
一枚の写真から、その撮影場所を地球規模で特定する――かつては熟練したOSINT(公開情報調査)捜査官や、一部の熱狂的な「GeoGuessr」プレイヤーだけが持ち得た特殊技能であった。しかし今、その能力はオープンソースAIによって民主化されようとしている。
中国の研究チーム(Tencent、復旦大学、清華大学など)によって開発された新たなAIモデル「GeoVista」が、技術コミュニティに衝撃を与えている。このモデルは、画像内の視覚情報を分析するだけでなく、自律的にインターネット検索を行い、情報を照合することで、Googleの「Gemini 2.5 Flash」やOpenAIの「GPT-5」といった最先端の商用クローズドモデルに匹敵する位置特定能力を実証しているのだ。
GeoVistaとは何か:視覚と検索を融合させる「エージェント型AI」
GeoVistaの核心は、単なる画像認識モデルではなく、道具を使用するエージェント型AI(Agentic AI)として設計されている点にある。従来の画像位置特定AIは、学習済みのデータセット内の知識のみに依存していたが、GeoVistaは人間の調査員と同じように「推論」し、「調査」する。
1. 視覚と検索のハイブリッド・アプローチ
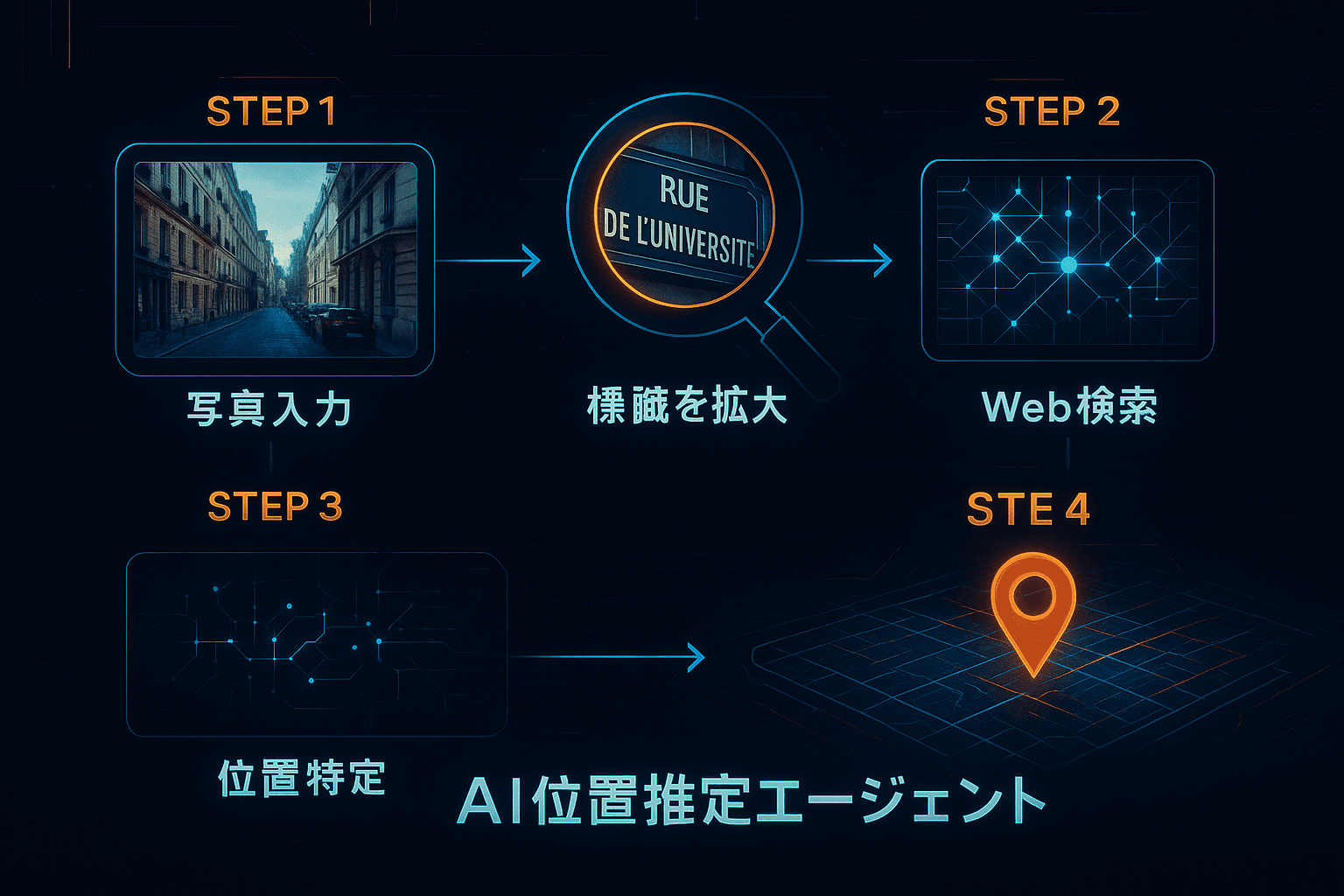
GeoVistaは、画像のピクセル情報だけを見て答えを出すのではない。以下の2つの強力なツールを、AI自身が必要に応じて使い分けることで、驚異的な精度を実現している。
- Crop-and-Zoom(切り出しと拡大):
画像内の看板、植生、建築様式など、位置特定の手がかりとなりそうな領域を自律的に判断し、その部分を拡大(ズーム)して詳細に分析する。これにより、低解像度の全体像では見落としてしまう細かな文字情報や特徴的なパターンを抽出する。 - Web Search(Web検索):
視覚的な手がかり(例:「〇〇という店名」や「特徴的な赤い屋根の教会」)を得ると、AIはGoogle Searchなどの検索エンジンAPIを介して、Tripadvisor、Instagram、Facebook、Pinterest、Wikipediaなどのデータベースへアクセスする。最大10件の検索結果を取得し、仮説の裏付けを行う。
2. 人間の思考プロセスを模倣するループ

論文によると、GeoVistaは「思考(Thought)→行動(Action)→観察(Observation)」というループを繰り返す。
- 初期分析: 画像全体を見て、「アジアのどこかの都市のようだ」と仮説を立てる。
- 行動選択: 「看板の文字が読めないため、ズームツールを使用する」と決定。
- 観察: ズームした画像から店名を読み取る。
- 再行動: 「店名を検索し、都市を特定する」と決定し、ウェブ検索を実行。
- 結論: 検索結果から住所を特定し、最終的な座標を出力する。
この一連のプロセスは、モデルが自律的に制御しており、これが「Mini-o3」やByteDanceの「DeepEyes」といった他のオープンソースモデルと決定的に異なる点である。他モデルが画像操作(ズームなど)に重点を置いているのに対し、GeoVistaは外部知識の能動的なマイニングを統合しているのだ。
Qwen2.5を基盤とした高度な学習戦略
GeoVistaの驚異的なパフォーマンスは、単にツールを与えたから実現したわけではない。その学習プロセスには、近年のAI研究のトレンドである「事後学習(Post-training)」の巧みな戦略が詰め込まれている。ベースモデルには、強力な視覚言語モデルである「Qwen2.5-VL-7B-Instruct」が採用された。
