
近年、脳活動から人が見ている画像や映像をAIを用いて再構成する技術が大きな注目を集めている。人間のfMRI(機能的磁気共鳴画像法)データと生成AIを用いた研究が主流である中、イギリスのユニバーシティ・カレッジ・ロンドン(UCL)のJoel Bauer博士を中心とする研究チームは、マウスの一次視覚野における単一細胞レベルの神経活動のみから、視聴していた10秒間の自然動画を高品質に再構成することに成功した。
2026年3月に学術誌『eLife』に掲載されたこの研究は、先進的な「動的神経符号化モデル(Dynamic Neural Encoding Model: DNEM)」とカルシウムイメージング技術を組み合わせることで、過去の静止画再構成を大きく凌駕する「ピクセル相関0.57」という驚異的な精度を達成することに成功したのだ。
fMRIから単一細胞レベルへ:脳情報デコーディングの新たな地平
脳波や血流の変化から、脳内で処理されている視覚情報を読み解く「脳情報デコーディング」は、神経科学における究極の目標の一つである。これまで、人間を対象とした研究では主にfMRIが用いられ、潜在拡散モデル(Latent Diffusion Model)などの強力な生成AIを組み合わせることで、脳活動から意味的に類似した画像を再構成するアプローチが大きな成功を収めてきた。
しかし、fMRIは空間的・時間的な解像度が根本的に低く、数千から数万のニューロンの活動の平均値(ボクセル)を秒単位で観察しているに過ぎない。さらに、強力な事前学習済み画像生成モデルに依存する近年の手法は、脳が実際に表現している低次な視覚情報というよりも、AIが持つ一般的な画像統計量に基づいた「もっともらしい意味の補完」を行ってしまうリスクを孕んでいる。つまり、脳が実際に「見ていない」ものであっても、AIが文脈から推測して映像を作り出してしまう可能性があるのだ。
