

UALink Consortiumは、AIアクセラレータ間の高速・低遅延接続を実現する次世代AIワークロード向けの高速インターコネクト技術「Ultra Accelerator Link 200G 1.0」(UALink 200G 1.0)の仕様を正式に発表した。最大1,024基のアクセラレータ接続を視野に入れ、NVIDIAの独占的なNVLink技術に対抗する選択肢として、AMD、Intel、Google、Microsoftなど業界大手企業が参画する新技術として注目を集めている。
UALink 200G 1.0 仕様、ついに公開 – AI接続の新時代へ
AI(人工知能)とHPC(高性能コンピューティング)のワークロードが急速に進化し、大規模化する中で、アクセラレータ(GPUなど)間の効率的な接続技術は、システム全体の性能を左右する重要な要素となっている。これまで、この分野ではNVIDIAの独自技術であるNVLinkが市場をリードしてきた。しかし、特定ベンダーへの依存やコスト、エコシステムの閉鎖性といった課題も指摘されていた。
このような状況を打破すべく、2024年5月に設立されたUALink Consortium(UAC)は、オープンスタンダードに基づく新たなインターコネクト技術の開発を進めてきた。そして今回、その最初の成果として「Ultra Accelerator Link 200G 1.0」(UALink 200G 1.0)仕様が公開されたのだ。仕様書はUALink Consortiumの公式サイトから誰でもダウンロード可能であり、オープンな標準化への強い意志を示している。
オープン標準が目指すもの:NVLinkへの挑戦とエコシステム構築
UALink Consortiumには、AMD、Intelといった主要なプロセッサ・アクセラレータベンダーに加え、AWS、Google、Meta、Microsoftといったハイパースケーラー、さらにBroadcom、Cisco、HPE、Dell(Dell’Oro Groupのコメントより示唆)、Astera Labs、Marvell、Synopsysなど、半導体、ネットワーク機器、システムインテグレーターに至るまで、幅広い業界プレーヤーが名を連ねている(Appleの参加も一部報道で見られるが、公式発表の参加企業リストには含まれていない)。
彼らがUALinkを推進する背景には、いくつかの共通した狙いがある。
- NVIDIAへの対抗軸形成: NVIDIAはGPU市場だけでなく、NVLinkを用いたインターコネクト技術でも高いシェアを誇り、ネットワーク関連事業で年間130億ドル以上(2024年度)を売り上げている。UALinkは、これに対抗するオープンで低コストな代替技術を提供し、市場の競争を促進することを目指す。
- コスト削減と選択肢の多様化: 独自技術であるNVLinkは、導入コストが高くなる傾向がある。オープン標準であるUALinkは、より多くのベンダーが対応製品を開発・提供しやすくなるため、価格競争が働き、結果としてユーザーのTCO(総所有コスト)削減に繋がると期待される。また、ユーザーは特定のベンダーに縛られることなく、複数のベンダーから最適なアクセラレータやスイッチを選択できるようになる。
- エコシステムの構築: オープンな仕様に基づき、多様な企業が相互運用可能な製品(アクセラレータ、スイッチ、ケーブルなど)を開発することで、より健全で活発なエコシステムの構築を目指す。これは、技術革新を加速させ、ユーザーにとってもより多くの選択肢と柔軟性をもたらす。