第一段階:コールドスタートSFT(教師あり微調整)
AIにいきなり「道具を使え」と命令しても、適切に使いこなすことはできない。そこで研究チームは、まず「模範的な振る舞い」を教え込むフェーズを設けた。
- 商用モデルによるデータ生成: Seed-1.6-visionなどの高度な商用VLM(視覚言語モデル)を使用し、画像を分析させ、どのような手順でズームや検索を行うべきかという「推論の軌跡(Reasoning Trajectory)」を生成させた。
- パターンの学習: 約2,000件の高品質な推論プロセスを教師データとして学習させることで、GeoVistaは「推論してから行動する」という基本的な作法と、ツールの使用方法を習得した。
アブレーション研究(構成要素を省いて効果を検証する実験)によると、このSFTフェーズを省略すると、モデルは短い回答しか生成できなくなり、ツールを効果的に使用できずにパフォーマンスが崩壊することが確認されている。
第二段階:強化学習(RL)と階層的報酬システム
基本動作を学んだモデルを、さらに熟練の探偵へと進化させたのが、強化学習(Reinforcement Learning)である。ここでは、DeepSeek-V3などでも採用されているGRPO(Group Relative Policy Optimization)という手法が用いられたが、GeoVista独自の工夫として「階層的報酬(Hierarchical Reward)」の導入が挙げられる。
通常の位置特定タスクでは、「正解か不正解か」の二元論になりがちだ。しかし、地理情報は階層構造(国 > 州・省 > 都市)を持つ。
- 国レベルの正解: 低い報酬(1点)
- 州・省レベルの正解: 中程度の報酬(β点)
- 都市レベルの正解: 高い報酬(β²点)
このように、より狭い範囲(詳細な都市名)を特定できた場合に指数関数的に高い報酬を与えることで、AIに対して「だいたいこの辺り」という曖昧な回答で妥協せず、リスクを取ってでもピンポイントな特定を目指すよう動機づけを行った。この強化学習フェーズ(約12,000件のデータを使用)により、都市レベルの特定精度は飛躍的に向上した。
ベンチマーク評価:商用モデルへの肉薄とオープンソースの躍進
GeoVistaの性能を測るために、研究チームは新たな評価セット「GeoBench」を構築した。これは既存のデータセット(OSV-5Mなど)の欠点であった「低解像度」や「簡単すぎるランドマーク(エッフェル塔など)」を排除し、真に推論能力が問われる1,142枚の高解像度画像(写真、パノラマ、衛星画像)で構成されている。

圧倒的な数値実績
論文で示されたデータは、7B(70億パラメータ)クラスのモデルとしては驚異的である。
- 都市レベルの正解率:
- GeoVista-7B: 72.68%
- Gemini 2.5 Flash: 73.29%
- GPT-5: 67.11%
- Mini-o3-7B: 11.30%
特筆すべきは、GeoVistaがパラメータ数が遥かに多いであろうGemini 2.5 Flashに肉薄し、GPT-5(※論文中の比較対象としてのGPT-5)をも一部指標で上回っている点だ。特にパノラマ画像においては79.49%という極めて高い精度を記録している。
距離誤差の中央値
「正解の座標からどれだけ離れていたか」を示すHaversine距離の中央値においても、その精度は際立っている。
- GeoVista-7B: 2.35 km
