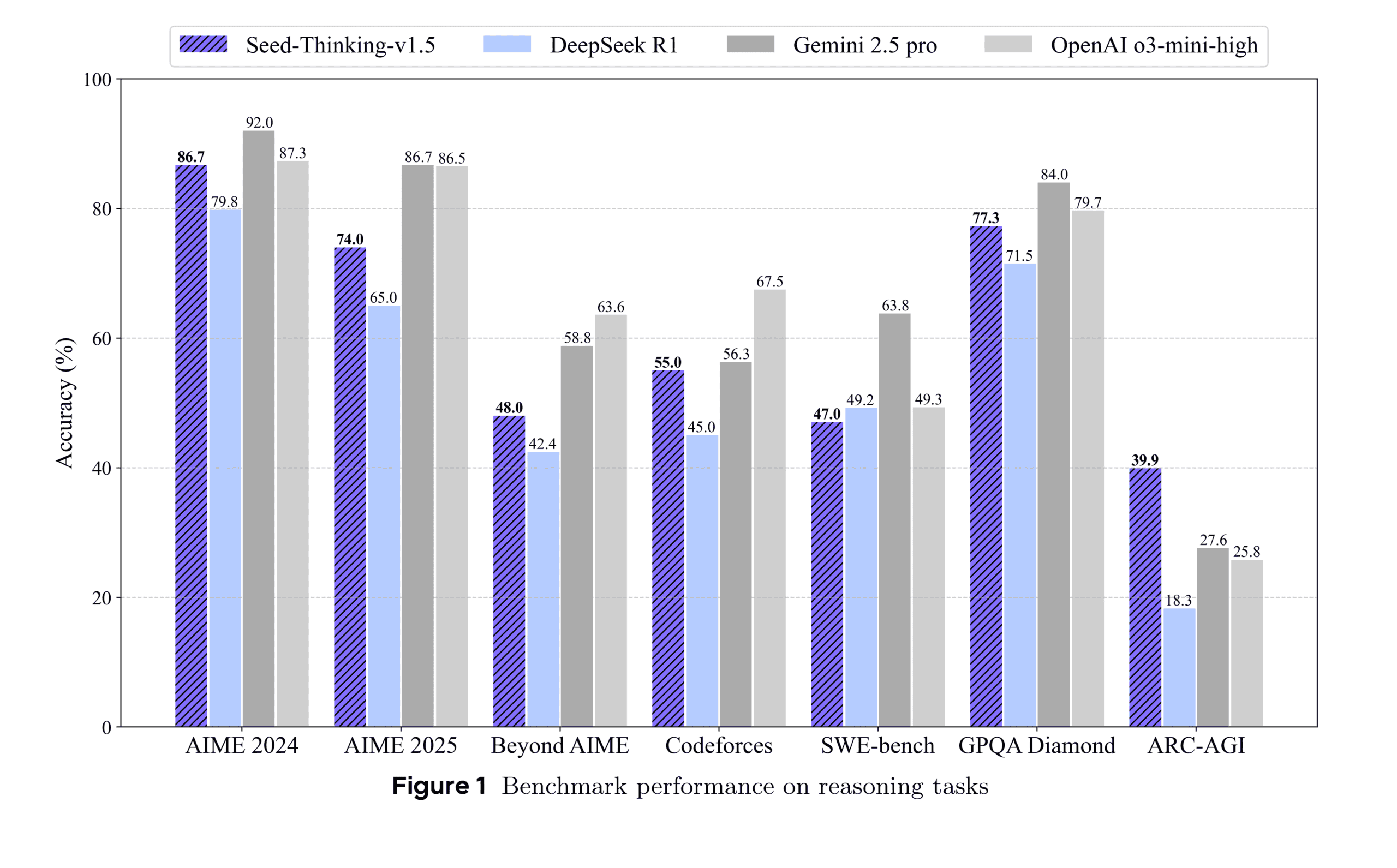
これらの結果は、Seed-Thinking-v1.5が最先端の推論モデルと比較して高い競争力を持つことを示唆している。特に、比較的小さな活性化パラメータ数でこの性能を達成している点は注目に値する。
さらに、推論以外のタスク(創造的な執筆、人文知識、一般会話など)における人間による評価でも、DeepSeek R1に対して8.0%高い勝率を達成した。これは、Seed-Thinking-v1.5の強みが論理や数学といった特定の課題に留まらず、より広範な実用性を持つことを示している。
性能を支える技術(1):データ戦略と独自ベンチマーク
Seed-Thinking-v1.5の開発において、トレーニングデータは中心的な役割を果たした。
- 教師ありファインチューニング(SFT): 40万サンプルのデータセットが用いられた。内訳は、検証可能な問題(STEM、論理、コーディングタスク)が30万、検証不可能な問題(創造的な執筆、ロールプレイングなど)が10万である。特に推論モデルでは、段階的な思考プロセスを明示するChain-of-Thought形式のデータが重要となる。
- 強化学習(RL)トレーニングデータ:
- 検証可能問題: 10万件。エリートレベルのコンペティションや専門家レビューから厳選された、正解が既知のSTEM問題(特に数学が80%以上)と論理パズル(数独、24ポイントパズルなど、難易度調整可能)。
- 検証不可能タスク: 人間の嗜好に基づいたデータセット。自由形式のプロンプトに対する応答を、ペアワイズ(対比較)報酬モデルで評価。
データ戦略の特筆すべき点として、ByteDanceは既存ベンチマークの飽和問題に対処するため、「BeyondAIME」という新たな高難易度数学ベンチマークを開発した。これは、記憶や推測による正解を最小限に抑えるよう専門家によって新たに作成された問題群で構成され、モデルの真の推論能力をより正確に評価することを目的としている。BeyondAIMEとCodeforcesの評価セットは、今後の研究支援のために公開される予定だ。
性能を支える技術(2):安定性を高めた強化学習
強化学習(RL)は推論モデルの性能向上に不可欠だが、トレーニングプロセスが不安定になりやすいという課題がある。Seed-Thinking-v1.5では、この課題に対処するために独自のフレームワークが開発・導入された。
- カスタムRLフレームワーク: アクタークリティック法向けのVAPOと、方策勾配法向けのDAPOという2つのフレームワークが開発された。これらは、特に長い思考連鎖(CoT)を伴う設定において、報酬信号のスパース性を低減し、トレーニングの安定性を向上させることを目的としている。技術論文によれば、VAPOはアクタークリティック法のSOTA(State-of-the-Art: 最新鋭)、DAPOは方策勾配法の新たなSOTAを確立したとされる。
- 高度な報酬モデリング: RLの出力を監督する報酬モデルにも革新が加えられた。
- Seed-Verifier: 人間が作成した原則に基づき、生成された回答と参照回答が数学的に同等かどうかを判定するルールベースLLM。「YES/NO」で評価する。
- Seed-Thinking-Verifier: 人間の判断プロセスに触発され、詳細な推論パスを提供しながら評価を行う、より高度な検証ツール。参照回答と生成回答の類似点・相違点を詳細に分析し、よりニュアンスのある正確な判断を下す。これにより、Seed-Verifierが抱える報酬ハッキング(問題を理解せずに報酬を得ようとする行為)や不確実性、コーナーケースでの失敗といった問題を大幅に軽減する。技術論文のTable 1によれば、人間がラベル付けしたテストセットでの精度は、Seed-Verifierが82.7%に対し、Seed-Thinking-Verifierは99.3%と極めて高い。
