
Wikimedia財団は、AIモデル訓練のためのデータ収集ボットによるアクセス急増で、Wikimedia Commonsのインフラに深刻な負荷がかかっていると警鐘を鳴らした。2024年初頭からマルチメディアコンテンツのダウンロード帯域幅は50%も増加し、オープンな知識共有プラットフォームの持続可能性が脅かされている。
AIクローラーがWikimedia Commonsを直撃、帯域幅50%増の衝撃
Wikimedia財団が発表したところによると、同財団が運営するオープンなメディアファイルリポジトリ「Wikimedia Commons」において、AIモデル訓練を目的とした自動化プログラム(クローラー、ボット)によるデータ収集活動が急増しているとのことだ。この結果、特に画像や動画などのマルチメディアコンテンツのダウンロードに使われるネットワーク帯域幅が、2024年1月以降わずか数ヶ月で50%も増加するという異常事態が発生しているのである。
このトラフィック増加の主因は人間によるアクセス増ではなく、大規模言語モデル(LLM)をはじめとするAIの「食欲」を満たすために、Commons上の膨大なデータを機械的に収集しようとするAIクローラーによるものである。Wikimedia財団自身も、「人間のユーザーによる関心の高まりではなく、大部分が自動化プログラムによるもの」と分析している。
なぜCommonsが狙われるのか? 1億4400万点のオープンメディアデータ
Wikimedia Commonsは、WikipediaをはじめとするWikimediaプロジェクトで使用される画像、音声、動画などのメディアファイルを一元的に集約・管理するリポジトリである。特筆すべきは、ここに収録されている1億4400万点以上(2024年6月時点、Wikimedia Commonsブログより)のファイルが、クリエイティブ・コモンズ・ライセンスなどのオープンライセンス下、あるいはパブリックドメインとして提供されており、比較的自由な再利用が可能である点だ。
この「自由」で「大規模」なデータセットは、AI、特に画像生成AIやマルチモーダルAIの訓練データとして極めて魅力的なものとなる。AI開発企業は、モデルの性能向上のために、質の高い、多様なデータを大量に必要としており、Commonsはその格好のターゲットとなっているのだ。検索エンジンの結果表示や学術研究、教育目的など、これまでも様々な形で活用されてきたCommonsのコンテンツが、AI時代において新たな、そして桁違いの需要に直面している。
Jimmy Carter氏死去で露呈した「隠れた負荷」
AIクローラーによる負荷増大が、具体的にどのような問題を引き起こすのか。Wikimedia財団は、2024年12月にJimmy Carter元米大統領が死去した際の事例を挙げて説明している。
Carter氏の死去を受け、英語版Wikipediaの同氏のページには1日で280万ビューを超えるアクセスが集中した。これは異例のアクセス数ではあったが、財団のインフラはこれ自体には十分対応可能であった。しかし問題は、同時に多くのユーザーがWikimedia CommonsにホストされていたCarter氏とRonald Reagan氏による1980年の大統領討論会の動画(約1.5時間)を視聴したことで発生した。
この動画再生によるトラフィック急増は、Wikimedia全体のネットワークトラフィックを通常の2倍に押し上げ、一部のインターネット接続帯域を約1時間にわたって完全に使い果たしてしまった。結果として、一部のユーザーはページの読み込み速度が著しく低下するなどの影響を受けた。
財団のサイト信頼性エンジニアリング(SRE)チームは迅速に対応し、トラフィック経路を変更することで輻輳(ふくそう:ネットワーク回線が混雑すること)を解消したが、この一件はより深刻な問題を浮き彫りにした。それは、平常時のベースラインとなる帯域幅が、すでにAIクローラーによる大規模なメディアファイル収集によって著しく消費されていたという事実である。Wikimedia Commonsブログのグラフが示すように、マルチメディアコンテンツのベースライン帯域需要は2024年初頭から右肩上がりで増加しており、これが突発的な高トラフィックイベントへの対応余力を奪っていたのである。