- ハイパースケーラーの要求: GoogleやMicrosoftといった大規模データセンターを運用する企業は、自社のインフラにおける特定の課題(低遅延、低消費電力、拡張性など)に対応できる、よりオープンで制御可能な技術を求めている。UALinkの開発には、こうしたハイパースケーラーの要求も反映されている。
UALink ConsortiumのボードチェアであるKurtis Bowman氏は、「AIコンピューティングの需要が高まる中、次世代AI/MLアプリケーションを市場に投入するための不可欠なオープン業界標準技術を提供できることを嬉しく思う」と述べている。
主な技術仕様:高速・低遅延・高効率を実現するテクノロジー
UALink 200G 1.0仕様は、AIおよびHPCワークロードに最適化された、野心的な技術目標を掲げている。その主な特徴を見ていこう。
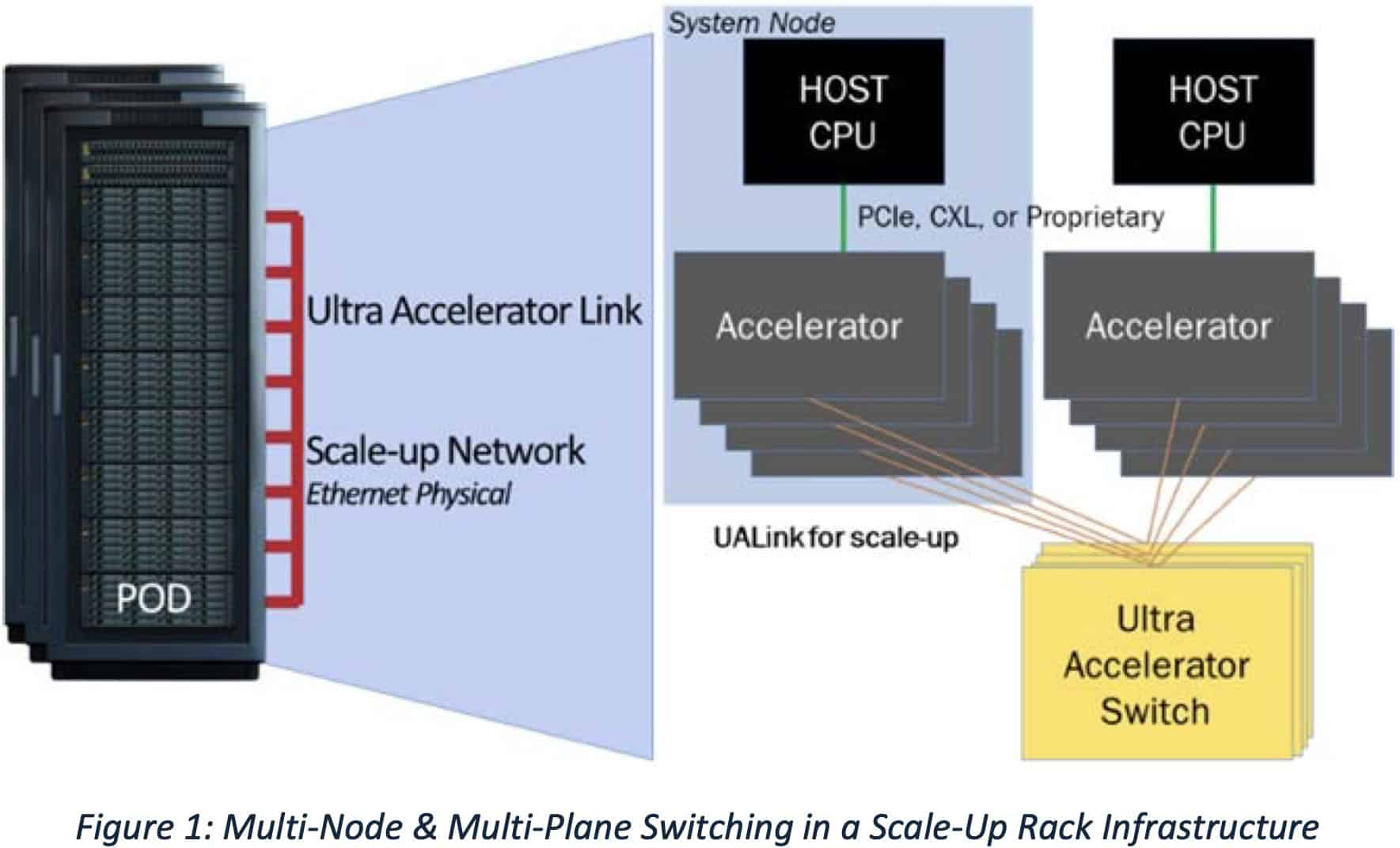
圧倒的な接続規模:最大1024アクセラレータをサポート
UALinkの大きな特徴の一つは、そのスケーラビリティである。単一のUALink「ポッド」内で、最大1,024基のアクセラレータ(GPUやその他のAI特化型プロセッサ)を接続することが可能である。これは、専用の「UALinkスイッチ」を介して実現される。各アクセラレータはスイッチの1ポートに接続され、10ビットのユニークな識別子が割り当てられることで、正確なデータルーティングが行われる。
これは、NVIDIAが最新のBlackwellプラットフォーム(NVL72)で実現している1ラックあたり72 GPU、ポッドあたり最大576 GPUという規模を、少なくとも仕様上は大きく上回るものだ。将来的にNVIDIAがRubin世代で計画している規模(1ラック144 GPU、Rubin Ultraで576 GPU)と比較しても、UALinkの1024接続という目標は非常に大きい。
通信性能:200G/レーンと低遅延の両立
仕様名の「200G」が示す通り、UALinkは1レーンあたり200 GT/s(ギガトランスファー/秒)の双方向データ転送速度を目指す。これは、前方誤り訂正(FEC: Forward Error Correction)やエンコーディングのオーバーヘッドを考慮したシグナリングレートでは212.5 GT/sに相当する。UALinkはx1、x2、またはx4のレーン構成が可能で、x4構成では送受信それぞれ最大800 GT/sという広帯域幅を実現する。
帯域幅だけでなく、低遅延も重視されている。UALinkはメモリセマンティックな通信(リモートメモリをローカルメモリのように扱えるロード/ストア操作)をサポートし、プロトコルレベルでの最適化を図っている。ケーブル長はラック内接続を想定し4メートル未満に最適化されており、64バイトまたは640バイトのペイロード転送における往復遅延時間(Round-Trip Latency)は1マイクロ秒未満(< 1 µs)を目指す。これは、一般的なEthernetよりも大幅に低く、PCIeスイッチに匹敵するレベルであるとされる。
さらに、UALinkは決定論的なパフォーマンス(予測可能で安定した性能)を重視しており、1ラックから最大4ラックにまたがる構成でも安定した性能を発揮できるように設計されている。UALink Consortiumは、実効帯域幅(理論上の最大値ではなく、実際に利用可能な帯域幅)としてピーク帯域幅の93%を達成可能であるとしている。