この2段階の報酬システムにより、単純な問題から複雑な問題まで、より信頼性の高い報酬信号を提供することが可能になった。
性能を支える技術(3):大規模学習を可能にするインフラ
Seed-Thinking-v1.5のような大規模モデルの効率的なトレーニングには、堅牢なインフラが不可欠である。ByteDanceは、自社のHybridFlowフレームワーク上にシステムを構築し、以下の技術革新を導入した。
- 実行環境: Rayクラスター上で実行され、トレーニングと推論プロセスを同一場所に配置することでGPUのアイドル時間を削減。
- Streaming Rollout System (SRS): モデルの進化とランタイム実行を分離する革新的なシステム。部分的に完了した生成をモデルバージョン間で非同期に管理することで、反復速度を高速化。これにより、RLサイクルが最大3倍高速化したと報告されている。
- その他の技術:
- 混合精度(FP8): メモリ使用量を削減。
- エキスパート並列処理とカーネル自動チューニング: MoEアーキテクチャの効率を向上。
- ByteCheckpoint: 柔軟で回復力のあるチェックポイントシステム。
- AutoTuner: 並列処理とメモリ構成を最適化。
これらのインフラ技術により、大規模なRLトレーニングの安定性と効率性が確保されている。
ByteDanceの推論モデル参入による影響
Seed-Thinking-v1.5の登場は、特に技術リーダー、データエンジニア、企業の意思決定者にとって重要な意味を持つ。
- 技術リーダー: 検証可能なデータセットや多段階の強化学習を含むモジュール式のトレーニングプロセスは、LLM開発をスケールさせつつ詳細な制御を維持したいチームにとって魅力的である。Seed-VerifierとSeed-Thinking-Verifierによる信頼性の高い報酬モデリングは、顧客向けや規制環境でのモデル展開において重要となる。VAPOや動的サンプリングによるRLの安定性向上は、イテレーションサイクル短縮に貢献する可能性がある。
- データエンジニア: 厳密なフィルタリング、拡張、専門家による検証を含む構造化されたデータアプローチは、モデル性能向上におけるデータ品質の重要性を再確認させる。これは、より意図的なデータセット開発と検証パイプライン構築の動機付けとなり得る。
- インフラ・運用担当: SRSやFP8最適化を含むハイブリッドインフラアプローチは、トレーニングスループットとハードウェア利用率の大幅な向上を示唆する。ランタイムの動態に基づいて報酬フィードバックを適応させるメカニズムは、異種データパイプライン管理やドメイン間の一貫性維持という課題に直接対応するものである。
Seed-Thinking-v1.5は、ByteDanceのSeed LLM Systemsチーム(Yonghui Wu氏主導、Haibin Lin氏が広報担当)内の協力の成果である。Doubao 1.5 Proなどの先行プロジェクトの知見も活用されている。
研究チームは今後、強化学習技術の改良、特にトレーニング効率と検証不可能なタスクに対する報酬モデリングに注力する計画だ。また、BeyondAIMEのような内部ベンチマークの公開を通じて、推論に焦点を当てたAI研究の広範な進展を促進することを目指している。
ByteDanceのSeed-Thinking-v1.5は、推論AI分野における競争をさらに激化させるとともに、その開発を支えるデータ戦略、強化学習、インフラ技術における新たな標準を示す可能性を秘めている。今後のモデル公開とさらなる研究開発の進展が待たれる。
Sources
- GitHub: ByteDance-Seed/Seed-Thinking-v1.5