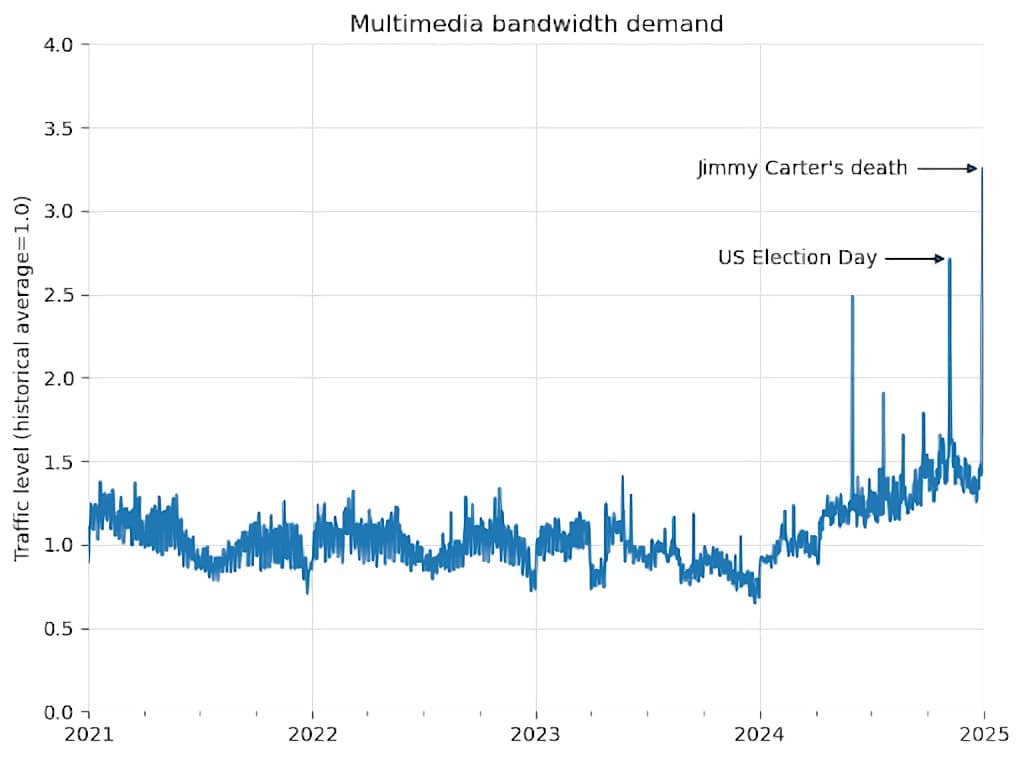
「我々のインフラは、関心の高いイベント発生時の人間による急激なトラフィック増に対応できるよう構築されている。しかし、スクレイパーボットによって生成されるトラフィック量は前例がなく、増大するリスクとコストをもたらしている」と、Wikimedia財団は述べている。
ボットトラフィックの高コスト構造:キャッシュをすり抜ける「非効率な訪問者」
AIクローラーによる負荷は、単に量が多いだけでなく、質的にもインフラにとって「高くつく」ものであることが指摘されている。Wikimedia財団は、コンテンツ配信を高速化するために、世界中にデータセンターを配置し、キャッシュシステムを活用している。頻繁にアクセスされる人気のある記事やファイルは、ユーザーに近いデータセンターに一時保存(キャッシュ)され、素早く配信される。一方、あまりアクセスされないマイナーなコンテンツは、キャッシュされておらず、「コアデータセンター」と呼ばれる中心的なサーバーから直接データを取得する必要がある。このコアデータセンターへのアクセスは、キャッシュからの配信に比べてリソース消費量が大きく、コストが高い。
問題は、人間のユーザーが特定の話題や人気コンテンツにアクセスが集中する傾向があるのに対し、AIクローラーは網羅的なデータ収集を目的として、人気のないページやファイルも含めて「バルク読み込み」を行う点にある。これにより、クローラーからのリクエストはキャッシュにヒットせず、コストの高いコアデータセンターへ直接アクセスする割合が人間よりも格段に高くなるのである。
Wikimedia財団がシステム移行中に実施した分析によると、コアデータセンターに到達するリクエストのうち、リソース消費量が特に大きい「高コスト」なトラフィックの少なくとも65%がボットによるものであった。これは、ボットによる総ページビュー数が全体の約35%に過ぎないことを考えると、極めて不均衡な数字である。つまり、ボットによる1リクエストあたりのインフラコストは、人間のリクエストよりもはるかに高く、その積み重ねが財団の負担を増大させている。
ルール無視のクローラーとSREチームの攻防
問題をさらに複雑にしているのが、一部のAIクローラーがWebサイト運営者が定めるアクセスルールを無視している点である。Webサイトがクローラーに対してアクセスを許可する範囲を指定する「robots.txt」ファイルを無視したり、通常のWebブラウザからのアクセスであるかのように見せかけるためにユーザーエージェント情報(※)を偽装したりするケースが報告されている。
※ユーザーエージェント(User Agent):Webサーバーに対して、アクセスしているソフトウェア(ブラウザの種類やバージョン、OSなど)を伝える識別情報。
さらに悪質なケースでは、アクセス元のIPアドレスを一般家庭用のものに偽装したり、多数のIPアドレスを使い分けたりして、アクセス制限やブロックを回避しようとするクローラーも存在する。このような行為が横行しているため、個人の開発者でさえ自身のコードリポジトリを守るために抜本的な対策を講じざるを得なくなっている状況にも言及している。
こうした状況下で、Wikimedia財団のSREチームは、過剰なトラフィックを制限したり、サービス停止につながるようなアクセス急増を緩和したりするために、常に防御的な対応を強いられている。これは、本来、Wikimediaプロジェクトの貢献者やユーザーをサポートしたり、システムの改善に費やすべき貴重な時間とリソースを奪う行為である。さらに、クローラーの標的はコンテンツページだけでなく、Wikimediaのコードレビュープラットフォームやバグ追跡システムといった開発インフラにまで及んでおり、問題は深刻化している。
オープンソース界全体に広がるAIスクレイピング問題
Wikimediaが直面している問題は、決して孤立したものではなく、オープンソースソフトウェア(FOSS)コミュニティや、広くインターネット全体で観測されている現象である。
- Fedora: Linuxディストリビューションの一つであるFedoraのプロジェクト管理リポジトリ「Pagure」は、同様のスクレイピング問題を受けてブラジルからの全トラフィックをブロックする措置を取った。