そこでUCLの研究チームは、より直接的で高い時空間解像度を持つアプローチを採用した。それが、マウスを用いた単一細胞レベルでの神経活動記録である。「2光子カルシウムイメージング(Two-photon calcium imaging)」と呼ばれる高度な顕微鏡技術を用いることで、研究チームはマウスの一次視覚野(V1)に存在する約8000個もの個別ニューロンの活動を、細胞内のカルシウムイオン濃度変化に伴う蛍光として極めて高い精度で計測した。この単一細胞解像度のデータこそが、外部のAIモデルによる過剰な意味的補完に頼らず、脳の純粋な視覚表現を抽出するための強固な基盤となったのである。
ブランク画面から映像を彫り出す:「動的神経符号化モデル(DNEM)」と反復最適化
この研究の核心は、神経活動データから直接映像を出力する(デコードする)ネットワークを構築するのではなく、映像から神経活動を予測する「エンコード(符号化)」モデルを逆転させるというアプローチにある。
研究チームは、大規模なマウスの視覚皮質活動を予測する国際コンペティション「Sensorium 2023」で優勝した、最先端の「動的神経符号化モデル(DNEM: Dynamic Neural Encoding Model)」を採用した。この深層学習モデルは、入力された動画フレームのピクセル情報だけでなく、マウスの「瞳孔の位置」「瞳孔の直径(覚醒度と強く相関する)」、そして「走る速度」といった行動データをも同時に加味して、個々のニューロンがどのように発火するかを高精度に予測することができる。覚醒しているマウスの一次視覚野の活動は、網膜に映る映像だけでなく、自身の身体的な動きや覚醒状態に強く影響を受ける(モジュレーションされる)ため、これらの行動データを統合できるDNEMの使用は極めて理にかなっている。
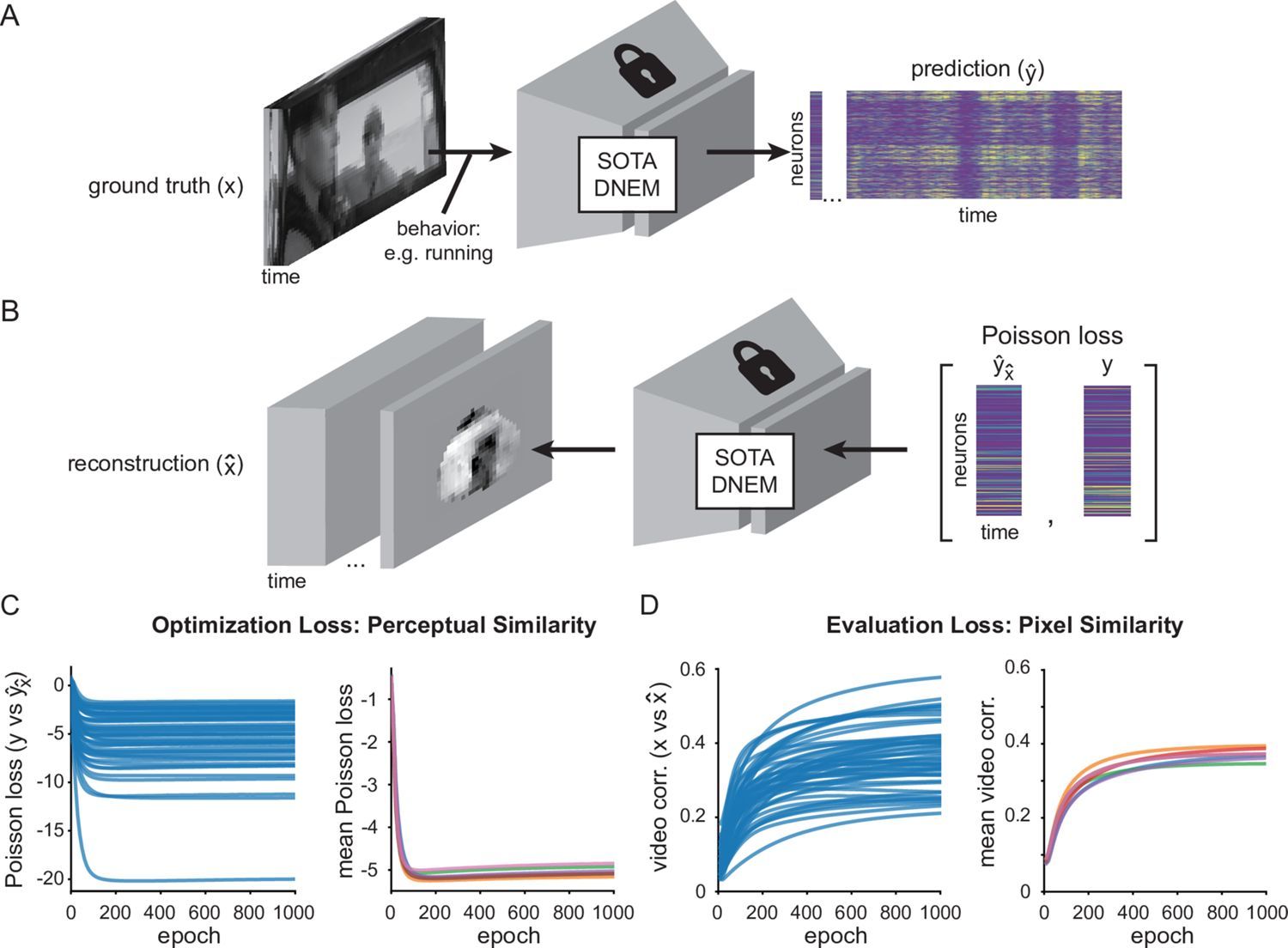
では、この予測用エンコードモデルを使って、どのように元の動画を「再構成」するのだろうか。そのプロセスは、まるで真っ白な大理石から彫刻を削り出すかのように洗練されている。
- 初期化: まず、モデルの入力として「均一なグレー(灰色)のノイズ動画」を与える。