- Gemini 2.5 Pro: 0.80 km
- Gemini 2.5 Flash: 1.67 km
- GPT-5: 1.86 km
- Qwen2.5-VL-7B(ベースモデル): 2209.82 km
商用最高峰のGemini 2.5 Pro(0.8km)には及ばないものの、ベースモデル単体では2000km以上離れていた誤差を、エージェント機能と強化学習によって2.35kmまで縮めたことは、技術的なブレイクスルーと言える。これは、検索ツールを使えない他のオープンソースモデル(DeepEyes-7Bは5174km)と比較すると、まさに次元の違う性能だ。
GeoBench:「解ける画像」だけを厳選した新基準
GeoVistaの評価に使われた「GeoBench」自体の設計思想も興味深い。研究チームは、インターネット上の画像が無作為に位置特定できるわけではないことを理解している。
- 非特定画像の除外: クローズアップされた料理、一般的な屋内、特徴のない自然風景など、視覚的な手がかりが皆無な画像は「特定不可能」として除外された。
- 有名ランドマークの除外: 自由の女神やピラミッドのような、学習データに含まれているだけで記憶から回答できてしまう(推論を必要としない)画像も除外された。
つまり、GeoBenchで高得点を出すということは、AIが「記憶」に頼るのではなく、看板の言語、道路の標識、植物の分布、建築様式といった断片的な情報を組み合わせ、論理的に場所を導き出していることを証明している。
プライバシーの終焉とセキュリティのパラダイムシフト
GeoVistaの登場は、テクノロジーの進歩として称賛されるべき一方で、個人のプライバシーにとっては極めて重大な脅威となる可能性を秘めている。
1. 「誰でも」使える監視能力
これまで、ここまでの精度を持つ位置特定技術は、Googleのような巨大テック企業か、あるいは国家機関の内部に留保されていた。しかし、GeoVistaはオープンソースであり、重み(Weights)もコードも公開されている。これは、ある程度の技術力を持つ個人や組織であれば、独自の「全世界監視システム」をローカル環境で構築できることを意味する。
2. SNS投稿のリスク再考
「背景に何も映っていないから大丈夫」というこれまでの常識は通用しなくなる。GeoVistaのようなAIは、背景のわずかな植生や、窓に反射した微細な情報、あるいは遠くに見える送電線の形状などから地域を絞り込み、ウェブ上の膨大なデータベースと照合して、撮影場所を数キロメートル圏内、あるいはピンポイントで特定する。
3. Google検索への示唆
Googleなどの検索プラットフォームは、今後こうした「AIによる実世界情報の解像度向上」をどのように扱うかが問われる。AIが生成した地理情報メタデータの信頼性をどう評価するか、あるいはプライバシー侵害に繋がるようなツールの拡散をどう制御するかは、SEOやコンテンツポリシーの観点からも大きな議論となるだろう。
オープンソースAIの新たな地平
GeoVistaは、オープンソースの小規模モデル(7B)であっても、適切なツール(検索エンジン)と高度な学習戦略(SFT+RL)を組み合わせることで、巨大な商用モデルと互角に戦えることを証明した。
これは「モデルの巨大化」だけがAIの進化の道ではないことを示唆している。「推論能力」と「ツール使用能力」の強化こそが、次世代のAIエージェントの鍵となるだろう。しかし同時に、我々は「どこにいても居場所を特定される」という新たな現実に対し、デジタルフットプリントの管理をより一層厳格に行う必要に迫られている。
論文
参考文献