消費電力に関しても、Ethernetネットワークと比較して3分の1から2分の1程度に抑えることを目標としており、高効率なスイッチ設計がこれを可能にするとしている。ダイエリア(半導体チップ上で回路が占める面積)も小さく抑えられるため、チップ自体のコストと消費電力削減にも寄与し、TCO削減に繋がる。
プロトコルスタック:ハードウェア最適化による高効率
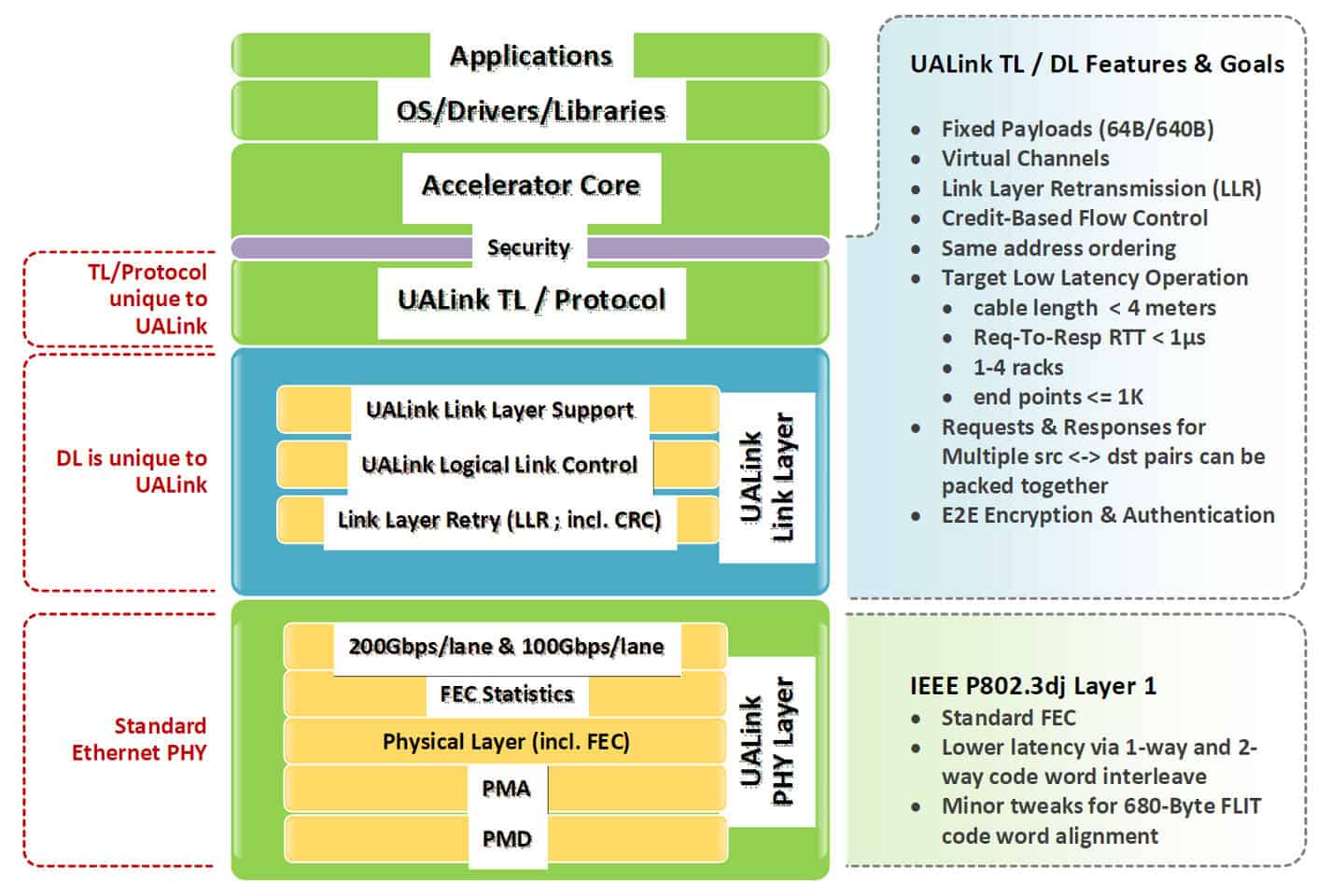
UALinkのプロトコルスタックは、性能を最大化するためにハードウェアレベルで最適化された4つのレイヤーで構成される。
- 物理層 (Physical Layer): 標準的なEthernetコンポーネント(例: 200GBASE-KR1/CR1 SerDes)を活用しつつ、低遅延を実現するためにFECに変更が加えられている。これにより、既存技術を流用しながら性能向上を図っている。AMDは自社の224Gbps SerDes技術がUALinkに活用されていることを表明している。
- データリンク層 (Data Link Layer): 上位のトランザクション層から渡される64バイトの「フリット(flit)」と呼ばれるデータ単位を、640バイトの大きなユニットにパッケージ化する。これにCRC(巡回冗長検査)による誤り検出を付加し、オプションで再送処理(リトライ)もサポートする。デバイス間のメッセージングや、UART(Universal Asynchronous Receiver/Transmitter)ライクなファームウェア通信もこの層で扱われる。
- トランザクション層 (Transaction Layer): 圧縮アドレッシング技術などを採用し、プロトコルオーバーヘッドを削減。実際のワークロード下で最大95%の高いプロトコル効率を実現するとしている。アクセラレータ間の直接メモリアクセス操作(Read, Write, Atomic)を可能にし、ローカルメモリとリモートメモリ間での操作順序を保証する。
- プロトコル層 (Protocol Layer): アプリケーションに近い上位のプロトコルを定義する。
このスタック設計は、AMDが自社のGPU接続技術として開発してきた「Infinity Fabric」の知見が大きく活かされていることが、UALink ConsortiumのBowman氏によって語られている。同時に、Intel、Google、Microsoftなど他のメンバー企業からのフィードバックも取り入れられているという。
セキュリティと管理機能:データセンター運用を見据えた設計
現代のデータセンターにおける要求に応えるため、UALink 1.0仕様にはセキュリティと管理機能も組み込まれている。
- UALinkSec: ハードウェアレベルでの通信暗号化と認証を提供する。これにより、物理的な盗聴や改ざんからデータを保護する。また、AMD SEV、Arm CCA、Intel TDXといったTrusted Execution Environment (TEE) と連携し、テナントごとに独立した機密コンピューティング環境の構築をサポートする。
- Virtual Pod: 単一の物理的なUALinkポッド内を、スイッチの設定によって論理的に複数の独立したグループ(仮想ポッド)に分割する機能。これにより、共有インフラストラクチャ上で複数のテナントやワークロードを安全かつ分離して実行できる(マルチテナント対応)。