- 予測と誤差の計算: DNEMは、このグレーの動画と実際の行動データから、32フレーム(約1.06秒)のウィンドウごとに予測される神経活動を出力する。当然、実際にマウスが見ていた自然動画に対する実際の神経活動(グラウンドトゥルース)とは大きなズレ(誤差)が生じる。
- バックプロパゲーションによる最適化: ここで、予測された活動と実際の活動との間の誤差(ポアソン負の対数尤度損失: Poisson negative log-likelihood loss)を計算する。そして、その誤差を最小化する方向へと、AIのネットワークを通じて勾配を逆伝播(バックプロパゲーション)させる。ただし、一般的なAIの学習のように「モデル内部の重み」を更新するのではなく、モデルの重みは完全に固定したまま、「入力された動画の各ピクセルの輝度」を勾配降下法(Gradient Descent)を用いて微調整していく。
- 反復: このプロセスを動画全体に対してスライドさせながら、1000エポック(反復サイクル)にわたって繰り返す。
計算を重ねるごとに、最初はただのグレーだった画面上のピクセル値が更新され続け、最終的に「予測される神経活動が、実際に計測された神経活動と最も一致するような動画」が浮かび上がってくる。これが、神経活動という暗号から元の映像を逆算的に復元する巧妙なメカニズムである。
約8000個のニューロンが描き出す高精細な10秒間と成功の鍵
この反復最適化手法を用いて、研究チームはマウスが視聴していた10秒間の自然動画クリップ(様々な風景や動物の映像)を、1秒間に30フレーム(30Hz)という滑らかな時間分解能で再構成することに成功した。再構成された動画は、元の動画の空間的な構造(物体の輪郭やコントラスト)だけでなく、動きなどの時間的ダイナミクスをも見事に捉えていた。
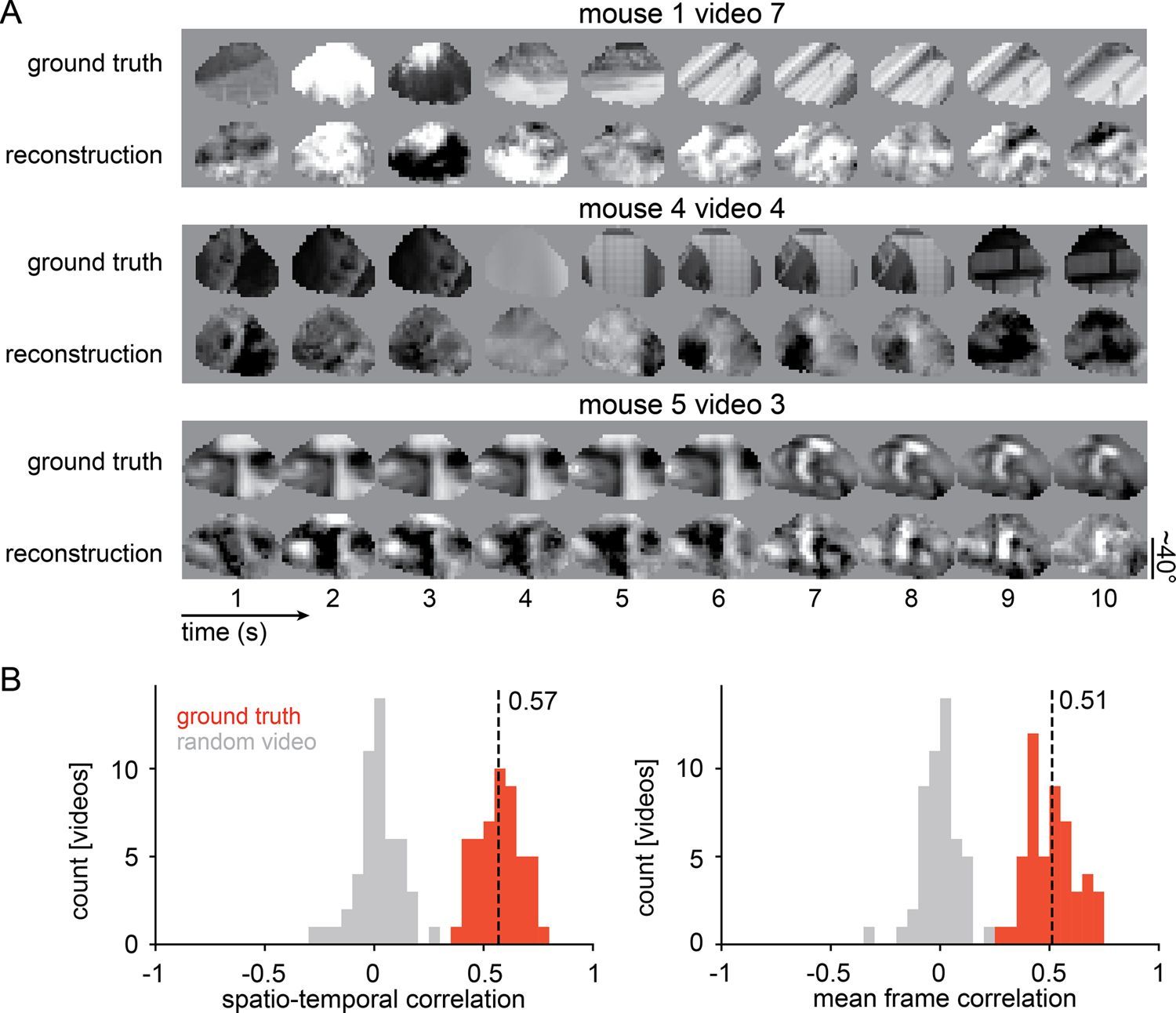
