

Cerebras Systemsが世界最速を謳うAI推論サービスの開始を発表した。このサービスは、同社が誇るWSE-3プロセッサを搭載したCS-3システムを基盤としており、従来のNVIDIA GPUベースのクラウド推論サービスと比較して、最大20倍の速度向上を実現したと主張している。
Cerebras WSE-3の革新的なアーキテクチャが生み出す圧倒的な性能
Cerebrasの技術革新の核心は、その独自のハードウェアアーキテクチャにある。WSE-3チップは、従来のGPUとは一線を画す設計を採用しており、特に注目すべきは高帯域幅メモリ(HBM)の代わりにSRAMを採用している点だ。この大胆な選択により、WSE-3は21PB/sという驚異的なメモリ帯域幅を実現している。これは、NVIDIAのH200 GPUが提供する4.8TB/sのHBM3e帯域幅を遥かに凌駕する性能だ。
Cerebras CEOのAndrew Feldman氏は、現在のAI業界の状況を「生成AIのダイヤルアップ時代」と表現し、多くのAIアプリケーションがプロンプトに対して顕著な遅延を伴って応答する現状を指摘している。Cerebrasの新サービスは、この状況を一変させる可能性を秘めている。具体的な性能として、Llama 3.1 8Bモデルを16ビット精度で実行した場合に毎秒1,800トークンを生成可能であり、さらに大規模なLlama 3.1 70Bモデルを4台のCS-3アクセラレータに分散して実行した場合でも、毎秒450トークンという高速な生成を実現している。
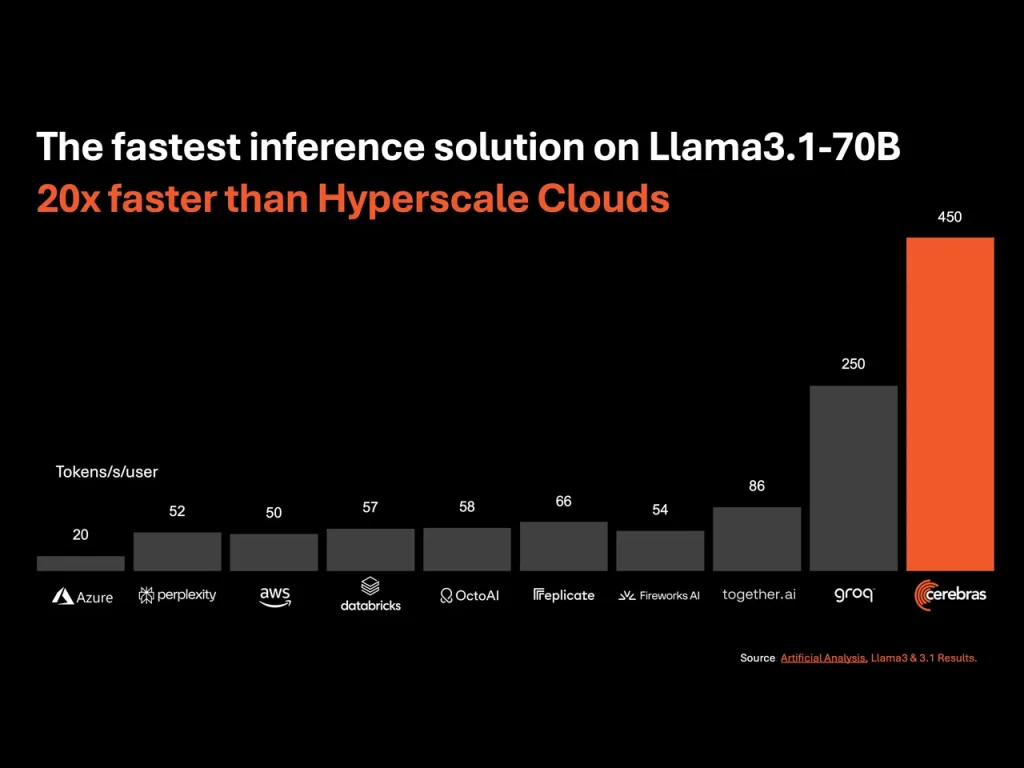
しかし、SRAMの採用には課題もある。WSE-3チップに搭載された44GBという容量は、大規模言語モデル(LLM)の運用には必ずしも十分ではない。Cerebrasはこの課題に対し、複数のCS-3システムにモデルを分散させるパイプラインパラレリズムを採用することで対応している。例えば、140GBのメモリを必要とするLlama 3 70Bモデルの場合、80層のモデル構造を4台のCS-3システムに分散させて処理を行う。この方式では、システム間のデータ転送による遅延が懸念されるが、Cerebrasによれば、ウェハー間の遅延は全体の処理時間の約5%に抑えられているという。
この高速推論能力がもたらす可能性は計り知れない。例えば、複数のモデルを基にしたエージェントアプリケーションの構築や、LLMが複数のステップを踏んで回答を洗練させるプロセスを、ユーザーに気づかれないほどの速さで実行することが可能になる。これにより、AIとのインタラクションがより自然で、よりインテリジェントなものになることが期待される。
Cerebrasは、この推論サービスを3つの階層で提供している:
- Free Tier: ログインすれば誰でも無料でAPIにアクセスできるが、使用量は制限されている実験用階層。
- Developer Tier: 柔軟なサーバーレス・デプロイメント向けに設計されており、Llama 3.1 8Bおよび70Bモデルの価格は、それぞれ100万トークンあたり10セントおよび60セントと、市場の代替品と比較してわずかなコストでAPIエンドポイントをユーザーに提供する。 今後、Cerebrasはさらに多くのモデルのサポートを継続的に展開していく予定とのことだ。
- Enterprise Tier: きめ細かいモデル、カスタム・サービス・レベル契約、専用サポートを提供する階層。 持続的なワークロードに理想的なEnterprise Tierは、Cerebrasが管理するプライベート・クラウド、または顧客のオフィスからCerebras推論にアクセスすることができる。 企業向けの価格は要問い合わせ。
さらに、CerebrasはOpenAIのChat Completions APIとの完全な互換性を確保しており、既存のアプリケーションをわずかな修正でCerebrasのプラットフォームに移行できるようにしている。これは、開発者にとって大きな利点となるだろう。
業界からの反応も肯定的だ。DeepLearning AIの創設者であるAndrew Ng博士は、Cerebrasの高速推論能力が特に複数回のプロンプトを必要とするエージェント型AIワークフローに非常に有用であると評価している。
Cerebrasの挑戦は、AI推論市場に新たな風を吹き込むだけでなく、AI産業全体のパラダイムシフトを促す可能性を秘めている。その革新的なアプローチが、AI技術の発展や応用にどのような影響を与えるか、今後の展開が大いに注目される。
Source
- Cerebras Systems: Cerebras Launches the World’s Fastest AI Inference










コメント