
Compute Express Link(CXL)コンソーシアムは、CXL 3.0仕様を発表し、PCIe 6.0インターフェースのサポート、メモリプーリング、更に複雑なスイッチングおよびファブリック機能への対応といった、数々の新機能を実現した。CXL 3.0では、旧バージョンの仕様との後方互換性を維持しながら、最大2倍の帯域幅をサポートすることが可能になることが最大の特徴だろう。
CXL (Compute Express Link)は、CPUとGPUなどのアクセラレータ、DPUなどのスマートI/Oデバイス、さまざまな種類のDDR4/DDR5や永続メモリとの間にキャッシュコヒーレントインターコネクトを提供するオープンな業界標準規格だ。このインターコネクトにより、CPUは接続されたデバイスと同じメモリ領域で作業できるため、性能と電力効率が向上し、ソフトウェアの複雑さとデータ移動が軽減される。

CXLは、AMD、Arm、NVIDIA、Intelなど、すべての主要チップメーカーが既に採用しており、AMDの近日発売のGenoa CPUとIntelのSapphire RapidsはCXL 1.1をサポートしている。Micronなどの多数のメモリメーカー、ハイパースケーラ、OEM も参加している。
新しいCXL 3.0の仕様は、ようやくこの規格が業界で完全に統一されたことで明るみに出た。昨日、OpenCAPIコンソーシアムは、競合するアクセラレータ用のキャッシュコヒーレントOpenCAPI仕様と、シリアル接続のニアメモリOpen Memory Interface(OMI)仕様をCXLコンソーシアムに移管すると発表した。これにより、今年初めにGen-ZコンソーシアムもCXLに吸収されたため、CXL規格の最後の競争に終止符が打たれたことになる。さらに、CCIX規格は、そのパートナーのうち数社がCXLを採用したため、消滅したようだ。