精度を定量的に評価するため、元の動画と再構成された動画の間で全ピクセルの相関(ピアソンの相関係数)を測定したところ、その値は平均「0.57」に達した。過去に行われた、覚醒状態のマウスからの「静止画」の単一試行による再構成実験でのピクセル相関が約0.24であったことを考慮すると、時間的な変化を伴う動画においてこれほどの数値を叩き出したことは、目覚ましい飛躍であると言える。
論文では、この高品質な動画再構成を実現する上で、以下の2つの決定的な要因があったと結論づけている。
1. 圧倒的なニューロンのデータ量(Population Size)
一つ目は、観測対象となったニューロンの数である。研究チームは、約630マイクロメートル四方の視野(マウス一次視覚野の約5分の1に相当)から約8000個のニューロンの活動を記録した。コンピュータ上のシミュレーションでこのニューロン数を人為的に削る「アブレーション実験」を行ったところ、観測するニューロン数を50%(約4000個)に減らすと再構成の相関スコアは約10%低下し、75%(約2000個)に減らすとスコアは約25%も急落することが判明した。つまり、視覚野における高解像度の情報表現を正確に読み解くには、限られた少数の細胞ではなく、大規模な神経集団全体の活動(ポピュレーション・コーディング)を網羅的に捉えることが絶対条件であることを示している。
2. モデルアンサンブル(Model Ensembling)の効果
二つ目の鍵は、機械学習における「アンサンブル学習」の導入である。単一のDNEMモデルでピクセルの最適化を行った場合、再構成された動画には空間的・時間的に高周波のノイズ(細かいちらつきやザラつき)が生じやすかった。そこで研究チームは、異なる学習データセットの分割で訓練させた7つの独立したDNEMモデルを用意し、それぞれが独自に導き出した動画再構成の結果を平均化した。この手法により、個々のモデルが持つ特有のノイズが相殺され、最終的な再構成のパフォーマンス(動画の相関)は単一モデルの場合と比較して最大28.0%も劇的に向上したのである。
人間の「知覚の謎」に迫る:脳内の映像は現実と完全に一致しない?