- 管理性: UALinkポッドは、PCIeやEthernetなどの標準インターフェースを介して、専用の制御ソフトウェアやファームウェアエージェントによって管理される。REST APIを通じた完全な管理性、テレメトリ(稼働状況の監視)収集、ワークロード制御、障害分離などがサポートされる予定である。
これらの機能により、UALinkは大規模かつセキュアなAIインフラの構築・運用に適した技術となることを目指している。
なぜ今UALinkなのか? – 背景と市場への影響
UALink 200G 1.0仕様の公開は、AIインフラ市場に大きな変化をもたらす可能性がある。
Nvidia NVLinkとの比較:オープン性とコスト効率の優位性
現状、NVIDIAはその強力なGPU性能と、それを最大限に引き出すためのインターコネクト技術NVLinkによって、AIアクセラレータ市場で支配的な地位を築いている。NVLinkは世代を重ねるごとに帯域幅と機能を向上させてきたが、プロプライエタリ(独自仕様)であるため、ユーザーはNVIDIAのエコシステムにロックインされやすいという側面があった。
UALinkは、この状況に対して「オープンスタンダード」という明確な対抗軸を打ち出している。
| 特徴 | UALink 200G 1.0 (仕様) | NVIDIA NVLink (例: 第5世代, Blackwell) |
|---|---|---|
| 標準化 | オープンスタンダード | プロプライエタリ(NVIDIA独自) |
| 参加企業 | AMD, Intel, Google, MS, AWSなど多数 | Nvidia |
| レーンあたり速度 | 200 GT/s (双方向) | 100 GB/s (双方向, 200 GB/s相当?) ※ |
| 最大接続数 | 1,024 アクセラレータ | 576 GPU (NVLink Switch System経由) |
| エコシステム | マルチベンダーによる製品提供に期待 | NVIDIA中心のエコシステム |
| コスト | 低コスト化を指向(オープン性、競争原理) | 比較的高価とされる |
| メモリモデル | メモリセマンティック(ロード/ストア) | メモリセマンティック |
※ NVLinkのGB/s表記とUALinkのGT/s表記は直接比較が難しい場合があるが、UALinkはEthernetに近い技術をベースにしつつ低遅延化を図っている。
オープンであることにより、理論上はAMD製GPUとIntel製AIアクセラレータを同じUALinkファブリック上で接続することも可能になるかもしれない。これは、ユーザーにとってこれまでにない柔軟性をもたらす可能性がある。
主要企業の参画と期待:エコシステムの広がり
UALinkの成功は、仕様の優劣だけでなく、どれだけ多くの企業がこの規格を採用し、対応製品を市場に投入するかにかかっている。その点において、初期メンバーの顔ぶれは非常に心強い。
- AMD: Forrest Norrod氏(EVP, Data Center Solutions)は、「UALinkがエコシステム全体で幅広い支持を集め、迅速なイノベーションと多様なソリューションを可能にすることに興奮しています。将来の製品でこの標準を採用する予定です」とコメントしている。