CXL 2.0は現在PCIe 5.0バス上に乗っているが、CXL 3.0はこれをPCIe 6.0に引き上げ、スループットを2倍の64GT/s(x16接続では最大256GB/sのスループット)としながらも、レイテンシの増加はゼロだと言う。CXL 3.0では、レイテンシを最適化した新しい256バイトフリット形式を採用し、レイテンシを2~5ns短縮することで、従来と同じレイテンシを維持している。
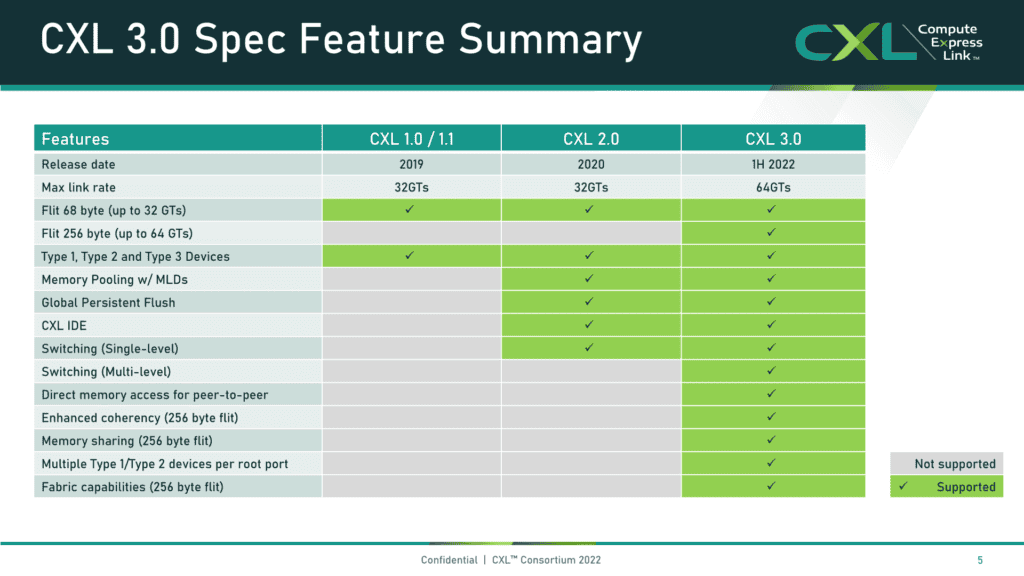
また、接続されたデバイス間のネットワーク的なトポロジーを可能にするマルチレベルスイッチング、メモリ共有、接続されたアクセラレータ間のピアツーピア通信のためのダイレクトメモリアクセス(DMA)などをサポートし、一部のユースケースでCPUオーバーヘッドをなくすなど、注目すべき改良が施されている。
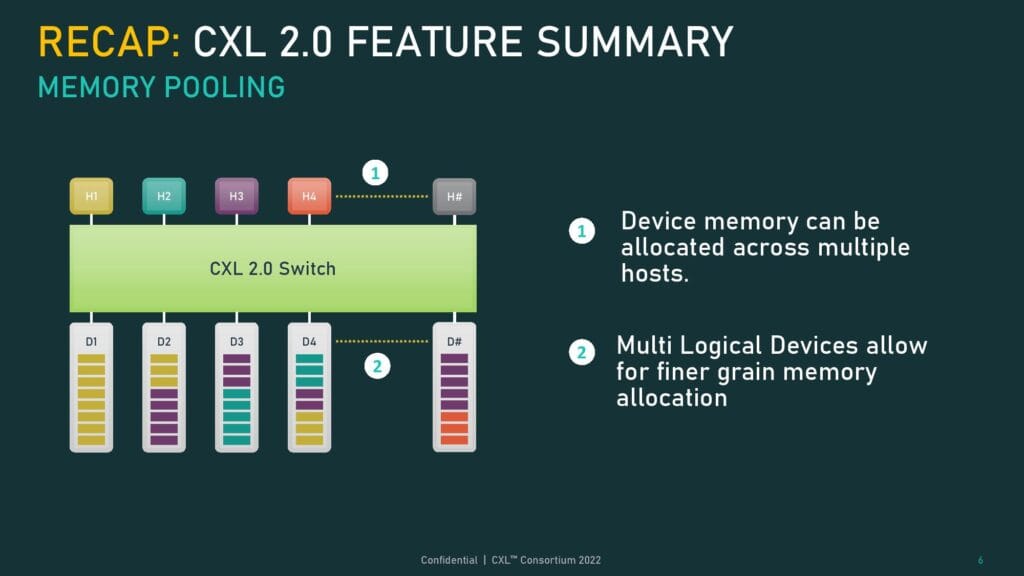
CXL 2.0仕様では、メモリ領域を異なるホストに動的に割り当てたり解除したりするメモリプーリングがサポートされており、1つのストレージデバイスを複数のセグメントに細分化することができたが、各領域は1つのホストにしか割り当てられなかった。CXL 3.0では、ハードウェアコヒーレンシによって複数のホスト間でデータ領域を共有できるメモリ共有が追加された。これは、各ホストが最新の情報を見ることができるように、ハードウェアキャッシュのコヒーレンシを追加したホストキャッシュにデータを配置することで機能する。
CXL 仕様では、デバイスを異なるクラスに分類している。タイプ1デバイスはローカルメモリを持たないアクセラレータ、タイプ2デバイスは独自のメモリを持つアクセラレータ(GPU、FPGA、DDRやHBMを持つASICなど)、タイプ3デバイスはメモリデバイスで構成されている。さらに、CXL は、1 つのホストルートポートでこれらのタイプのデバイスの混在をサポートし、以下で説明するような複雑なトポロジのオプションを大幅に拡張している。
更新された仕様では、接続されたデバイス間の直接ピアツーピア(P2P)メッセージングもサポートし、通信経路からホスト CPU を排除して、オーバーヘッドとレイテンシを低減している。このタイプの接続により、アクセラレータからメモリ、アクセラレータからアクセラレータへの通信に新たなレベルの柔軟性がもたらされる。