この卓越した動画再構成技術は、単に「動物が見ているものを覗き見する」ための面白ツールに留まらない。神経科学における根本的な問い、すなわち「私たちの脳は、現実の物理世界をカメラのようにありのままに捉えているのか?」という命題を探求するための、強力な検証基盤となる。
研究を主導したJoel Bauer博士は、本研究の意義について次のように深く洞察している。
「私たちは、頭の中に世界を完璧に表現しているわけではありません。視覚の処理パイプラインは、情報を修正するような形で私たちの内的表現を歪め、ゆがませます。現実と脳内表現の間のこのズレは、必ずしも『エラー』ではなく、私たちの心が感覚情報をどのように解釈し、拡張しているかを反映する『機能(Feature)』なのです。私たちは、これが脳内でどのように起こるのかを探求したいと考えています」
実際、人工的に生成されたガウシアンノイズ(砂嵐のような映像)やドリフトグレーティング(一定方向に動く縞模様)を用いた限界検証テストでは、特定の高い空間周波数(細かすぎる模様)や高い時間周波数(速すぎる動き)の映像は、モデルが完全に機能している理想的なシミュレーション上であっても再構成が困難であることが分かった。これは、マウスの網膜や視覚皮質が持つ根本的な解像度や処理速度の限界(視力やフリッカー融合頻度)をそのまま反映していると考えられる。
しかし、さらに重要なのは、脳の高度な情報処理プロセスに起因する能動的な「歪み」である。例えば、神経科学には「予測符号化(Predictive Coding)」という有力なパラダイムがある。これは、脳が常に外部世界からの入力を過去の経験から予測しており、実際の入力と予測との間に生じた「予測誤差」のみを上位の脳領域へ伝達するというモデルである。もしこのメカニズムが働いているとすれば、脳活動から再構成された映像においては、見慣れた予想通りの風景は省略され、突発的な動きや予期せぬ物体(予測誤差が大きい部分)の方が、よりシャープに、あるいはコントラスト高く浮かび上がる可能性がある。
また、「知覚学習(Perceptual Learning)」や「選択的注意(Selective Attention)」といった現象も、神経表現をダイナミックに変化させる。特定の視覚的特徴を見分ける訓練を受けたマウスや、特定の物体に強く注意を向けているマウスの脳活動から動画を再構成すれば、客観的な現実の映像とは異なり、その「注目している特徴」だけが強調された、主観的なバイアスのかかった映像が抽出されるはずである。
本研究で開発された手法は、実際の入力動画と、脳活動から再構成された動画の間の「ズレ(Error map)」をピクセル単位で空間的に可視化することを可能にした。このズレを丹念に解析することで、上述のような脳のトップダウン処理や注意のメカニズムが、視覚情報をどのように能動的に「編集」しているかを、客観的なデータとして検証できる道が開かれたのである。
今後の展望と脳科学の未来
UCLの研究チームによるこの画期的な成果は、動物モデルを用いた視覚系・知覚系の研究に新しい基準をもたらした。人間のfMRIデータと生成AIを用いた研究が、脳内の「意味的なコンセプト」を大まかに再構成することに長けているとすれば、マウスの単一細胞レベルのカルシウムイメージングを用いた本手法は、「知覚の物理学的・生理学的な再構成」において他の追随を許さない圧倒的な解像度と忠実性を誇る。
今後の展望として、研究チームは再構成のさらなる解像度向上と、網羅する視覚領域の拡大を目指している。マウスの視力限界(約0.5サイクル/度)に迫る極細密な解像度を達成するためには、より高密度かつ広範囲にまたがるニューロン集団を同時に記録できる、次世代のデータセットとイメージング技術の構築が必要となるだろう。
「人間が見ている世界」と「マウスが見ている世界」は決して同一ではない。しかし、眼球から入った無機質な光の粒子が電気信号に変換され、脳という暗黒の空間でどのようにして「鮮やかで意味のある映像」として再構築されるのか、その根源的なメカニズムの多くは哺乳類の間で共通している。本研究が切り拓いた技術は、自閉症スペクトラムや統合失調症など、知覚の変容を伴う精神疾患の基礎的な病態解明や、より人間の神経処理機構に近い高度なブレイン・マシン・インターフェース(BMI)の開発など、広範な科学的・医学的応用に直結する可能性を秘めている。
客観的な現実の単なるコピーではない、脳が生存のために独自に編み出した「歪みという名の最適化機能」の全貌が、動画という直感的な形で解き明かされる日は、そう遠くないかもしれない。
論文
参考文献
- EurekAlert!: Movies reconstructed from mouse brain activity