- Intel: Mark Davis氏(Fellow, Chief AI Product and System Architect)は、「次世代AI製品に向けて、オープンで標準ベースのスケールアップインターコネクトであるUALink 1.0をサポート、貢献できることを誇りに思います」と述べている。
- HPE: Trish Damkroger氏(SVP & GM, HPC & AI Infrastructure Solutions)は、「UALink 200G 1.0仕様のリリースを歓迎します。これにより共通理解が深まり、モデルトレーニング、チューニング、推論に焦点を当てた、よりアクセスしやすいスーパーコンピューティングと大規模AIクラスターに繋がるでしょう」と期待を寄せている。
- その他: Astera Labs、Broadcom、Marvell、Synopsysといった接続技術やIPの専門企業も、自社のソリューションを通じてUALinkエコシステムの発展に貢献する意欲を示している。
これらの企業が実際にUALink対応のアクセラレータ、スイッチ、IPなどを開発・提供することで、オープンなエコシステムが現実のものとなる。
製品化への道のりと今後の展望
UALink 200G 1.0仕様は公開されたばかりであり、この仕様に準拠した実際のハードウェアが登場するにはまだ時間がかかる。UALink ConsortiumのBowman氏は、製品が市場に出回るまでには約18ヶ月かかるとの見通しを示している。ただし、これは通常よりも6ヶ月程度早いペースであるとも述べており、AMD Infinity Fabricという既存技術をベースにしたことが開発期間の短縮に繋がった可能性がある。だが、仕様が最終化されたことで、メンバー企業はチップのテープアウトに進むことができるだろう。
今後、HPE、Dell、LenovoといったサーバーベンダーがUALinkを採用したAIソリューションを提供することや、BroadcomやSynopsysなどがハイパースケーラー向けカスタムアクセラレータにUALinkを組み込むことが期待されている。
さらに、UALink Consortiumはすでに次のステップを見据えている。Ethernet技術が400Gへと移行していく流れを受け、UALinkの次期仕様(おそらく400G対応)の開発にも着手しているとのことだ。
UALink 200G 1.0仕様の発表は、AIインフラの未来に向けた重要な一歩である。オープンスタンダードがもたらす競争、革新、そして選択肢の多様化が、今後数年間でAIコンピューティングのランドスケープをどのように変えていくのか、注目していく必要があるだろう。
Sources
- UALink Consortium: UALink Consortium Releases the Ultra Accelerator Link 200G 1.0 Specification [PDF]
- The Register: UALink debuts its first AI interconnect spec – usable in just 18 short months
Meta Desctiption
UALink ConsortiumがAIアクセラレータ接続の新オープン標準「UALink 200G 1.0」仕様を発表。最大1024基接続、200G/レーン、低遅延を実現。Nvidia NVLinkに対抗し、AMD、Intel、Googleらが参画。