CXL仕様では、1つのトポロジー内で複数のスイッチをカスケード接続できるようになったため、接続デバイスの数が増え、ファブリックの複雑さが増し、Spine/Leaf、メッシュ、リングベースのアーキテクチャなど、非ツリーのトポロジーが含まれるようになったのだ。
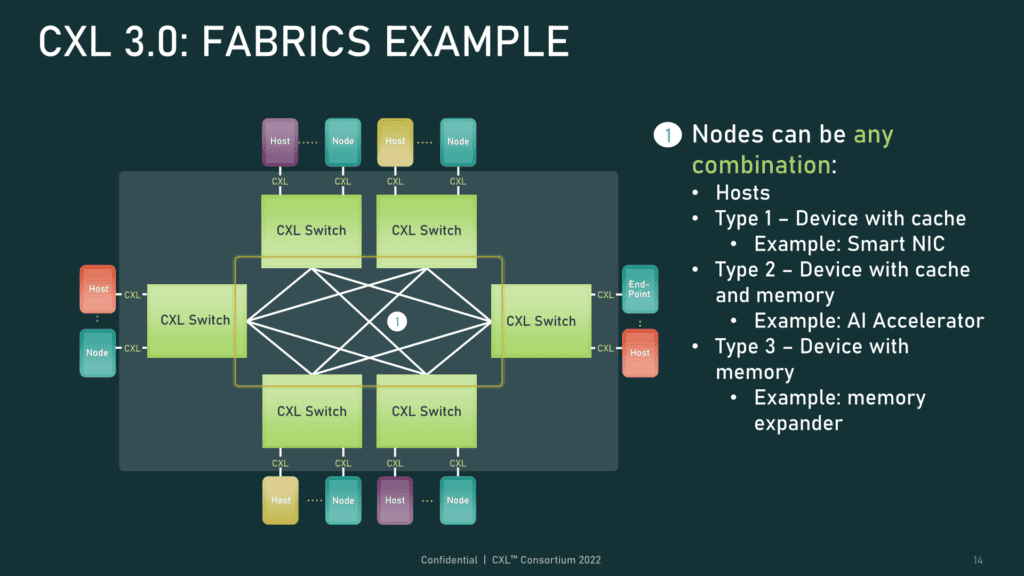
新しいポートベースルーティング(PBR)機能は、最大4,096ノードをサポートするスケーラブルなアドレス指定機構を提供する。各ノードは、既存の3種類のデバイスと、新しいGFAM(Global Fabric Attached Memory)デバイスのいずれかを使用できる。GFAMデバイスは、PBR機構を利用してホスト間のメモリ共有を可能にするメモリデバイスだ。このデバイスは、永続記憶やDRAMなど、異なるタイプのメモリを1つのデバイスで併用することをサポートしている。
新しいCXL仕様では、インターコネクトのユースケースを大幅に拡大し、ラックスケールの大規模な分解システム(おそらくそれ以上)を包含するようになった。当然ながら、この種の機能は、例えばオールフラッシュストレージアプライアンスへの接続など、よりストレージ中心の用途に実現可能かどうかという疑問を投げかけるが、この仕様は、そうした用途にも関心を集め始めているようだ。
また、コンソーシアムでは、次世代サーバで DDR5 のコストを回避するために DDR4 メモリプールを使用することに、メンバーから強い関心が寄せられていると述べている。この方法では、ハイパースケーラは、すでに持っている(そしてそうでなければ廃棄する)DDR4メモリを使用して、安価なDDR4メモリを搭載できないDDR5サーバチップと組み合わせた、柔軟な大規模メモリプールを作成することができる。このような柔軟性は、本日公開される CXL 3.0 仕様の多くの利点のうちの 1 つを強調するものだ。
Source