- GNOME: デスクトップ環境GNOMEのGitLabインスタンスは、過剰なボットアクセスをフィルタリングするためにProof-of-Work(計算問題を解かせることでボットを排除する仕組み)を導入した。
- Read the Docs: ソフトウェアドキュメンテーションホスティングサービスRead the Docsは、AIクローラーをブロックすることで帯域幅コストを劇的に削減した。
- Curl: ファイル転送ツールCurlの開発者Daniel Stenberg氏は、AIによって自動生成された偽のバグレポートが開発者の時間を浪費している問題を指摘している。
- SourceHut: ソフトウェア開発プラットフォームSourceHutのDrew DeVault氏は、ボットがgitのログのような、人間が必要とする範囲をはるかに超えるエンドポイントを執拗に叩いている状況をブログで訴えている。
- 個人開発者: エンジニアのGergely Orosz氏も、Meta社などのAIスクレイパーによって自身のプロジェクトの帯域幅需要が急増したと不満を述べている。
これらの事例は、AI開発のためのデータ収集活動が、その基盤となっているオープンな情報リソースや開発コミュニティ自身の持続可能性を脅かしかねないという、構造的な問題を示唆している。対策として、Proof-of-Work、応答を意図的に遅らせる「ターピット」、協調的なクローラーブロックリスト(”ai.robots.txt”など)、Cloudflare社の「AI Labyrinth」のような商用ツールなどが試みられているが、根本的な解決には至っていないのが現状である。
Wikimediaの挑戦:「インフラは無料ではない」WE5イニシアチブ始動
Wikimedia財団は、この危機的な状況に対し、「知識をサービスとして」提供する重要性を認識しつつも、「我々のコンテンツは無料だが、我々のインフラは無料ではない」という明確なメッセージを発している。
この問題に体系的に取り組むため、財団は次期会計年度の重点施策として「WE5: Responsible Use of Infrastructure(インフラの責任ある利用)」と題した新たなイニシアチブを立ち上げた。このイニシアチブの下で、以下のような問いに取り組むとしている。
- 自動的なコンテンツ利用に対して、持続可能な境界線をどのように設定するか?
- 開発者や再利用者を、よりリソース消費の少ない、推奨されるアクセスチャネルへとどのように誘導するか?
- 責任あるコンテンツ再利用を奨励するために、どのようなガイダンスが必要か?
目指すのは、オープンな知識共有という使命を維持しつつ、商業的なAI開発を含む外部からのアクセスを持続可能な形で受け入れるための、健全なバランスを再構築することである。
オープンな知識共有の未来は? AI開発者との連携が鍵
今回のWikimediaの発表は、オープンな知識リポジトリと商業的なAI開発という、二つの世界の間に存在する緊張関係を浮き彫りにした。多くのAI企業が、モデル訓練のためにWikimedia Commonsのようなオープンなリソースに依存しながら、その基盤となるインフラの維持コストを負担していないという現状がある。この「フリーライド」とも言える状況が、コミュニティによって運営されるプラットフォームの持続可能性を脅かしている。
根本的な解決のためには、AI開発者とリソース提供者との間での、より建設的な対話と協力が不可欠である。考えられる方策としては、AI訓練用途に特化したAPIの提供、インフラ維持コストの分担、より効率的なアクセスパターンの確立などが挙げられるだろう。
このような実践的な協力体制が構築されなければ、AIの進歩を支えてきたオープンなプラットフォーム自体が、信頼性のあるサービスを提供し続けることが困難になる可能性がある。Wikimediaが鳴らす警鐘は明確である。「アクセスの自由は、結果に対する責任からの自由を意味しない」。オープンな知識共有の未来を守るためには、AI開発者を含むすべてのステークホルダーによる、責任ある行動と協力が求められている。
Sources
- Wikimedia Commons: How crawlers impact the operations of the Wikimedia projects

